Change the Forwarding: RMT Architecture
Change the Forwarding: RMT Architecture
Note on "Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN", SIGCOMM 2013, Hong Kong, China.
前言
回顾SDN至今十年的发展,涌现了许多非常优秀的技术和应用,当下数据平面可编程是炙手可热的研究热点,代表性的就算Stanford University, Nick Mckeown教授等人提出的P4语言了。追根溯源,P4语言的出现离不开2013年SIGCOMM的这篇"Forwarding Metamorphosis"长文了,现在看来该文提出的RMT模型确实是带来了一场变革。
本文作者分别来自德州仪器(Texas Instruments)、斯坦福大学(Stanford University)以及微软研究院(Microsoft Research)。
本文由以下几个部分组成:Abstract、Introduction、RMT Architecture、Example Use Cases、Chip Design、Evaluation、Related Works以及Conclusion。
Forwarding Metamorphosis, 转发质变
"To improve is to change, to be perfect is to change often."
论文开篇就引用这句Churchill的名言,开门见山地引出本文的意图,想提升就必须不断地改变;它的核心思想,也是SDN的本质 - 可编程性。
计算机领域中蕴含着许多编程抽象的思想,比如虚拟内存,这些抽象允许系统不断地变化,同时简化了上层的编程工作。计算机网络的成功离不开编程抽象:TCP将端到端的连接进行了抽象,IP提供了终端到网络边缘、简单的datagram抽象。但是网络中的路由和转发仍然遗留有路由协议、转发行为的困难,网络设备控制和转发平面紧耦,形成了一个个黑盒子。SDN通过转控分离,在控制平面和数据平面之间插入开放接口(eg.OpenFlow)向抽象网络功能迈出了关键一步。大家都很熟悉的南向OpenFlow将底层交换机的行为抽象为"Match-Action",通过其开放可编程的特性支持用户灵活按需制定网络行为,提升了网络整体的可编程性。
有人想在通用的CPU上实现Match-Action,但是基于速度方面的考虑,我们采用专用的硬件实现并行转发,专用交换机的芯片比CPU快两个数量级,比NPU快一个数量级,并且这个趋势看上去是无法改变的。因此,我们思考:在流表内存受限的情况下,如何在硬件上实现Match-Action,并充分利用流水技术和并行思想(以提升速度)?
在可编程性和速度之间有着天然的tradeoff。如今,频繁支持新的网络功能需要不断对硬件进行改动。如果Match-Action硬件在字段方面支持足够的可重配置能力,那么在运行时就能够支持新类型的数据报处理过程,就能够改变我们对于如何编程网络的看法。关键在于,能不能在不影响转发速度的情况下,使硬件支持足够灵活的可编程性?
接着论文列举了三种不同的处理模型,分别是SMT(Single Match Table)、MMT(Multiple Match Tables)以及本文提出的RMT(Reconfigurable Match Tables)。
SMT是最简单的转发模型,对于编程人员和生产人员来说是相对简单轻松的,一个原因是SMT只有一张流表,另一个原因是SMT使用一个较宽的TCAM实现。但是相比于其它的转发模型,SMT有着最为严格的约束,因为经常要在1Tb/s的转发速率下进行操作。SMT的缺点在于它开销太大了,需要存储每一种可能的首部组合。
MMT是SMT天然的改进,允许多张小的匹配流表与数据报的字段子集相匹配,流水线的处理架构分为不同的阶段,阶段j的匹配流表会受到阶段i的影响(i<j),MMT的每一个阶段通过有限的流表是很轻松就能实现的。MMT模型很接近如今交换机芯片结合流水的实现方法。
OpenFlow没有对处理模型流水阶段的数目、流表张数、宽度深度、大小做固定的要求,允许不同的厂家做出不同的产品,但为用户保留了定义匹配新字段的灵活性。但是,现有的芯片在制作的时候,流表的数目、格式,匹配的顺序都是写死固化的,芯片的灵活性和可编程性是十分受限的。根据特定用户场景设计专用芯片的做法是十分低效的,因此目前商用的交换机芯片尝试支持用户案例的超集,也就是说支持大部分的用户需求,但是这样子引入了新的问题,当网络的管理者想要改变流表的大小来操作他们的网络,或者在现有标准之外实现新的转发行为时,采用MMT模型会带来许多的问题。
另一个问题就是现有的交换机芯片只提供了非常受限的常规动作集,这个动作集拓展性很差,并且并不是那么抽象。更加抽象的动作集允许修改任意的数据报字段、更新任意的状态机,并将数据报转发到任意的端口。
RMT(Reconfigurable Match Tables) 因此在本文中,对MMT模型进行了改进,将改进后的模型称为RMT。类似于MMT,理想的RMT模型支持流水阶段的集合,每一个流水阶段都有一张宽度、深度不受限的流表。RMT从以下四个方面改进了MMT模型,并支持数据平面的可重配置:
- 1.支持修改字段的定义,增加新的字段;
- 2.匹配流表的数目、逻辑格式、宽度和深度可以灵活变化;
- 3.支持新动作的定义;
- 4.修改之后的数据报可以放置在特定的队列,输出到指定的端口。
新的网络协议出现时,总会定义新的协议字段,基于MMT的交换机芯片一旦出厂就只能支持固定的协议,具有协议相关性。RMT通过从芯片的转发模型支持可重配置,能够解决现有的交换机芯片协议相关性问题,在无需改动交换机硬件的前提下提升了可编程能力。此外,RMT模型也完美兼容OpenFlow协议。
直观上来看,在Tb的速度情况下支持任意的可重配置性是一件看上去不大可能的事情,但这是受什么因素限制呢?受限的可重配置性是否覆盖了足够充分的需求?有人能通过做芯片具体化了这些想法,证明了可行性吗?相比于MMT,RMT有多贵?这些是这篇论文指出的几个主要问题。
通用的payload处理并不是RMT的目标,SDN/OpenFlow以及RMT致力于识别由元动作组成的最小集(minimal set of primitives)来处理数据报首部。这个集合就像是网络中的RISC,为高度流水化的硬件设计的。RMT的设计相比于固化的设计而言,极大提升灵活性的同时,也几乎不带来额外的损耗(flexibility comes at almost no cost)。
本篇论文的贡献有以下几点:
- 设计并实现了RMT架构;
- 给出了两个典型的用户案例;
- 芯片的设计和损耗测试。
芯片层面的RMT模型通过可重配置的流水引领了可编程数据平面的硬件设计,在不损耗性能的情况下支持任意配置的灵活性,从而提升了整网层面的可编程性,在当时是非常innovative的实现。
接着来看RMT的架构,原文描述如下:"allow(ing) a set of pipeline stages … each with a match table of arbitrary depth and width that matches on fields." RMT的大体框架是由可重配置的parser解析器和许多的匹配阶段组成的多流水并行架构,如图所示:
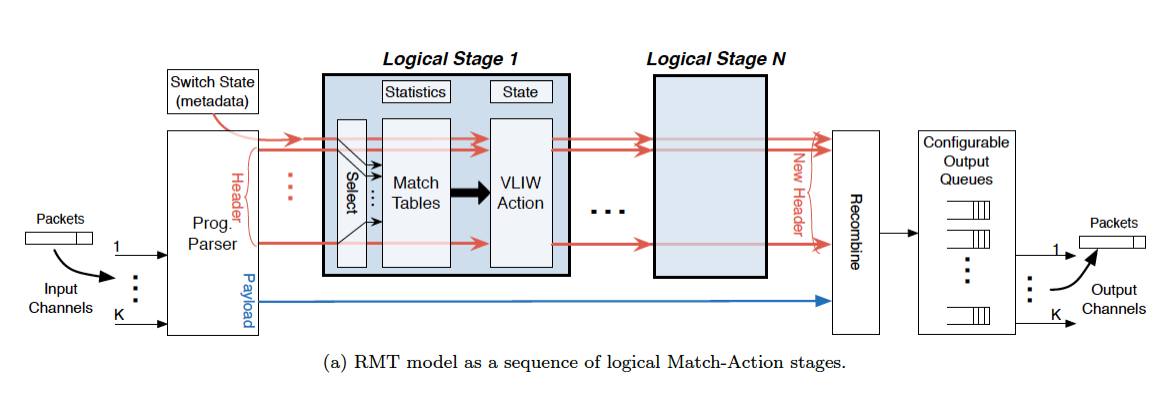
架构细节:
- parser必须允许字段的定义被修改或者增加新的字段;
- parser的输出是一个数据报首部的向量vector,实质上是数据报首部的集合,比如IP首部等,除此之外也包括了metadata元数据,存储着一些关键的数据报状态信息,比如入端口等。
- 每一个匹配阶段允许匹配流表的大小是可配置的;
- 使用一个广泛的指令(VLIW, very long instruction word, 超长指令字)进行数据报的修改操作,支持对数据报首部集中任意字段的修改;
- 流控制(control flow)是通过一种额外的输出,即下一张流表的地址实现的,在每一张流表匹配结束之后会基于匹配结果提供下一张执行流表的地址索引index。
总结:理想的RMT架构使parser对新加入、修改的字段进行解析;通过修改匹配的内存匹配新增加的字段;通过修改阶段指令集来创建新动作;通过修改队列规则来支持新的队列机制。理想的RMT模型能够模拟任意的设备,比如交换机、路由器等等,更重要的是,RMT模型支持在不修改硬件的前提下,对数据平面进行修改。
为了让读者对如何使用RMT芯片有直观的感受,论文介绍了两个use cases,第一个example是典型的L2/L3 switch,第二个是使用状态化组件的RCP和ACL。主要是介绍两个例子下RMT模型的逻辑以及内存的分配:1.Parse Graph, 2.Table Flow Graph, 3.Memory Allocation。
芯片设计方面,论文围绕以下几个方面进行探讨:
- 配置解析器;
- 配置匹配流表的内存;
- 配置动作引擎(VLIW);
- 其他的特征(如多播、ECMP、状态化组件等)。
这里不再对细节进行展开。
论文的实验验证部分分别针对导致RMT模型中parser、match stages以及actions三个方面主要开销的原因进行了分析,并在最后一节从芯片占用的空间、额外的性能损耗(如I/O等)进行了比较,得到了令人振奋的消息:在支持高度可重配置能力的情况下,RMT模型的损耗非常小,是完全可以接受的。
总结:解决不断变化的用户需求需要足够的可编程性,来支撑网络软件的更新、增加新的网络功能和协议。RMT模型的出现为我们提供了一种强有力的途径,在保证Tb级别转发能力的前提下,将网络编程人员想要的转发行为部署到可重配置的底层设备,提升了设备的可编程性和灵活性,以应对不断变化的用户需求,加速网络创新进程。"To improve is to change, to be perfect is to change often." 很显然,RMT模型还不够完美,还有一些限制,但是能够看到的是,数据平面的转发正在发生质变。
2017.8

