06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”。
Spark SQL有以下特点
(1)、支持多种数据源:Hive、RDD、Parquet、JSON、JDBC等。
(2)、多种性能优化技术:in-memory columnar storage、byte-code generation、cost model动态评估等。
(3)、组件扩展性:对于SQL的语法解析器、分析器以及优化器,用户都可以自己重新开发,并且动态扩展。
2.用spark.read 创建DataFrame
回答在下面Spark SQL DataFrame的基本操作代码部分
3.观察从不同类型文件创建DataFrame有什么异同?
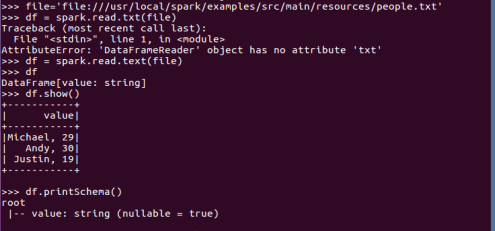
txt文件:创建的DataFrame数据没有结构
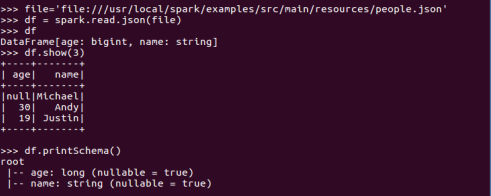
json文件:创建的DataFrame数据有结构
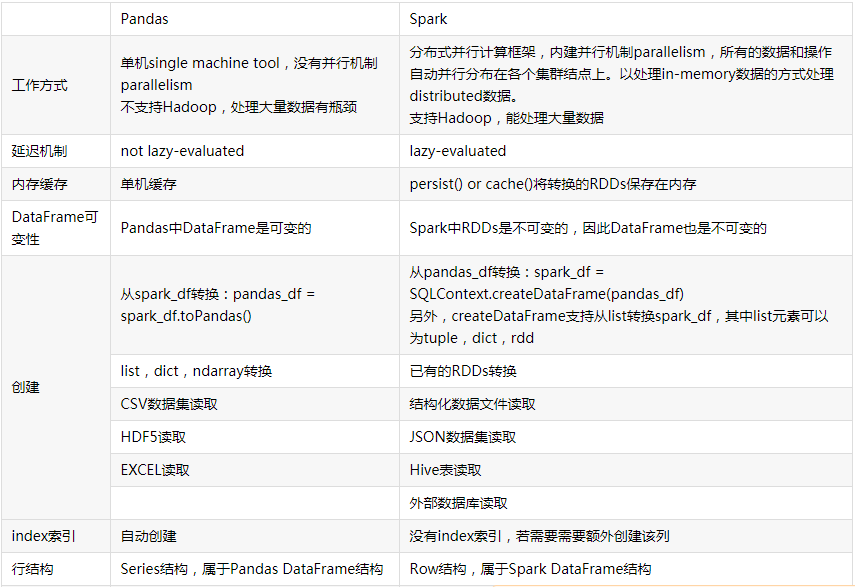
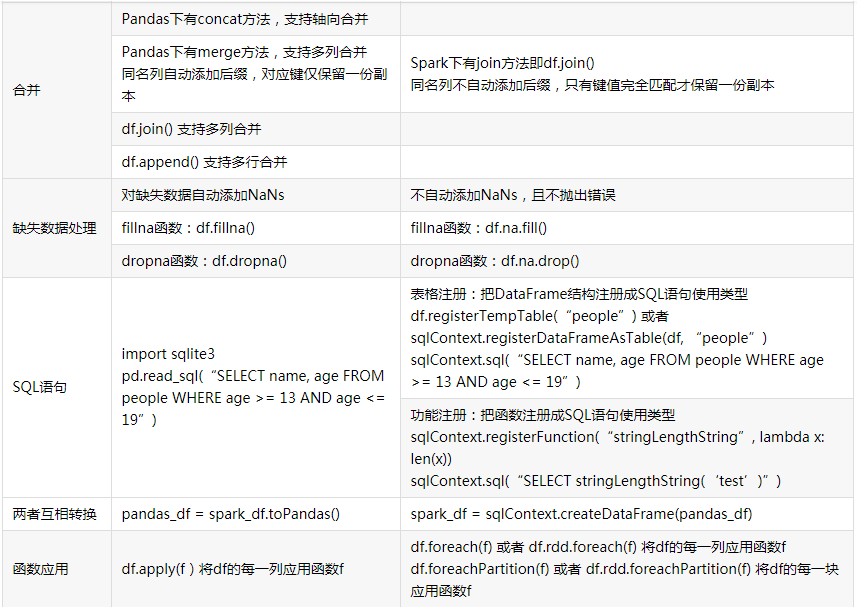
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?



Spark SQL DataFrame的基本操作
创建:
spark.read.text()
spark.read.json()
打印数据
df.show()默认打印前20条数据,df.show(n)
打印概要
df.printSchema()
查询总行数
df.count()
df.head(3) #list类型,list中每个元素是Row类
输出全部行
df.collect() #list类型,list中每个元素是Row类
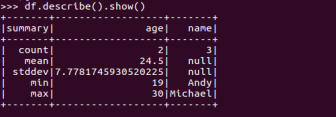
查询概况
df.describe().show()
取列
df[‘name’]
df.name
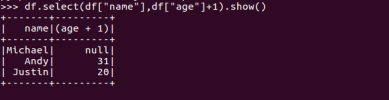
df.select()
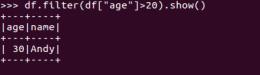
df.filter()
df.groupBy()
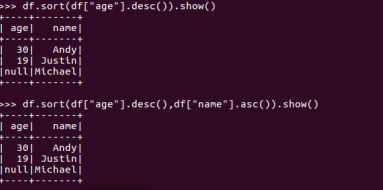
df.sort()

df.filter()