计算机网络的边缘端
A. 应用层概念简述
1. Web 应用使用 HTTP 协议,该协议是无状态的,采用客户服务器模式,主要是客户从服务器拉取信息,报文分为请求报文与响应报文两种,分别拥有请求行与状态行,以及各自的首部行和实体体;cookie 由服务器发起,客户接收 cookie 号设置并在其报文中选择是否携带 cookie 号,以便于服务器标识用户;条件 GET 请求,用于缓存(代理)服务器对初始服务器的询问,初始服务器的响应报文中实体体为空,使得 Web 缓存在为用户提供了快和新的内容的同时,减少了不必要的信息传输。2. FTP 协议是有状态的,在一个 FTP 会话中,控制连接为持续的 TCP 连接,用于维护诸如远程目录树的当前位置等用户状态,数据连接为非持续的 TCP 连接,每传输一个文件就要新打开一个数据连接。3. 电子邮件提供异步的信息收发,其中的邮件服务器用于保存信息,用户代理则在任何方便的时候从自己的邮件服务器上读取信息,邮件服务器负责将邮件发送出去,或者接收一个邮件,邮件服务器之间使用 SMTP 协议完成这个任务,且一般不使用中间邮件服务器,SMTP 主要是一个推送协议,且要求报文使用 7 比特的 ASCII 编码。4. DNS 协议通常是由其他应用层协议使用的,诸如 HTTP、FTP 和 SMTP,用于将主机名映射为 IP 地址。
B. Python 套接字编程
1. 套接字 = IP 地址 + 端口号。网络层依赖 IP,实现从一台端系统到另一台端系统的分组传输;运输层的报文段携带端口号,实现应用层之间的交互;可见,套接字是位于边缘的端与网络核心的门窗。2. 应用程序员在套接字编程中,不改变 IP 地址,而是改变端口号,以对应某个特定的应用。服务器和客户各有一个套接字,客户的端口号可以由客户系统随机指定,服务器的端口号针对某个特定的应用 ,设置一个固定端口。3. 在 Python 套接字库中,SOCK_STREAM 和 SOCK_DGRAM 可以看作是,套接字类用工厂方法生成不同子类对象(TCP 或 UDP 套接字)所需要的参数。两个子类对象都属于套接字类,都使用 close 方法用以销毁自己,而服务器端都使用 bind 方法设置端口号。4. 两类套接字的区别在于:UDP 套接字使用带套接字参数的 sendto 和 recvfrom 收发内容,而 TCP 使用的是不带参数的 send 和 recv,表明自己有固定的通信对象;以及,TCP 特有的处理请求和建立连接的操作,客户端请求 connect,服务器监听 listen 请求,服务器接收 accept 请求。
- UDPClient.py
from socket import * serverName, serverPort = '192.168.0.109', 12000 # server's IP, port. # serverAddr = ('192.168.0.109', 12000) message = 'hi, server.' clientSocket = socket(AF_INET, SOCK_DGRAM) # client's socket: IPv4, UDP_Datagram. clientSocket.sendto(message.encode(), (serverName, serverPort)) message_recv, _ = clientSocket.recvfrom(2048) print(message_recv.decode()) clientSocket.close()
- UDPServer.py
from socket import * serverPort = 12000 serverSocket = socket(AF_INET, SOCK_DGRAM) # means IPv4, UDP_Datagram. port given by system. serverSocket.bind(('', serverPort)) # set port of server. while True: message, clientAddr = serverSocket.recvfrom(2048) serverSocket.sendto(message.decode().upper().encode(), clientAddr)
- TCPClient.py
from socket import * serverAddr = ('192.168.0.109', 12000) message = 'hi, server.' clientSocket = socket(AF_INET, SOCK_STREAM) # means IPv4, TCP_ByteStream. port given by system. clientSocket.connect(serverAddr) clientSocket.send(message.encode()) # not sendto message_recv = clientSocket.recv(1024) # not recvfrom print(message_recv.decode()) clientSocket.close()
- TCPServer.py
from socket import * serverPort = 12000 serverSocket = socket(AF_INET, SOCK_STREAM) # means IPv4, TCP_ByteStream. port given by system. serverSocket.bind(('', serverPort)) # set port of server. serverSocket.listen(1) while(True): connectedSocket, _ = serverSocket.accept() message_recv = connectedSocket.recv(1024) connectedSocket.send(message_recv.decode().upper().encode()) connectedSocket.close()
C. 可靠传输
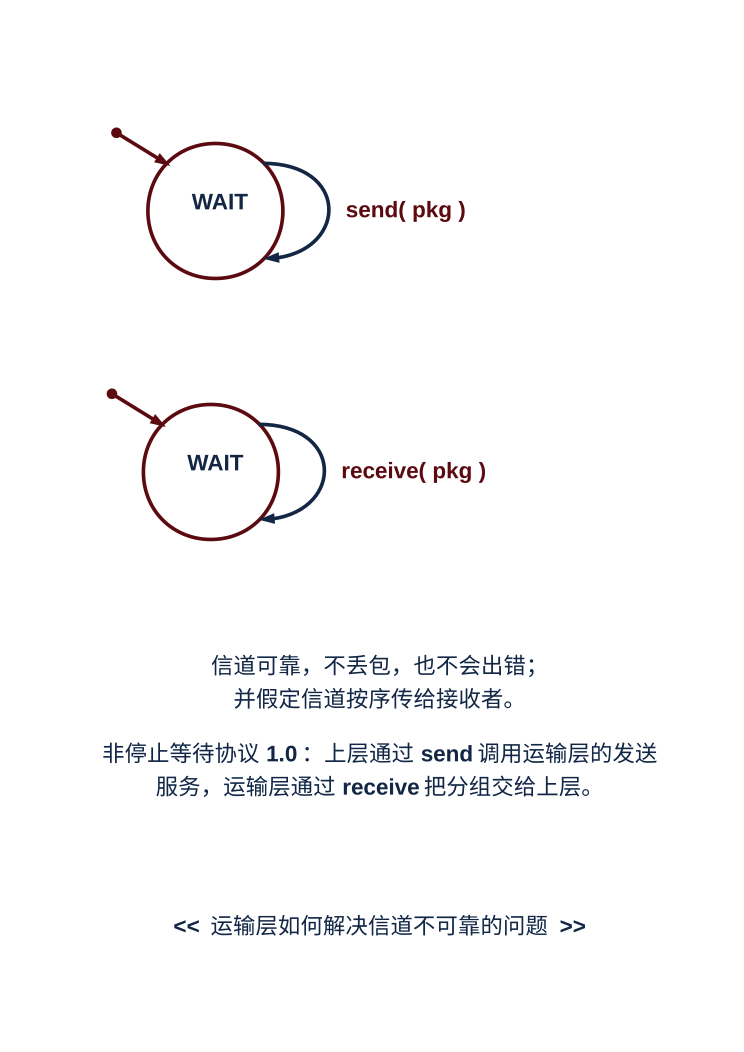
1. 非停等协议:为了向应用层提供可靠的通信,运输层(TCP)就要解决底层信道不可靠的问题,包括比特差错、丢包和时延等,为此,运输层引入一些机制。
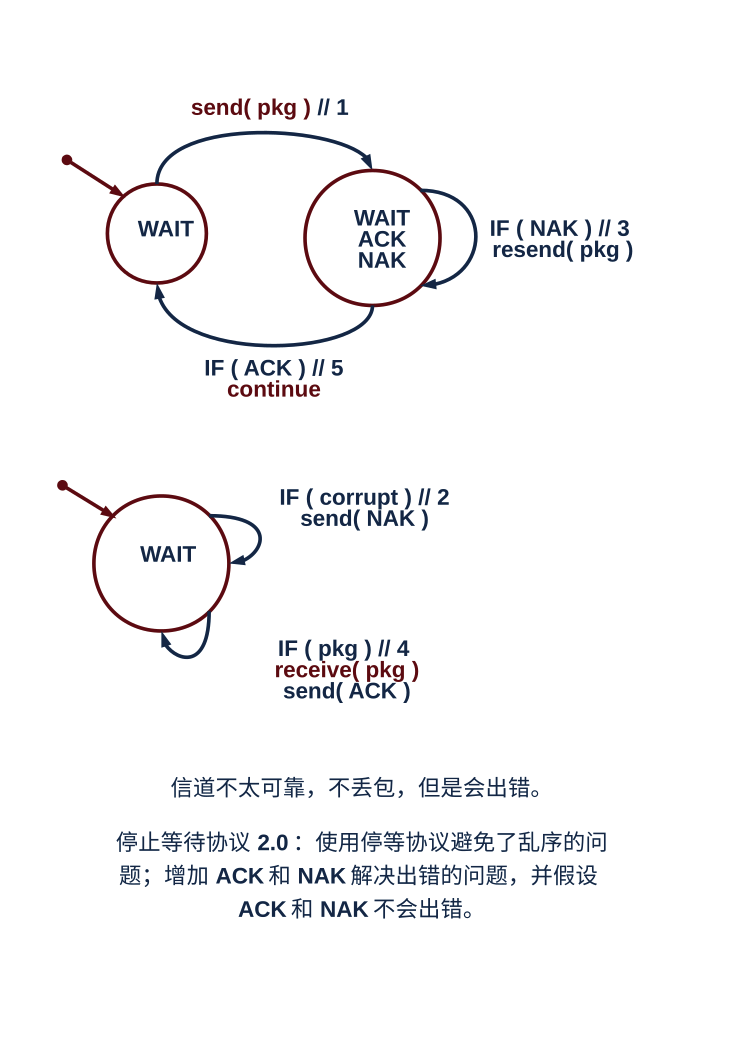
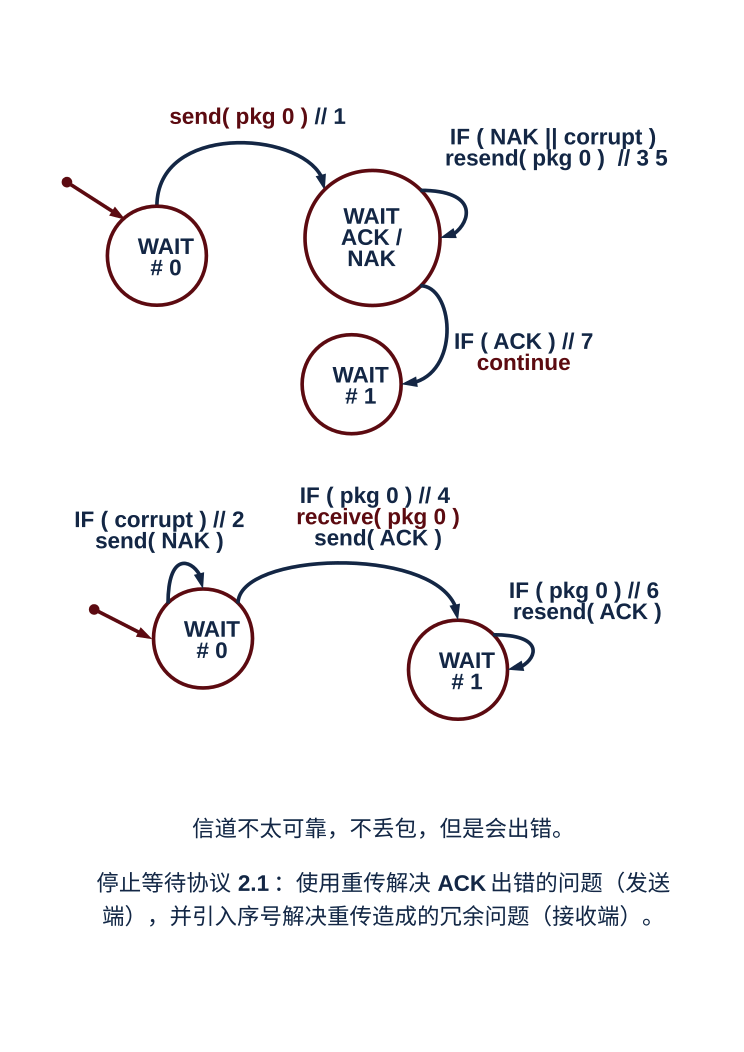
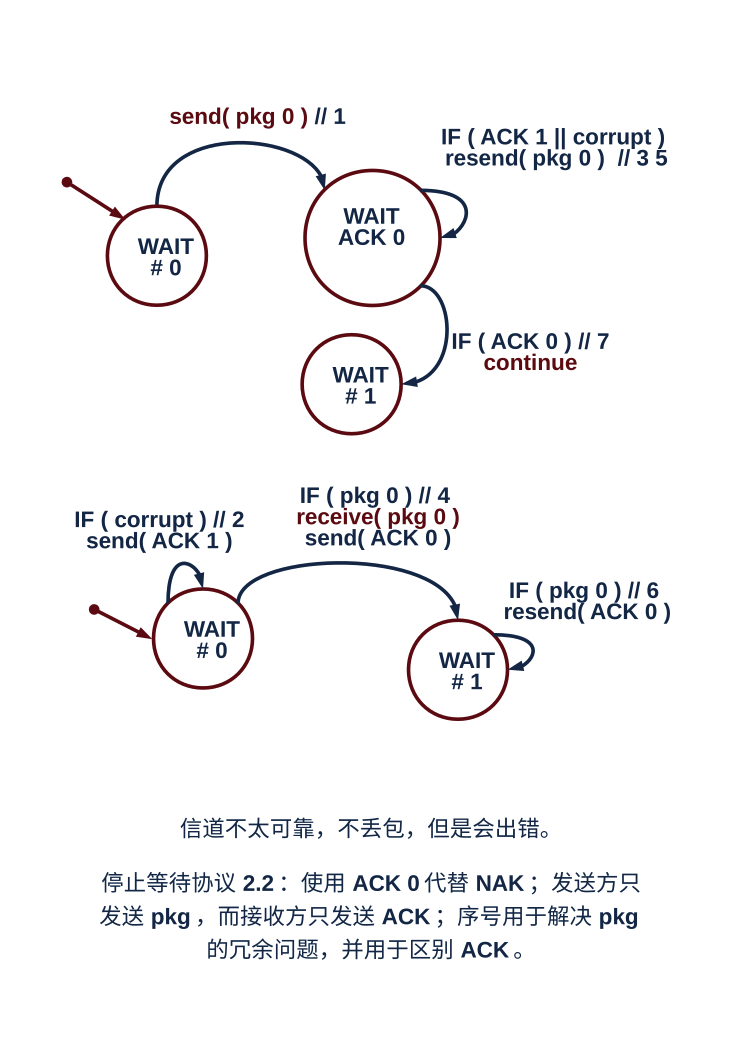
2. 停等协议:使用 ACK 确认报文,告知发送者已经收到正确的报文,使用 NAK 告知发送者收到了出错的报文,以此来解决报文比特差错的问题;这样,原来的非停止等待协议 1.0 就变成了停等协议 2.0,其关键的步骤是差错检测、反馈以及发送方重传;由于 ACK 确认报文和 NAK 报文也可能出错,所以原先的请求者在收到这样的错误报文时,一律重新发送请求,这就是一个冗余分组,而回应者需要辨别这是一个冗余分组,也就是对旧报文的请求,还是一个新的请求,为此,引进序号这种机制,就形成了停等协议 2.1 和 2.2,它们的区别是协议 2.2 中使用序号和 ACK 组合报文,代替原来的 NAK 报文。
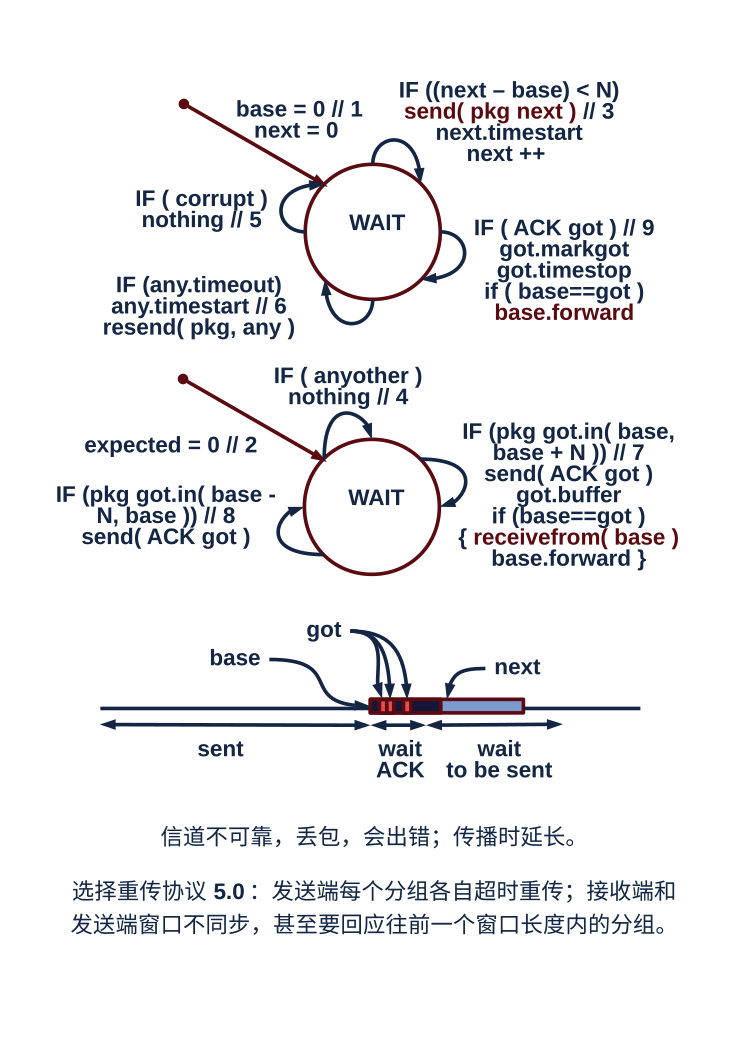
3. 交替比特协议:以上,还没有考虑的问题是丢包,引入一个计时器,到时重发即可,形成了停等协议 3.0,因为分组序号只有 0 和 1,又称为交替比特协议;

4. 滑动窗口协议:到此为此,已经得到一个可靠传输的协议,但是,因为要等待对方回应才能继续发送报文,所以,这是一个信道利用率很低的协议,为此引入流水线技术。可以采用两种基本方法:回退 N 步,或者是选择重传;在阅读两个方法的有穷状态机的时候,只要按照图中代码所注释的号码顺序,即可顺利理解事件发生和驱动的一系列必要或者可能的步骤,这些事件主要包括发送方所要处理的从上层收到数据、超时以及收到 ACK 报文三个事件;二者中,选择重传要比回退 N 步更复杂一些,区别在于,接收方看到的和发送方看到的窗口不一致,且接收方需要缓存接收到的分组直到收到窗口中的第一个分组的时候才一并将连续几个收到的分组交给上层并移动窗口,所有的计时器都在发送方,但是选择重传方法的发送方需要给每个分组单独一个计时器,而回退 N 步就只是一个简单的滑动窗口协议。