
半监督学习介绍
转载地址
https://blog.csdn.net/ice110956/article/details/13775071
什么是半监督学习?
传统的机器学习技术分为两类,一类是无监督学习,一类是监督学习。
无监督学习只利用未标记的样本集,而监督学习则只利用标记的样本集进行学习。
但在很多实际问题中,只有少量的带有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到。
这就促使能同时利用标记样本和未标记样本的半监督学习技术迅速发展起来。
半监督学习理论简述:
半监督学习有两个样本集,一个有标记,一个没有标记.分别记作
Lable={(xi,yi)},Unlabled={(xi)}.并且数量上,L<<U.
1. 单独使用有标记样本,我们能够生成有监督分类算法
2. 单独使用无标记样本,我们能够生成无监督聚类算法
3. 两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果.
一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类.也就是在1中加入无标记样本,增强分类效果.
半监督学习的动力,motivation
某人讨论的时候,总是教导我们的词,motivation.一下午四五遍地强调写论文要有motivation.下面说说半监督学习的motivation.
1. 有标记样本难以获取.
需要专门的人员,特别的设备,额外的开销等等.
2. 无标记的样本相对而言是很廉价的.
半监督学习与直推式学习的区别:
这个网上也有论述.主要就是半监督学习是归纳式的,生成的模型可用做更广泛的样本;而直推式学习仅仅为了当前无标记样本的分类.
简单的说,前者使用无标记样本,为了以后其他样本更好的分类.
后者只是为了分类好这些有限的无标记样本.
下面几个图来生动形象地诠释半监督的好处:
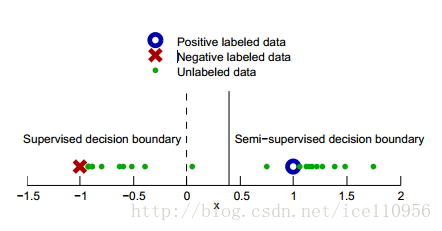
上图中,只有两个标记样本,X,O,剩下绿点是无标记的样本.通过无标记样本的加入,原来的分类界限从0移到了0.5处,更好地拟合了样本的现实分布.
半监督学习算法分类:
1. self-training(自训练算法)
2. generative models生成模型
3. SVMs半监督支持向量机
4. graph-basedmethods图论方法
5. multiview learing多视角算法
6. 其他方法
接着简单介绍上述的几个算法
self-training算法:
还是两个样本集合:Labled={(xi,yi)};Unlabled= {xj}.
执行如下算法
Repeat:
1. 用L生成分类策略F;
2. 用F分类U,计算误差
3. 选取U的子集u,即误差小的,加入标记.L=L+u;
重复上述步骤,直到U为空集.
上面的算法中,L通过不断在U中,选择表现良好的样本加入,并且不断更新子集的算法F,最后得到一个最有的F.
Self-training的一个具体实例:最近邻算法
记d(x1,x2)为两个样本的欧式距离,执行如下算法:
Repeat:
1. 用L生成分类策略F;
2. 选择x = argmin d(x, x0). 其中x∈U,min x0∈L.也就是选择离标记样本最近的无标记样本.
2. 用F给x定一个类别F(x).
3. 把(x,F(x))加入L中
重复上述步骤,直到U为空集.
上面算法中,也就是定义了self-training的”误差最小”,也就是用欧式距离来定义”表现最好的无标记样本”,再用F给个标记,加入L中,并且也动态更新F.
下面是这种算法的效果图:
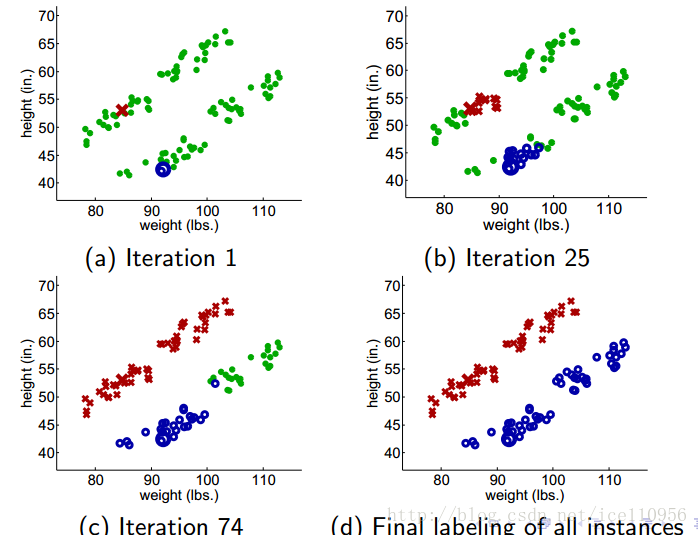
上图从两个点出发,不断加入最近邻点,不断更新F.
上面的算法表现良好,当然更多的是表现不好.如下:
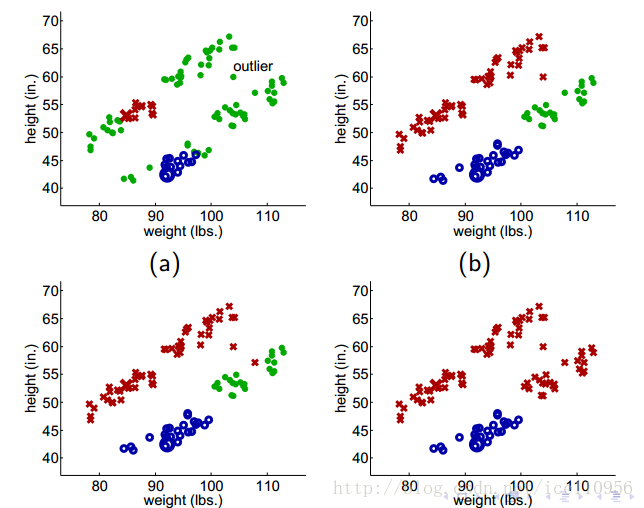
生成模型
生成算法来源于假设,比如我们假设原样本满足高斯分布,然后用最大释然的概率思想来拟合一个高斯分布,也就是常用的高斯混合模型(GMM).
简单介绍下高斯混合模型:
假设如下的样本分布:
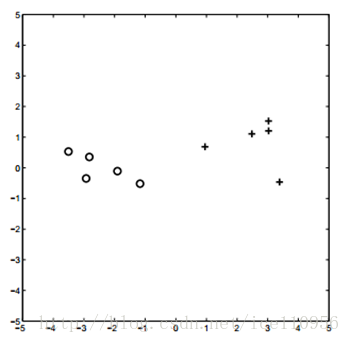
我们假设他们满足高斯分布.
高斯分布的参数有: θ = {w1, w2, µ1, µ2, Σ1, Σ2}
利用最大释然的思想,最大化如下概率:
p(x, y|θ) = p(y|θ)p(x|y, θ).
得到如下的假设分布:
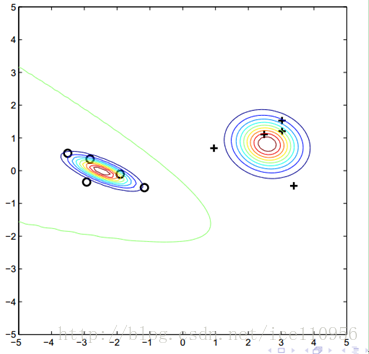
顺便贴一个介绍高斯混合模型日志:
http://blog.csdn.net/zouxy09/article/details/8537620
接着是我们的半监督生成算法:
样本分布如下:
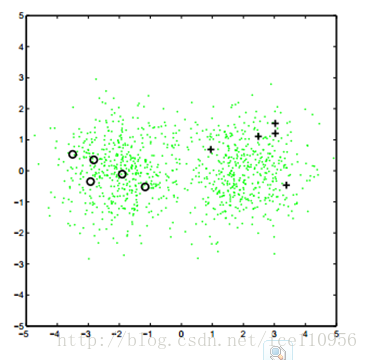
算法过后,得到如下分布:
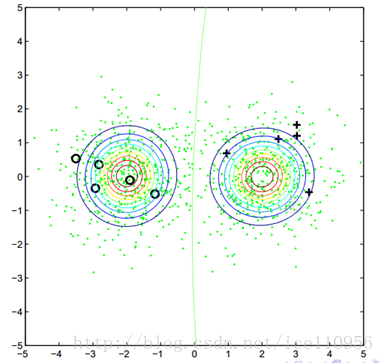
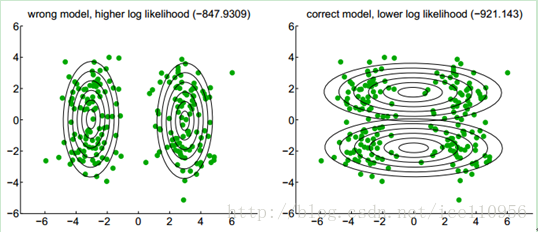
对比这两个图,说明下高斯混合模型与半监督生成模型的区别:
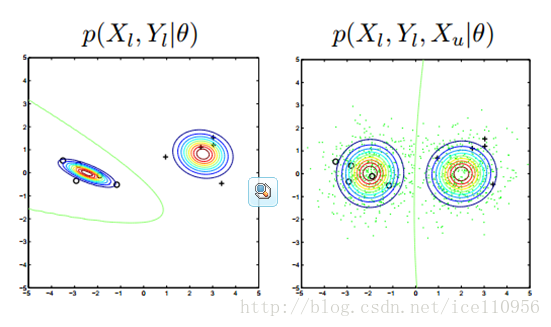
这两种方法的释然函数不同,前者最大化标记样本出现概率,后者加入了无标记样本出现概率.
算法的具体实现,请参见E-M算法.
这样生成的算法也有许多不良表现,如下:
假设原始的分布式这样的:
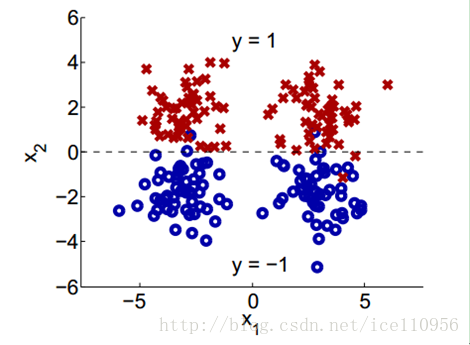
通过GMM,它变成了这样:
几个需要注意的地方:
1. 高斯混合的局部收敛性
2. 减少无标记样本的权值
半监督SVM,图算法模型,流行模型等.
SVM的理论不再赘述,就是一个最优超平面:
偷一张很牛逼的SVM图:
这些内容涵盖比较广泛,一篇日志装不下.有兴趣地可以进一步了解.
最后是小结
上两张图:

由于我们对火星基本不了解,探索号带着稀少的标记样本知识飞到了火星.接着就是不断地接触新的样本,更新自己的算法来适应火星环境.
还有我们,从小不断地接触新的事物,不断地被灌输标记或无标记的样本,活到老学到老.

