day2
列表的操作:
names = "xiaoming zhangshang xiaohua wangwu" names = ['xiaoming','zhangshang','xiaohua','wangwu']#列表的定义 print(names) print(names[0],names[1])#列表取取 print(names[1:3])#顾头不顾尾 意思就是尾不包含下标为3的数据 print(names[0:3])#取前三位 print(names[:3])#取前三位 前面为0可以省去 print(names[-1])#取最后一位 print(names[-2:])#取最后两位 注意冒号后面什么都不要写代表到结束 names.append('xiaoli')#在最后一位增加 names.insert(1,'xiaozhang')#在下标1插入 names.remove('xiaozhang')#删除小张 names[0]='小明' #修改下标为0的数据 del names[0] #删除下为0的 等同于 names.pop(0) del names 删除变量 pop = names.pop()#不加参数默认删除最后一个 并且返回删除的值 pop =names.pop(1)#删除下标为1的数据并且返回该数据 names.count('xiaongming')#统计小时出现的次数 names.reverse()#反转数据 names2=[1,2,3] names.extend(names2)#合并列表 names.index('xiaoming')#返回xiaoming的下标 del names #删除变量 names.clear()#清空列表 print(pop) print(names)
字符串操作
name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 '---------------------Alex Li----------------------' name.count('lex') 统计 lex出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格 name.find('A') 查找A,找到返回其索引, 找不到返回-1 format : >>> msg = "my name is {}, and age is {}" >>> msg.format("alex",22) 'my name is alex, and age is 22' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("alex",22) 'my name is 22, and age is alex' >>> msg = "my name is {name}, and age is {age}" >>> msg.format(age=22,name="ale") 'my name is ale, and age is 22' format_map >>> msg.format_map({'name':'alex','age':22}) 'my name is alex, and age is 22' msg.index('a') 返回a所在字符串的索引 '9aA'.isalnum() True '9'.isdigit() 是否整数 name.isnumeric name.isprintable name.isspace name.istitle name.isupper "|".join(['alex','jack','rain']) 'alex|jack|rain' maketrans >>> intab = "aeiou" #实际意义的字符串 >>> outtab = "12345" #映射成的字符串 >>> trantab = str.maketrans(intab, outtab) >>> >>> str = "this is string example....wow!!!" >>> str.translate(trantab) 'th3s 3s str3ng 2x1mpl2....w4w!!!' msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') >>> "alex li, chinese name is lijie".replace("li","LI",1) 'alex LI, chinese name is lijie' msg.swapcase 大小写互换 >>> msg.zfill(40) '00000my name is {name}, and age is {age}' >>> n4.ljust(40,"-") 'Hello 2orld-----------------------------' >>> n4.rjust(40,"-") '-----------------------------Hello 2orld' >>> b="ddefdsdff_哈哈" >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 True
字典的定义
info = { 'stu1101':'xiaoiming', 'stu1102':'laozhang', 'stu1103':'lishi' , }
字典的特性 :
1》 字典是无序的
2》字典的key必须是唯一的 天生去重
字典的 增,删,修改,查询操作
#增加 info['stu1104'] = 'laoli' #修改 info['stu1101'] = '小明' #删除 info.pop('stu1102') #删除key键为stu1102的数据 并且做返回 pop必须带参数 del info['stu1102'] #del 关键字删除 info.popitem() #随机删除 #查找 'stu1101' in info #返回真假 info.get('stu1101') #get方法按key查找 如果该key不存也不会报错 info['stu1106'] #存在返回对应的值 不存在该key则报错
其它补充
#values >>> info.values() dict_values(['LongZe Luola', 'XiaoZe Maliya']) #keys >>> info.keys() dict_keys(['stu1102', 'stu1103']) #setdefault >>> info.setdefault("stu1106","Alex") 'Alex' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> info.setdefault("stu1102","龙泽萝拉") 'LongZe Luola' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #update >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"} >>> info.update(b) >>> info {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #items info.items() dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')]) #通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个 >>> dict.fromkeys([1,2,3],'testd') {1: 'testd', 2: 'testd', 3: 'testd'}
字典循环
#方法 一 推荐使用 for i in info: print(i,inf0[i]) #方法二 for k,v in info.items(): #会先把info转换成字典 数据量较大 不推荐使用 pritn(k,v)
集合
s = set([3,5,9,10]) #创建一个数值集合 t = set("Hello") #创建一个唯一字符的集合 a = t | s # t 和 s的并集 b = t & s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 基本操作: t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 使用remove()可以删除一项: t.remove('H') len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制
文件操作
f = open('lyrics') #打开文件 first_line = f.readline() print('first line:',first_line) #读一行 print('我是分隔线'.center(50,'-')) data = f.read()# 读取剩下的所有内容,文件大时不要用 print(data) #打印文件 f.close() #关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f: #等同于 f = open('log','r') 只是代码在with里面运行 ....
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
1 with open('log1') as obj1, open('log2') as obj2:
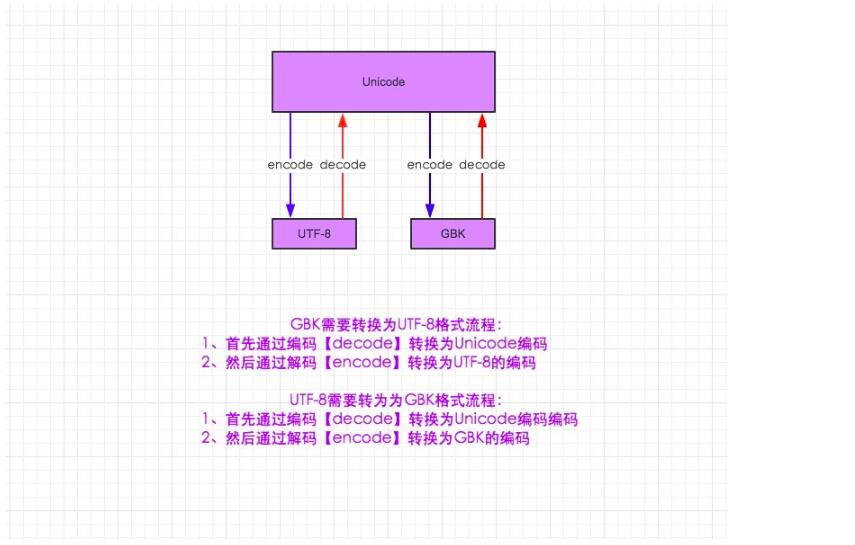
字符编码与转换