


最近有人提到char和unsigned char有什么区别,当然这个问题如果刚学计算机或者编程语言的人来说,非常简单。我也这么认为,无非就是有符号和无符号的差别嘛。
这个问题让我想到了以前学习计算机常识的时候关于补码,原码,反码的差异。这里摘取参考文章【1】中的部分内容:
注意:此处的'=='是相等的意思。'='是赋值的意思。
在机器世界里:
正数的最高位是符号位0,负数的最高位是符号位1。
对于正数:反码==补码==原码。
对于负数:反码==除符号位以外的各位取反。
补码==反码+1.
原码==补码-1后的反码==补码的反码+1。(读完本文后,应该能够直观地认识到本式的正确性)
可以轻易发现如下规律:
自然计算 :a-b==c.
计算机计算:a-b==a+b的补码==d.
c的补码是d.
通过此法,可以把减法运算转换为加法运算。
所以补码的设计目的是:
1.使符号位能与有效值部分一起参加运算,从而简化运算规则.
2.减运算转换为加运算,进一步简化计算机中运算器的线路设计.
讲的非常清晰了吧,是的。但是在计算机中,常做类型转换,当char或者unsigned char转换成int的时候,两者的差异是显而易见的。这里采用了部分文章【2】的代码对转换过程做了验证。
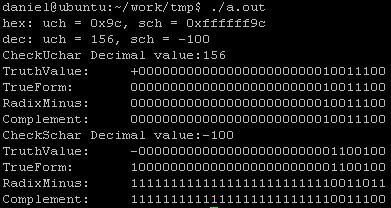
1)当我对uch和sch同时赋值-100的时候uch和sch都是十六进制的0x9c
2)此时由于两者一个是有符号,另一个是无符号的,我们可以看到十进制输出的时候,无符号的是156,而有符号的,最前面一个bit解释为了负值 -100
3)然后我们看下对uch进行类型转换(int)然后看下真值,原码,反码和补码
4)最后我们看下对sch进行类型转换(int)然后看下真值,原码,反码和补码
可以看出uch和sch最大的差异就是前面的那个符号位,仅仅那一个bit位,对于我们计算机来说,存储的内容(补码)将是绝然不同的。
真值,原码,反码和补码转换代码请详见参考文章【2】
- /* 检查uchar */
- void CheckUchar(unsigned char uch)
- {
- int x;
- char b[MAX+1];
- x = uch;
- printf("CheckUchar Decimal value:%d\n", x);
- TruthValue(b, x);//获取真值
- printf("TruthValue:\t%s\n", b);
- TrueForm(b, x); //获取原码
- printf("TrueForm:\t%s\n", b);
- RadixMinus(b, x);//获取反码
- printf("RadixMinus:\t%s\n", b);
- Complement(b, x);//获取补码
- printf("Complement:\t%s\n", b);
- }
- /* 检查schar */
- void CheckSchar(char sch)
- {
- int x;
- char b[MAX+1];
- x = sch;
- printf("CheckSchar Decimal value:%d\n", x);
- TruthValue(b, x);//获取真值
- printf("TruthValue:\t%s\n", b);
- TrueForm(b, x); //获取原码
- printf("TrueForm:\t%s\n", b);
- RadixMinus(b, x);//获取反码
- printf("RadixMinus:\t%s\n", b);
- Complement(b, x);//获取补码
- printf("Complement:\t%s\n", b);
- }
- int main()
- {
- unsigned char uch = -100;
- char sch = -100;
- printf("hex: uch = 0x%x, sch = 0x%x\n", uch, sch);
- printf("dec: uch = %d, sch = %d\n", uch, sch);
- CheckUchar(uch);
- CheckSchar(sch);
- return 0;
- }
参考文章:
【2】闲扯原码,补码和反码

