The P4 Language Specification v1.0.2 Header and Fields
前言
本文参考P4.org网站给出的《The P4 Language Specification v1.0.2》的第二部分首部及字段,仅供学习:)。
欢迎交流!
Header and Fields
目录
(1)首部类型,Header Type
(2)首部实例(Header instances 和 Metadata instances)
- 检查实例是否合法(valid)
- Header Stacks
(3)Headers and Fields 索引指针(References)
(4)Fields List
2.1 Header Type Declarations 首部类型声明
首部类型(Header types)描述了字段(fields)的结构(layout),同时也提供了用于索引的名称信息(相当于引用字段的指针)。
首部类型 用于声明两种首部实例:包头实例(header instances) 和 元数据实例(Metadata instances),将在下节进行讨论。
具体参照下图的巴科斯范式BNF(图自 版本1.0.2说明):


首部类型的定义遵循如下规则:
(1)fields attribute 首部类型必须有一个字段域属性(fields attribute):
- The list of individual fileds is ordered.要求有一个个体字段的列表。
- Fields默认是无符号的,以及具有非饱和性(non-saturating)。(原文注:对该属性列表的添加或者删除操作导致的上溢或者下溢情况,会使用wrap的方法解决。i.e, addition/subtraction causing overflow/underflow will wrap.)
- The bit offset of a field from the start of the header is determined by the sum of the widths of the fields preceding it in the list. 首部的初始部分,字段域的偏移字节取决于字段域的所有字段宽度之和。
- Bytes are ordered sequentially(连续的)(from the packet ordering).
- Bits are ordered within bytes by most-significant-bit first. Thus, if the first field listed in a header has a bit width of 1, it is the high order bit of the first byte in that header.字节里的比特是根据重要意义排序的,因此,如果首部定义的字段域中,第一个字段的宽度为1比特,那么它就是该首部定义的第一个字节(byte)的具有特殊意义的比特(bit)。
- All bits in the header must be allocated to(分配给) some field.
- One field at most within a header type may specify a width of
*which indicates it is of variable length.在首部类型定义中,一个字段域最多只能有一个字段的宽度是用“*”标识的,即该字段的宽度可变。
(2)fixed-length & variable length 固定长度(定长)首部 & 可变长度(不定长)首部:
如果所有字段的宽度都定义为固定的值(或者说,没有一个字段的宽度被声明为“*”),那么我们称这个首部是定长的(fixed length);否则称这个首部是不定长的(variable length)。
(3)length attribute 长度属性
The length attribute specifies an expression whose evaluation gives the length of the header in bytes for variable length headers.
长度属性,明确说明了一种表达形式,该表达形式的赋值 使得按字节计数的首部长度 为不定长形式。
- It must be present if the header has variable length (some field has width "*").如果首部有不定长的字段,那么首部定义必须给出长度属性。
- A compiler warning must be generated if it is present for a fixed length header.如果定长首部声明了长度属性,那么编译器必须给出警告。
- Fields referenced in the length attribute must be located before the variable length field.不定长的字段必须声明于字段域的最后。
(4)max_length attribute 长度上限属性
The max_length attribute indicates the maximum allowed length of the header in bytes for a variable length header.对于不定长的首部而言,长度上限属性指明了按字节计数的首部长度上限。
- If, at run time, the calculated length exceeds this value, it is considered a parser exception. See Section 4.6.运行时,如果计算的首部总长超过了该属性值,那么作为 parser exception解析异常 处理。
- The max_length attribute may be present if the header is variable length.对于不定长首部而言,长度上限属性可以被声明。
- A compiler warning must be generated if it is present for a fixed length header.但是对于定长首部而言,如果给出该属性,那么编译器必须给出警告。
(5)Operator precedence and associativity 操作符优先级和可结合性
Operator precedence and associativity follows C programming conventions. 操作符优先级和可结合性与C语言语法一致。
不定长字段计算方法 及 首部定义的例子
请留意:1 byte = 8 bit
P4通过对值为“”的字段的使用,来支持从数据报中解析出不定长的首部实例。
该值为“”的字段的宽度,可以通过由长度属性说明的,按字节(bytes)计数的首部总长(the total header length)推出。
公式如下:
该字段宽度 = ((8 * length) - sum-of-fixed-width-fileds) = (8 * 总长 - 其它定长字段宽度的总和) (单位:bit)
注意,字段域中的字段宽度单位是 bit,而首部总长(长度属性)的单位是 bytes。计算特定字段的宽度值的时候,需要进行单位的换算,即 1 byte = 8 bits。
一个VLAN header类型定义的实例,以及metadata类型的定义(语义相似):

2.2 Header and Metadata Instances 包头实例 及 元数据实例
当P4程序中定义了一种首部的类型,那么映射到底层解析过程,解析状态函数根据首部类型的定义,有可能在数据报中发现很多首部实例(header instances)。
P4要求每一个首部实例在被引用之前,都应该被明确的定义,即实例化。
有两种首部实例:包头实例(packet header)和元数据实例(metadata)。通常而言,数据包在抵达Match-Action的Ingress过程时,数据包包头信息会被确认;与此同时,元数据Metadata携带一些特别的数据包信息,这种信息并不经常在数据包数据字段出现,比如ingress端口和时间标志。
关于元数据:在处理数据包的时候,大多数元数据只是简单的数据包状态(per-packet state)信息,比如寄存器。但是,有一些元数据会影响交换过程中的操作(the operation of switch),比如队列系统(the queuing system)会根据元数据的字段值,为数据包选择合适的队列。P4承认这些具有特定目的和含义的元数据,但是并没有尝试去用语言表示它(原文:P4 acknowledges these target specific semantics, but does not attempt to represent them.)
由关键词header定义的包头实例,和由关键词metadata定义的元数据实例,它们之间的区别,仅(differ only)在于合法性(validity)。(注:后面的章节有提到,区别在于validity合法性和deparsing逆解析过程,应该是两个方面)
包头实例会带有特定的独立标记,用于测试其是否合法;而metadata,一般都认为它合法。
在2.2.1中,会详细的介绍这一性质。
元数据实例的字段值,如果没有定义的话,默认初始化为0。
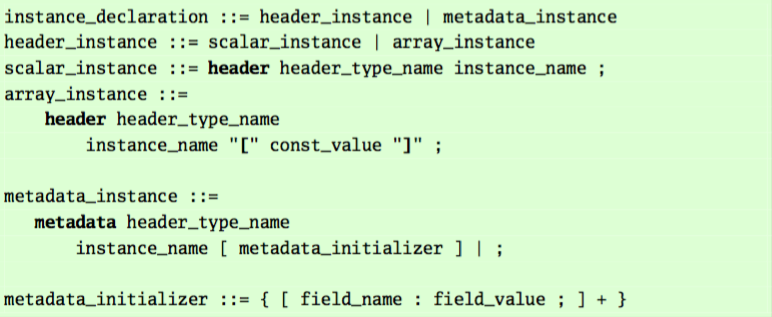
包头实例 和 元数据实例 的巴科斯范式BNF如下:
一些注意点:
- 只有包头实例(由关键词header定义)才可能形成数组(arrays)。元数据实例不行。
- header_type_name 必须是已定义的首部类型的名字。
- 元数据实例可能不会被声明为不定长类型实例。(原文:Metadata instances may not be declared with variable length header types.)
- 初始化的时候所用到的字段名称,必须要在首部类型定义中的字段域中找的到。(原文:The fields named in the initializer must be from the header type’s fields list.)
- 如果指定了一个初始化容器(initializer),那么在这个容器中,被指定字段就被初始化为指定的值,没有被指定的字段值初始化为0.
- 对于一个包头实例来说,如果它所有的字段总长不是整数倍的单位字节(an integral number of bytes),编译器必须报错。The compiler may pad the header to be byte aligned.
关于包头实例的定义,举个例子:
header vlan_t inner_vlan_tag;
下面这段关于上面代码的解读是比较重要的,它将和后面的parser模块的内容结合起来:
原文:This indicates that space should be allocated in the Parsed Representation of the packet for a vlan_t header. It may be referenced during parsing and match+action by the name inner_vlan_tag.
关于Parsed Representation,译为解析表达,将在后面的parser部分提及。
上面这段话的大意是:header vlan_t inner_vlan_tag;这句在P4代码中定义包头实例的语句,指明了在实际处理这条语句的过程中,要给从数据包中解析出来的 名为vlan_t的首部类型 实例化的 包头实例分配资源,成为解析表达的一部分。这个包头实例有可能在后面的match-action过程中被引用,方法是引用它的名字inner_vlan_tag(相当于指向该包头实例的指针)。
关于元数据的定义:
metadata local_metadata_t local_metadata;
这条语句指明了 名为local_metadata_t元数据类型 的实例对象local_metadata,类似上面的header语句的说明,将会在match-action的时候以 引用它的名字的方法 引用该实例。
注:实际上,从数据包中解析出来的metadata实例,也是解析表达的一部分。
2.2.1 Testing if Header and Metadata Instances are Valid 测试包头实例和元数据实例是否具有合法性
数据包中的首部实例以及它的字段们可能会被检查是否是合法的(valid)(是否有一个定义的值 having a defined value),合法性和逆解析过程是仅有的两个区分包头实例和元数据实例的方法。
由关键词header声明的包头实例有以下情况是合法的:
- 在解析过程中被extract函数调用。
- 在match+action过程中被操作(这个操作是 add 或者是 copy)。
如果首部实例合法,在首部实例中的字段也合法。
元数据实例中的字段总是(always)合法的,因为一般来说它的字段的值是明确定义的。
如果要检查元数据实例的合法性,编译器需要生成警告,并且测试的结果应该评价为True(should evaluate to True)。
Explanation说明:
原因可以通过一个“flag”的测试样例来具体说明;举个栗子,假设一个一比特的元数据flag是用来指明一个数据包拥有某些属性的(这是说,比如我这个包是ip包,那么这个flag指明是v4还是v6的,也就是说指明了版本号);flag值为0和这个flag不合法是等同的。
类似的,很多“index”(索引标志)元数据字段都能给出一个备用值(reserved value)来指明字段是不合法的(用来增加对 元数据字段初始化值 的支持)。在元数据字段中有一个独立合法的比特有时会很有用,定义一个独立的元数据flag来表示字段的合法性是一项有原因有意义的做法。
虽然一个match匹配操作可能会检查首部实例(或者字段)是否合法,但是只有合法的首部字段才可能用于匹配(当字段的值是为精确匹配或者三元匹配而指明的时候)。
只有合法的数据包首部实例才考虑逆解析deparsing。
2.2.2 Header Stacks
P4支持 header stack 的概念,它是一种邻近的,相同类型的首部实例的序列。
MPLS和VLAN标签就是这方面的例子。Header stacks 声明和数组一样,使用了在章节2.2中有提到的 array_instance 关键词分句。
header stack 实例 会被使用括号符号的方法(using bracket notation) 引用(referenced),这样的引用方法等同于对非栈式(non-stack)实例的引用方法。解析器parser保持某些信息来管理header stack。
2.3 Header and Field References
对于匹配,动作以及流控制规格要求(control flow specifications)而言,我们需要与首部实例还有它们的字段建立索引关系(make references)。首部实例可以通过它们的名字来被引用,对于header stack而言,索引值(index)(可以是一个常量)是在括号符号(bracket notation)中说明的。
index:返回表或区域中的值或对值的引用。

为了索引到一个特定的首部字段,我们使用了下标点符号(dotted notation: .)。关键词last相当于header stack中的最大索引值(largest-index),能够利用它来索引得到header stack中的最后一个合法实例。

举个栗子,
inner_vlan_tag.vid,就是说引用一个首部实例inner_vlan_tag中的vid字段,这种做法和C++中引用类的成员做法一致。
- 在字段域内必须有这个字段的名字,就是说,在用于inner_vlan_tag实例的首部类型的字段域中,必须有一个叫做vid的字段。
- 对一个字段的引用 和 该字段所属的首部实例(以及 定义的首部类型) 有着密切的关系。允许在不同的首部类型定义中,声明同名的字段。
- 对于任何时候的首部实例,它可能是合法的,可能是非法的,这种状态可能在match+action过程中进行测试。
- 运行时(run time),对于一个非法首部实例(或者是它的一个非法字段)的引用,它将会返回一个特殊的未定义(special "undefined")的值,这个值的含义取决于程序的内容。
2.4 Field Lists
在某些情况下,用P4语言描述出一个字段序列会使事情变得更加方便,比如一个哈希函数,它可能想把这个字段序列作为函数的输入,再比如你会根据字段序列来计算检验和(checksum)。
P4语言允许对字段列表的定义,在这个列表中的每一个表项,可能是一个首部实例中的某一字段的索引,可能是一个首部实例(和 按字段域中的顺序 列出该实例的所有字段 的效果一致),也可能是一个固定的值。
数据包的包头实例和元数据实例可能会在一个字段列表中被引用。
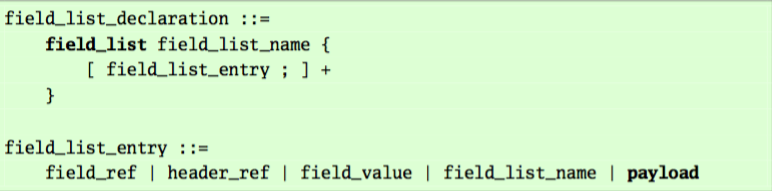
一个字段列表可能会引用到其他的字段列表。因此,字段列表的名字和首部实例的名字都应处于同一个命名空间下。
P4不支持字段列表的递归调用。
identifier 标识符,指明在字段列表中声明的字段 所属位于数据包中的首部实例部分 之后的数据包内容,也包括在数据包中。这样做的目的是为了支持特定的情况,比如计算以太网CRC冗余码,或者是TCP的检验和。
原文:The identifier payload indicates that the contents of the packet following the header of the previously mentioned field is included in the field list. This is to support spe- cial cases like the calculation of an Ethernet CRC across the entire packet or the TCP checksum.
2016/10/5

