


Deep learning-based personality recognition from text posts of online social networks 阅读笔记
一、摘要
这是一篇在性格探测这方面比较新的文章了, 时间是2018年,作者提出了一种分层结构的神经网络——AttRCNN, 还有一种基于CNN的变体,从用户text学习到语义的特征, 然后把这个语义特征和文本的语言学特征结合起来,放到传统的回归模型里预测5大性格的分数
个人觉得 比较有新意的一点是能打分? 而不是简单的判断true or false
二、模型过程
1.文本预处理
1.1 文本切分
简单通过空格来切分句子得到单词, 不改版任何的字母,这是为了尽可能的保留文本, 得到完整的特征, 但是会去掉一些表情,例如: ∧ ∧, (/∼ /)
1.2 文本统一
减少类似重复的字母, 例如busyyyy, busyyyyyyyyy, 这些都应该看成busy, 同时转换成小写,把处理好的单词列表进入过程2
2. 基于统计的特征提取
2.1 提取特殊的语言统计特征
作者认为具有不同性格的人可能有不同的使用标点符号,符号,表情符号和大写字母的习惯, 所以作者从这些特殊的方面进行统计,提取5个特征, 这个是作者自己设置的, 当然你也可以找新的特征
- (1) rateof emoticons;
- (2) rate of tokens which have no less than 3 tandem duplicated letters or symbols;
- (3) rate of capital letters;
- (4) rate of capitalized words;
- (5) total number of text posts of each user.
2.2 提取基于字典的语言特征
作者通过Linguistic Inquiry and Word Count (LIWC)工具,分析出64个基于字典的语言特征
3. 基于深度学习的文本建模
3.1 基于无监督学习的词嵌入
基于词袋模型,使用word2vec 训练我们的文本, 然后得到每个单词的词向量, 对于未知的word全部随机给一个[-0.25, +0.25]的正态分布的参数
3.2 基于监督学习的深度语义特征提取
这是文章的重点部分, 作者定义了一个叫做AttRCNN-CNNs的模型来提取语义特征, 因为它是一个AttRCNN, CNNs 的分层结构,
可以从这张图看到AttRCNN-CNNs模型的层次:
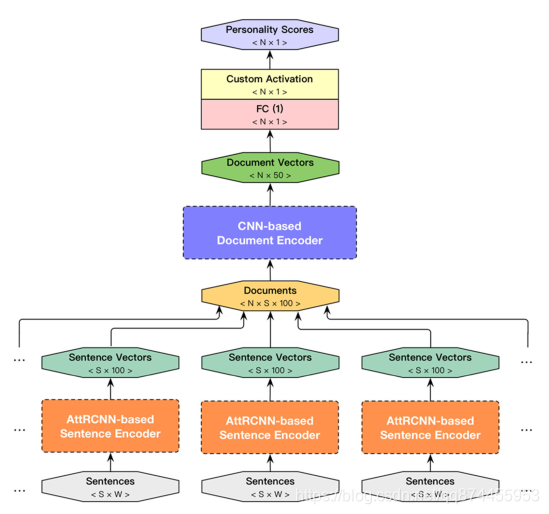
3.2.1 AttRCNN进行句子向量化
由RCNN作为启发, 作者构想出一种AttRCNN用于把句子变成句子向量。
结构图如下:
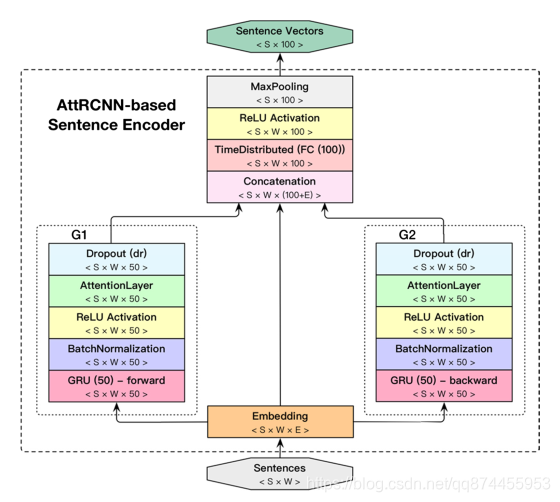
具体过程分为5个步骤,下面将详细解释
S1. Word Embedding
通过训练好的词嵌入矩阵,把句子里的每个word,变成词向量。
S2. 基于GRU的神经网络得到word上下文特征
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
输入词向量到不同的两个GRU分别得到单词的上文特征,和下文特征,两个GRU结构相同,只是扫描方向不同, 下面已向前扫描的GRU作为解释。
S2-1. 提取上文特征
使用前向的GRU, 在顶层使用batch normalization训练。对于每个word得到一个50维的注释向量
下图是如何从
S2-2. 使用ReLU作为激活函数
使用ReLU函数作为激活函数
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
S2-3. 加入dropout层
为防止过拟合, 还加上了dropout层
S3. 组合上文特征,下文特征,本身特征
通过上面的两个GRU神经网络, 我们分别得到每个单词的上文或下文特征,我们将其组合
50(上文) + E(word本身) + 50(下文)
S4. 全连接层
通过全连接层把100+E维的特征变成100维
S5. 词向量组变句向量
通过max-pooling层,我们把词向量变成句向量,完成此模块的任务。
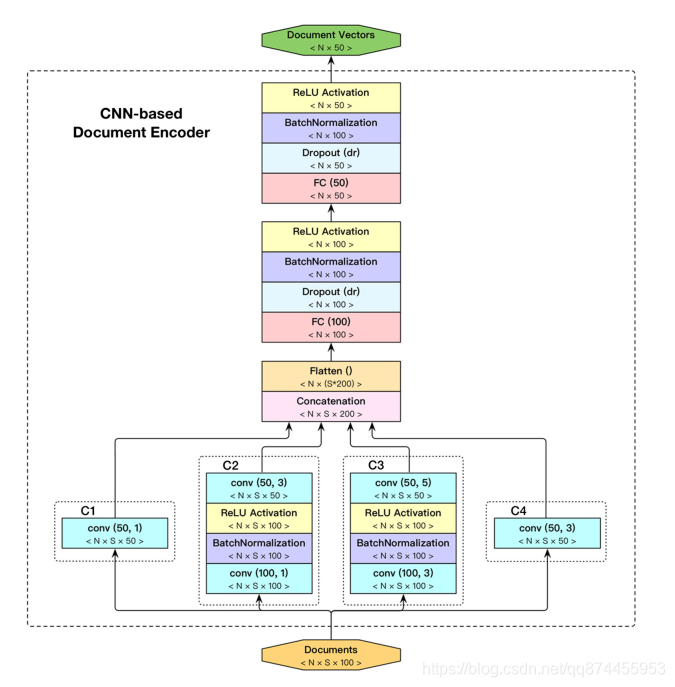
3.2.2 CNNs进行文档向量化
使用CNNs来把得到的句子向量变成文档向量,
作者使用的是CNN-based Inception architecture, 一种基于CNN的结构来实现。
(注意不是CNN)
CNNs的具体结构如下
3.2.3 训练模型
模型采用批量梯度下降, 使用均方误差作为目标函数,最大迭代30轮.
4.预测
经过上面的步骤我们得到了一个119维的特征向量, 其中包括5个特殊方面的语言特征, 64个基于字典的语言特征, 50个文档语义特征, 我们将其放到GBR里,得到分数,当然这个回归算法在后面的实验中会尝试很多。
三、实验结果
待分析~~

