


用python爬虫监控CSDN博客阅读量
作为一个博客新人,对自己博客的访问量也是很在意的,刚好在学python爬虫,所以正好利用一下,写一个python程序来监控博客文章访问量
效果
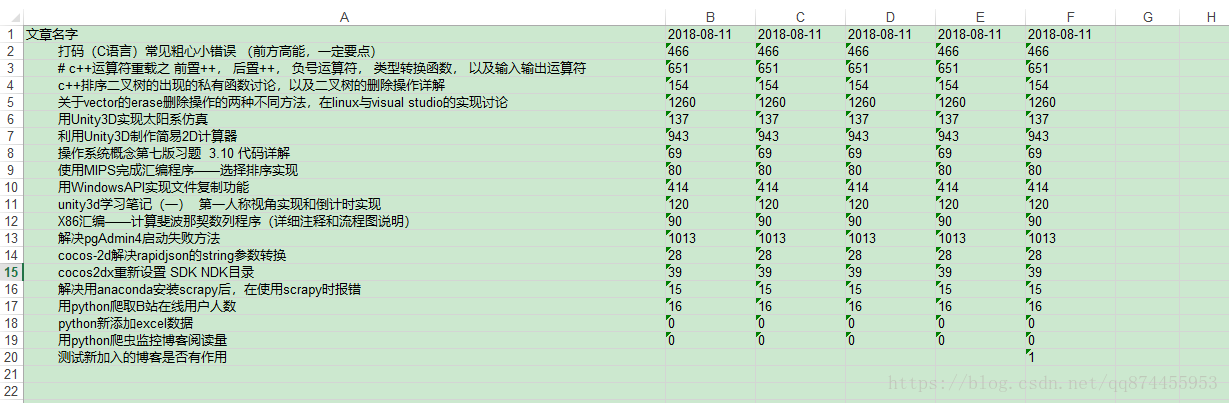
代码会自动爬取文章列表,并且获取标题和访问量,写入excel,并且对新加入的文章也有作用
解析HTML
html通过beautifulsoup来解析,由于是静态的网页,数据直接在网页中,而不是生成的,所以直接提取出来就可以
提取文章标题和访问量
通过观察HTML 我们发现每一个文章都存储在一个类名为‘article-item-box csdn-tracking-statistics’的div中, 所以找到类名为这个的div
发现文章标题藏在此div的h4下的a下,所以提取出来即可
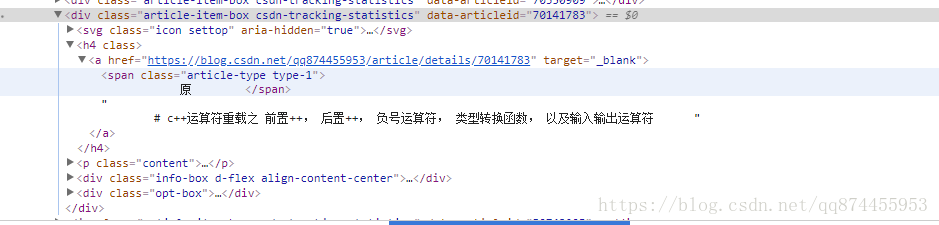
提取代码如下
articleList = soup.find_all('div', attrs={'class': 'article-item-box csdn-tracking-statistics'})
readBar = soup.find_all('div', attrs={'class': 'info-box d-flex align-content-center'})
articleListLen = len(articleList)
#把数据写入到表格里
for i in range(articleListLen):
articleName = articleList[i].h4.a.contents[2]
articleReadCount = readBar[i].contents[3].span.string.split(":")[1]
存储信息格式
存储信息通过一个表格来存储,结构如下
| 标题 | 日期1 | 日期2 | ··· |
|---|---|---|---|
| 文章1 | 访问量1 | 访问量2 | ··· |
| 文章2 | 访问量1 | 访问量2 | ··· |
| 文章3 | 访问量1 | 访问量2 | ··· |
| 文章4 | 访问量1 | 访问量2 | ··· |
| … | 访问量1 | 访问量2 | ··· |
每次调用程序就会生成一列数据
存储过程
利用xlwt, xlrd 进行表格的读写
#如果excel表格不存在,则创建
if not os.path.exists("ReadRecord.xls"):
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet('My ReadRecord')
worksheet.write(0, 0, "1")
workbook.save("ReadRecord.xls")
# 打开excel, 为rexcel
rexcel = xlrd.open_workbook("ReadRecord.xls")
# 拷贝原来的rexcel, 变成excel
excel = copy(rexcel)
# 得到工作表
worksheet = excel.get_sheet(0)
# 得到列数
read_time = rexcel.sheets()[0].ncols
###写入操作
#保存表格
excel.save('ReadRecord.xls')需要注意的地方
- 表格新添加的列的列数是根据原来的表格列数来的
- 因为是进行更新,所以先要拷贝原来的表格,不然直接用write是进行覆盖
因为用户有可能会继续发布博客, 所以最新的博客信息,应该存在最后一行, url改为经过时间排序的html(比如https://blog.csdn.net/qq874455953?orderby=UpdateTime), 而且默认是按新旧排序,所以加入的时候,从最后一行来写入表格
代码源码
代码如下, 会生成一个excel表格,存储了所有文章的阅读量,
import requests
import datetime
import os
import xlwt
import xlrd
from xlutils.copy import copy
from bs4 import BeautifulSoup
#获取HTML
def get_page_source(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "failed"
def main():
#url = input("请输入博客主页网址, 比如:https://blog.csdn.net/qq874455953\n")
url = "https://blog.csdn.net/qq874455953"
#改为你的博客主页地址
html = get_page_source(url + '?orderby=UpdateTime')
#解析HTML 使用BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
articleList = soup.find_all('div', attrs={'class': 'article-item-box csdn-tracking-statistics'})
readBar = soup.find_all('div', attrs={'class': 'info-box d-flex align-content-center'})
#如果excel表格不存在,则创建
if not os.path.exists("ReadRecord.xls"):
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet('My ReadRecord')
worksheet.write(0, 0, "1")
workbook.save("ReadRecord.xls")
# 打开excel, 为rexcel
rexcel = xlrd.open_workbook("ReadRecord.xls")
# 拷贝原来的rexcel, 变成excel
excel = copy(rexcel)
# 得到工作表
worksheet = excel.get_sheet(0)
# 得到列数
read_time = rexcel.sheets()[0].ncols
#得到当前日期
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d'))
#写好第一列 说明
worksheet.write(0, 0, "文章名字")
worksheet.write(0, read_time, nowTime)
#获取文章列数
articleListLen = len(articleList)
#把数据写入到表格里
for i in range(articleListLen):
articleName = articleList[i].h4.a.contents[2]
articleReadCount = readBar[i].contents[3].span.string.split(":")[1]
worksheet.write(articleListLen - i, 0, articleName)
worksheet.write(articleListLen - i, read_time, articleReadCount)
#保存表格
excel.save('ReadRecord.xls')
if __name__=="__main__":
main()总结
最后你可以把这个代码挂到服务器上, 然后每天定时运行一次,就可以看到你的具体文章的访问量变化了!
不过需要修改的地方就是 我这个只能读一页的, 其实博客不止这么多,需要考虑不同页的问题

