分布式爬虫与增量式爬虫
一,分布式爬虫介绍
1.scrapy框架为何不能实现分布式?
其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls列表中的url。(多台机器无法共享同一个调度器)
其二:多台机器爬取到的数据无法通过同一个管道对数据进行统一的数据持久出存储。(多台机器无法共享同一个管道)
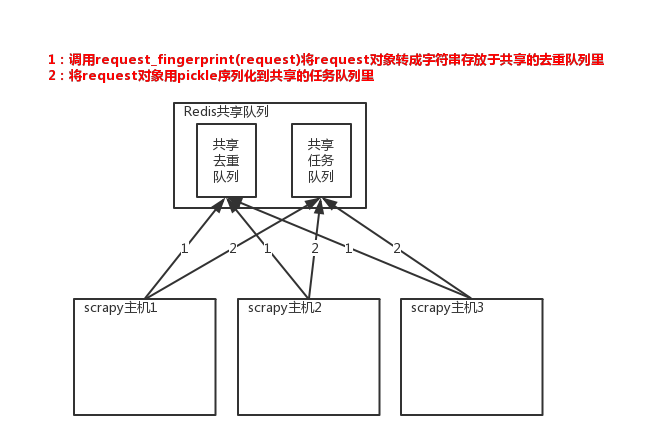
2.scrapy_redis实现原理
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)

所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
#1、共享队列 #2、重写Scheduler,让其无论是去重还是任务都去访问共享队列 #3、为Scheduler定制去重规则(利用redis的集合类型)
以上三点便是scrapy-redis组件的核心功能
安装: pip3 install scrapy-redis #源码: D:\python3.6\Lib\site-packages\scrapy_redis
使用
1.安装scrapy-redis组件:
- pip install scrapy-redis
- scrapy-redis是基于scrapy框架开发出的一套组件,其作用就是可以让scrapy实现分布式爬虫。
2.编写爬虫文件:
- 同之前scrapy中基于Spider或者CrawlSpider的编写方式一致。
3.编写管道文件:
- 在scrapy-redis组件中已经帮助我们封装好了一个专门用于连接存储redis数据库的管道(RedisPipeline),因此我们直接使用即可,无需自己编写管道文件。
4.编写配置文件:
- 在settings.py中开启管道,且指定使用scrapy-redis中封装好的管道。
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 该管道默认会连接且将数据存储到本机的redis服务中,如果想要连接存储到其他redis服务中需要在settings.py中进行如下配置:
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
REDIS_ENCODING = ‘utf-8’
REDIS_PARAMS = {‘password’:’123456’}
注意:redis中的配置需要修改
.对redis配置文件进行配置: - 注释该行:bind 127.0.0.1,表示可以让其他ip访问redis - 将yes该为no:protected-mode no,表示可以让其他ip操作redis
还需要做的是要在settings中设置
使用scrapy-redis组件中封装好的调度器,将所有的url存储到该指定的调度器中,从而实现了多台机器的调度器共享。
# 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True
redis实现分布式基本流程
# -1.将redis数据库的配置文件进行改动: protected-mode no #bind 127.0.0.1 # 0.下载scrapy-redis # 1.创建工程 # 2.创建基于scrawlSpider的爬虫文件 # 3.导入RedisCrawlSpider类 # 4.将start_urls更换成redis_key属性 # 5.在现有代码的基础上进行连接提取和解析操作 # 6.将解析的数据值封装到item中,然后将item对象提交到scrapy-redis组件中的管道里('scrapy_redis.pipelines.RedisPipeline': 400,) # 7.管道会将数据值写入到指定的redis数据库中(在配置文件中进行指定redis数据库ip的编写) # 8.在当前工程中使用scrapy-redis封装好的调度器(在配置文件中进行配置) # 9.将起始url扔到调度器队列(redis_key)中 # 10.启动redis服务器:redis-server redis.windows.conf # 11.启动redis-cli # 12.执行当前爬虫文件:scrapy runspider 爬虫文件 # 13.向队列中扔一个起始url:在redis-cli执行扔的操作(lpush redis_key的value值 起始url)
spider.py文件:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider from pa02.items import Pa02Item class FbsSpider(RedisCrawlSpider): name = 'fbs' # allowed_domains = ['www.xxx.com'] # start_urls = ['http://www.xxx.com/'] redis_key = "fbs" rules = ( Rule(LinkExtractor(allow=r'/type/6-\d+.html'), callback='parse_item', follow=True), ) def parse_item(self, response): item = Pa02Item() #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() item["title"] = response.xpath('/html/body/div[5]/div[1]/div[3]/ul/li/a/span[2]/p[1]/text()').extract_first() item["actor"] = response.xpath('/html/body/div[5]/div[1]/div[3]/ul/li/a/span[2]/p[2]/text()').extract_first() return item
items.py文件
import scrapy class Pa02Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() actor = scrapy.Field()
pipelines.py文件
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class Pa02Pipeline(object): r = None def open_spider(self, spider): import redis self.r = redis.Redis() print("开始分布式爬虫") def process_item(self, item, spider): dic = dict(item) self.r.lpush('F8_data', dic) return item def close_spider(self, spider): print("爬虫任务完成")
- 进入到 py文件所在的路径 通过 代码 scrapy runspider xxx.py 执行分布式程序,
- 启动reids服务端(注意conf文件配置),启动客户端,最后向调度器队列中仍入一个起始url: lpush redis_key "http://www.xxx.com/"
分布式爬虫实例:http://baijiahao.baidu.com/s?id=1585117266335386391&wfr=spider&for=pc
二、增量式爬虫
概念:通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新出的新数据。 如何进行增量式的爬取工作: 1.在发送请求之前判断这个URL是不是之前爬取过 2.在解析内容后判断这部分内容是不是之前爬取过 3.写入存储介质时判断内容是不是已经在介质中存在 分析 不难发现,其实增量爬取的核心是去重, 至于去重的操作在哪个步骤起作用,只能说各有利弊。 在我看来,前两种思路需要根据实际情况取一个(也可能都用)。 第一种思路适合不断有新页面出现的网站,比如说小说的新章节,每天的最新新闻等等; 第二种思路则适合页面内容会更新的网站。 第三个思路是相当于是最后的一道防线。这样做可以最大程度上达到去重的目的。 去重方法 1,将爬取过程中产生的url进行存储,存储在redis的set中。当下次进行数据爬取时,首先对即将要发起的请求对应的url在存储的url的set中做判断,如果存在则不进行请求,否则才进行请求。 2,对爬取到的网页内容进行唯一标识的制定,然后将该唯一表示存储至redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,首先可以先判断该数据的唯一标识在redis的set中是否存在,在决定是否进行持久化存储。
案例一:爬取dilidili资源区的所有帖子 (在请求发出之前判断内容有没有爬过)
spider.py
import scrapy import hashlib import redis from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from pa03.items import Pa03Item class AddpaSpider(CrawlSpider): name = 'addpa' # allowed_domains = ['www.xxx.com'] start_urls = ['http://bbs.005.tv/forum.php?mod=forumdisplay&fid=709&page=1'] # 爬取dilidili资源区 文件 rules = ( Rule(LinkExtractor(allow=r'forum.php?mod=forumdisplay&fid=709&page=/d+'), callback='parse_item', follow=True), ) def parse_item(self, response): conn = redis.Redis(host="127.0.0.1",port=6379) item = Pa03Item() item["title"] = response.xpath('//table/tbody[starts-with(@id, "normalthread_")]/tr/th/a[@class="s xst"]/text()').extract_first() href = response.xpath('//table/tbody[starts-with(@id, "normalthread_")]/tr/th/a[@class="s xst"]/@href').extract_first() item["url"] = "http://bbs.005.tv/" + href item["resnum"] = response.xpath('//table/tbody[starts-with(@id, "normalthread_")]/tr/td[@class="num"]/a/text()').extract_first() #item['domain_id'] = response.path('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() source = item["title"] + item["url"] + item["resnum"] hash_value = hashlib.sha3_256(source.encode()).hexdigist() result = conn.sadd("dilidili_hash",hash_value) if result == 1: yield item else: print("数据没有更新")
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class Pa03Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() url = scrapy.Field() resnum = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class Pa03Pipeline(object): f = None def open_spider(self,spider): self.f = open("dilidili.txt","w",encoding="utf8") def process_item(self, item, spider): import json dic = dict(item) self.f.write(json.dumps(dic,ensure_ascii=False)) return item def close_spider(self,spider): self.f.close()
案例二: 爬取4567tv网站中喜剧片的所有电影的标题和上映年份 (在请求之前判断url有没有被爬过)
1. 爬虫文件 # -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from redis import Redis from moviePro.items import MovieproItem class MovieSpider(CrawlSpider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/index.php/vod/show/id/6/page/23.html'] rules = ( Rule(LinkExtractor(allow=r'/index.php/vod/show/id/6/page/\d+.html'), callback='parse_item', follow=True), ) # 创建redis链接对象 conn = Redis(host='127.0.0.1', port=6379) def parse_item(self, response): li_list = response.xpath('//li[@class="col-md-6 col-sm-4 col-xs-3"]') for li in li_list: # 获取详情页的url detail_url = 'http://www.4567tv.tv' + li.xpath('./div/a/@href').extract_first() # 将详情页的url存入redis的set中 ex = self.conn.sadd('urls', detail_url) # 设置redis的key-value成功时,会返回1,否则返回0 if ex == 1: print('该url没有被爬取过,可以进行数据的爬取') yield scrapy.Request(url=detail_url, callback=self.parst_detail) else: print('数据还没有更新,暂无新数据可爬取!') # 解析详情页中的电影名称和类型,进行持久化存储 def parst_detail(self, response): item = MovieproItem() item['title'] = response.xpath('//div[@class="stui-content__detail"]/h3[@class="title"]/text()').extract_first() item['year'] = response.xpath('//div[@class="stui-content__detail"]/p[1]/a[2]/@href').extract_first() yield item 2. items.py import scrapy class MovieproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() year = scrapy.Field() 3. pipelines.py from redis import Redis class MovieproPipeline(object): conn = None def open_spider(self, spider): self.conn = Redis(host='127.0.0.1', port=6379) def process_item(self, item, spider): dic = { 'title': item['title'], 'year': item['year'] } print(dic) self.conn.lpush('movieData', dic) return item
这里可以观摩一下大佬的项目案例
https://blog.csdn.net/seven_2016/article/details/72802961?tdsourcetag=s_pcqq_aiomsg

