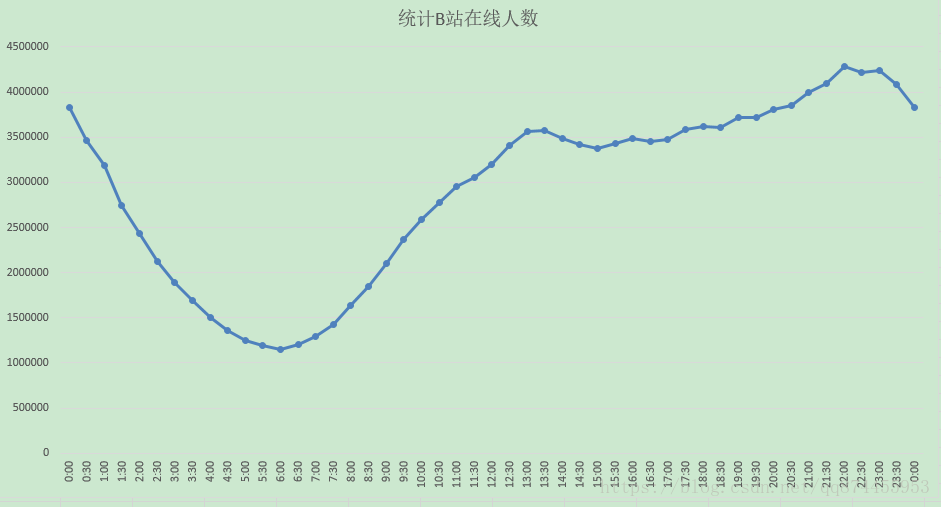
用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下
设计思路
首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或者直接正则表达式)得到数据, 然后把数据和当且时间保存到本地,并且设置一定的时间间隔,反复得到数据, 不过后面我发现B站在线人数是通过js动态生成的,后面会提到
实现过程
观察HTML网页
打开B站,查看网页源代码

我们发现
<div class="online">
<a href="//www.bilibili.com/video/online.html" target="_blank" title="在线观看:4285260">
在线人数:3277944
</a>
<a href="//www.bilibili.com/newlist.html" target="_blank">
最新投稿:32678
</a>
</div>在线人数是存储在类名为online的div中的a标签,当得到a标签的内容,然后把数字分割出来就可以
提取信息
提取代码片段如下:
url = "https://www.bilibili.com/"
html = get_page_source(url)
#得到网页的string
soup = BeautifulSoup(html, 'html.parser')
viewInfo = soup.find_all('div', attrs={'class': 'online'})[0]
#找到相应div
numberStr = viewInfo.a.string
#提取标签a的内容
number = str(numberStr.split(':')[1])
#把得到的字符串按照":"来分割所以数字就分到标为1的位置 提取出来就可以然后发现 我们每次得到的number都为0,这显然是有问题的。
问题的关键在于B站在线人数的数据是动态生成的,这是一个动态的网页,这个数字是通过js代码填进去的,所以我们每次得到的是没经过js处理的HTML,所以需要另外的解决方法
解决问题
这里我们在network里查找关键词online可以找到相应的的api
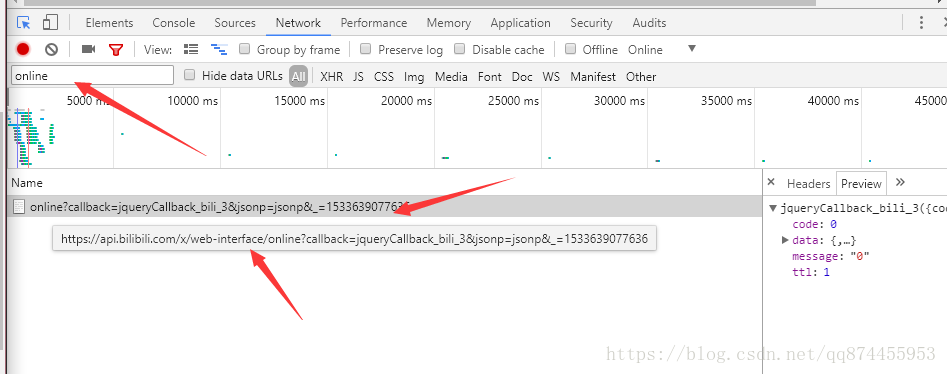
https://api.bilibili.com/x/web-interface/online?callback=jqueryCallback_bili_3&jsonp=jsonp&_=1533639077636
但是打开网址是找不到的, 主要因为我的url是有问题的 把后面的参数去掉就可以访问
得到最后的api网址
https://api.bilibili.com/x/web-interface/online
所以后面我们只需要用python解析json, 得到web_online的值就可以了
代码片段如下
url = "https://api.bilibili.com/x/web-interface/online"
html = get_page_source(url)
#获得url的
json_data = json.loads(html)
#解析json
number = (json_data['data']['web_online'])
#得到值把结果写到txt 以做研究
把当前时间 和 在线人数写到一起,以做研究
with open(fpath, 'a', encoding='utf-8') as f:
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
f.write(nowTime + " " + str(number) + '\n')全部代码
import requests
import re
import time
import datetime
from bs4 import BeautifulSoup
import traceback
import json
def get_page_source(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "failed"
def getViewInfo(url, fpath):
html = get_page_source(url)
try:
# soup = BeautifulSoup(html, 'html.parser')
# viewInfo = soup.find_all('div', attrs={'class': 'online'})[0]
# viewInfo = soup.find_all('div', attrs={'class':'ebox'})[0]
# title = viewInfo.p.string
# print(title)
# numberStr = viewInfo.a.string
# number = numberStr.split(':')[1]
#print(number)
#使用python来解析json
json_data = json.loads(html)
number = (json_data['data']['web_online'])
#保存文件
with open(fpath, 'a', encoding='utf-8') as f:
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
f.write(nowTime + " " + str(number) + '\n')
except:
traceback.print_exc()
def main():
count = 0
while 1:
url = "https://api.bilibili.com/x/web-interface/online"
#文件路径
output_path = "G://bilibiliInfo.txt"
getViewInfo(url, output_path)
#打印进度
count = count + 1
print(count)
#延时一分钟
time.sleep(60)
if __name__=="__main__":
main()
小结
最终可以把此程序 放到服务器上(毕竟电脑也不能总是开着的)
当然在服务器 实现定时运行可以通过crontab 来实现,然后把代码的循环改一下,就能实时监控了!
关于如何在服务器定时运行python可以看这篇博客,还是减少了很多错误的
https://blog.csdn.net/qq874455953/article/details/81586508
这是每隔30分钟的结果部分显示, 仅供参考
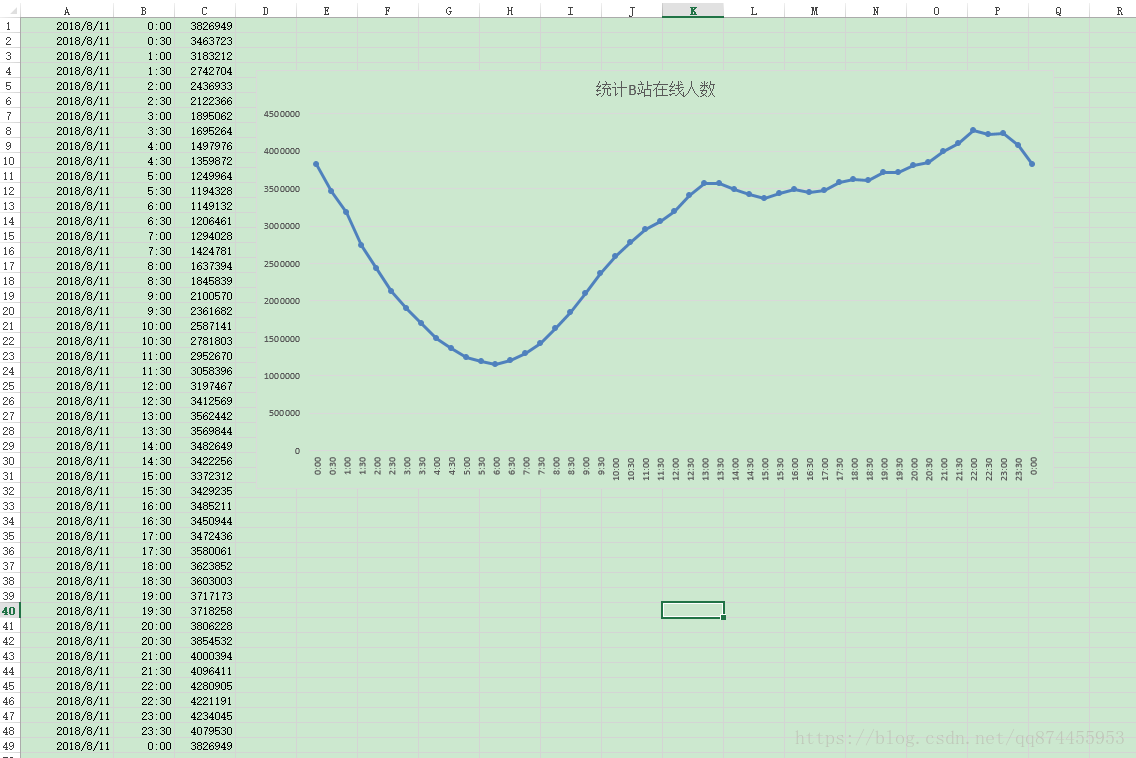
折线图