部署方案@常用软件的安装
1 CentOS系统的安装
1.1 安装版本
- CentOS-6.4-x86_64-bin-DVD1.iso
1.2 安装步骤
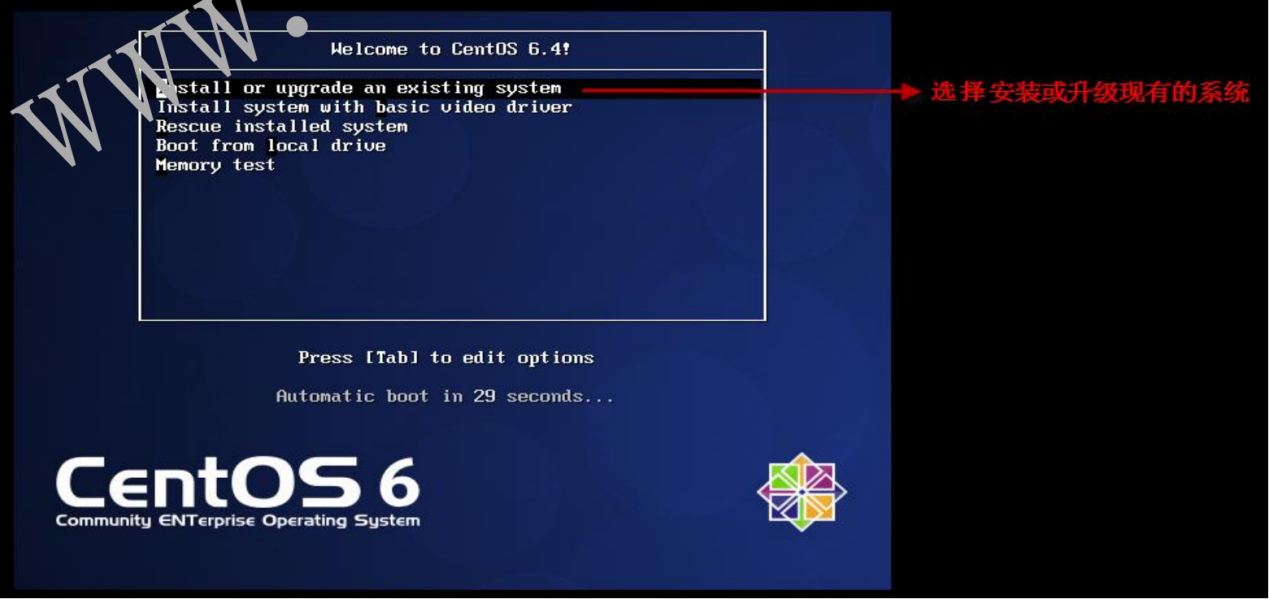
- 1.2.1 选择安装方式
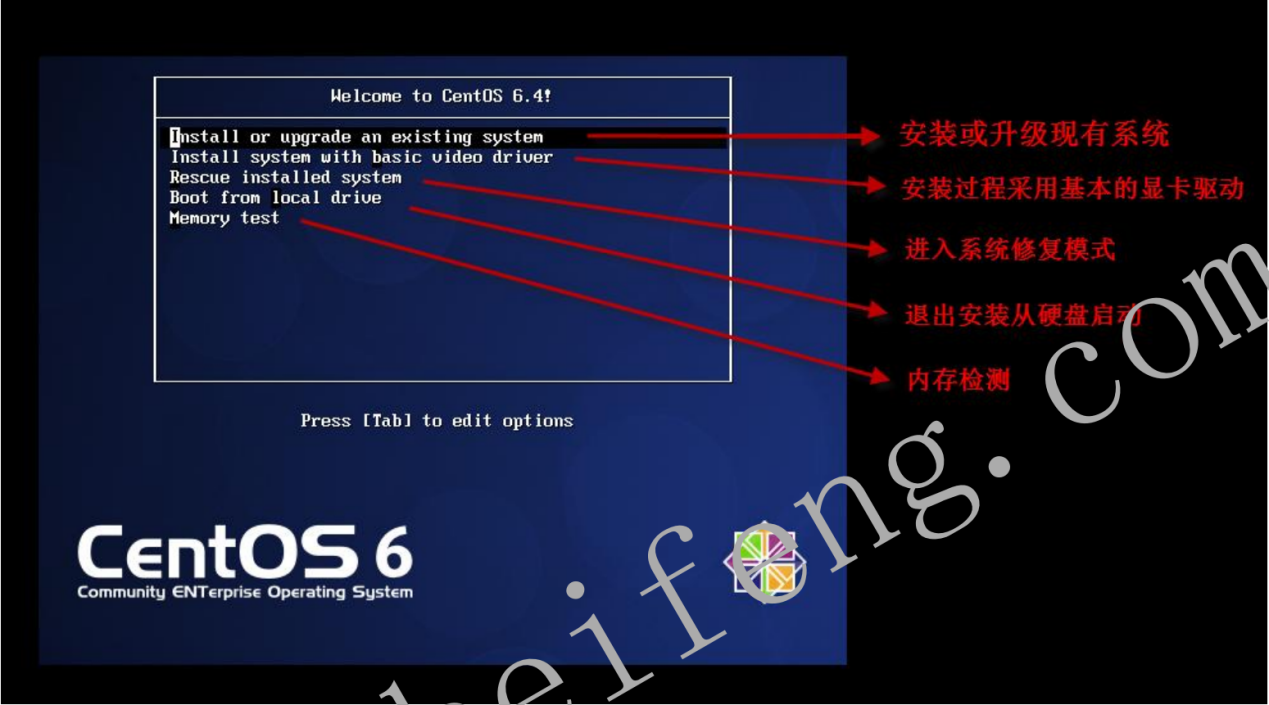
- 1.2.2 安装或升级现有系统
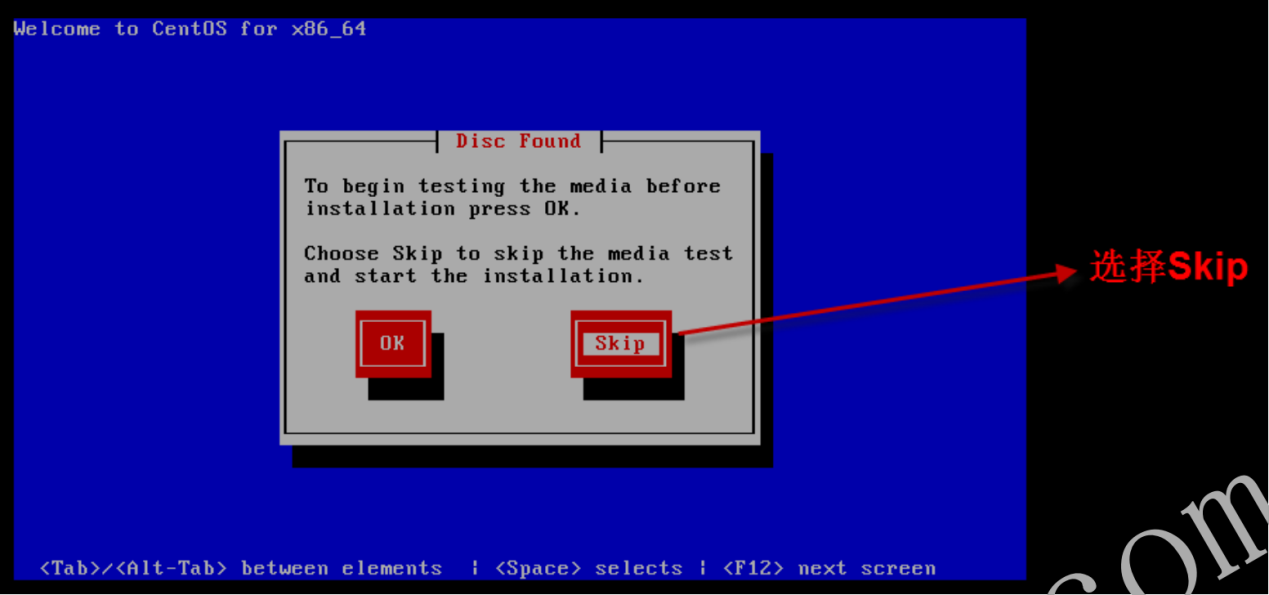
- 1.2.3 跳过检测媒介
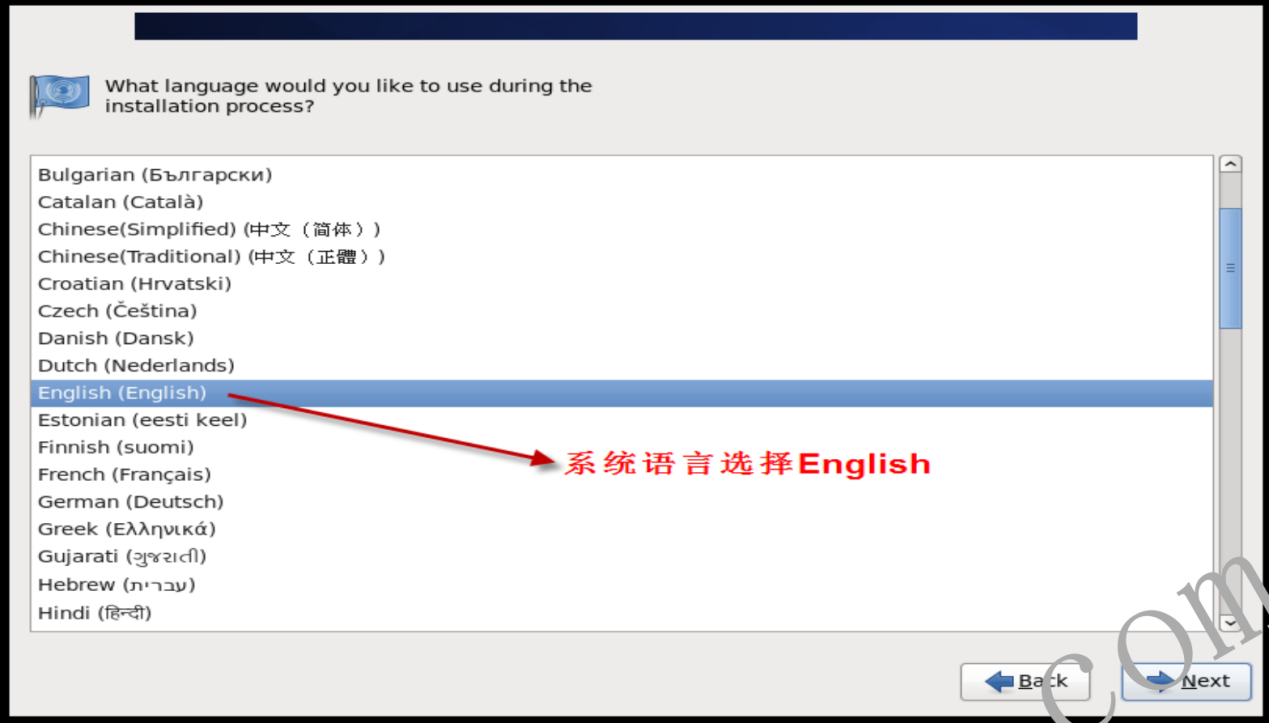
- 1.2.4 选择系统语言
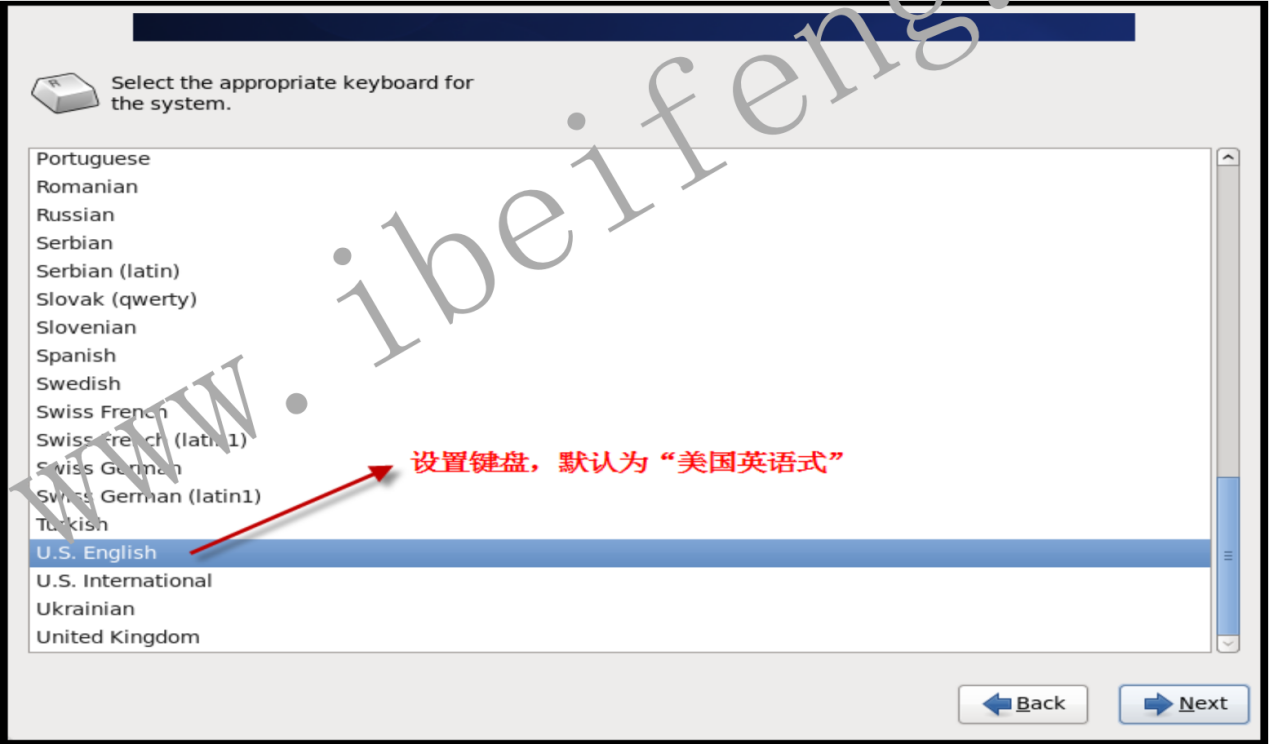
- 1.2.5 设置键盘
- 1.2.6 选择安装使用的设备,默认为“基础存储设备”

- 1.2.7 忽略存储警告
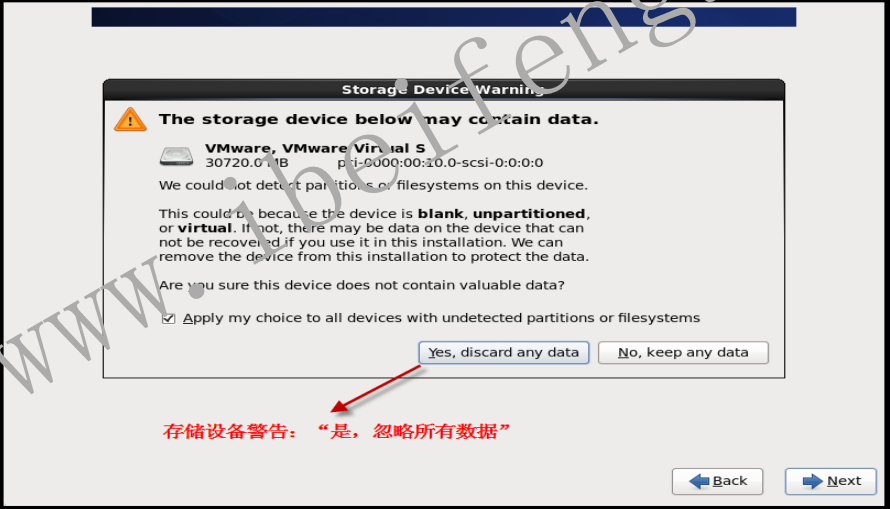
- 1.2.8 设置主机名
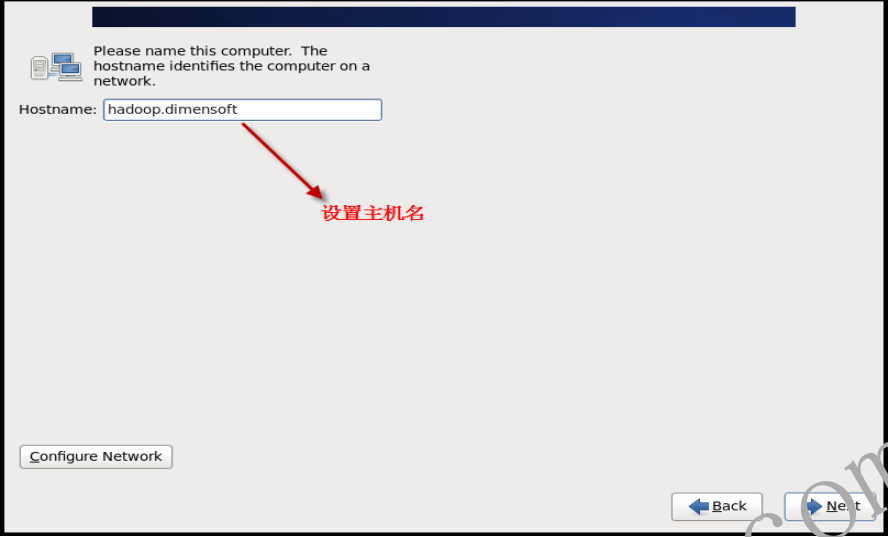
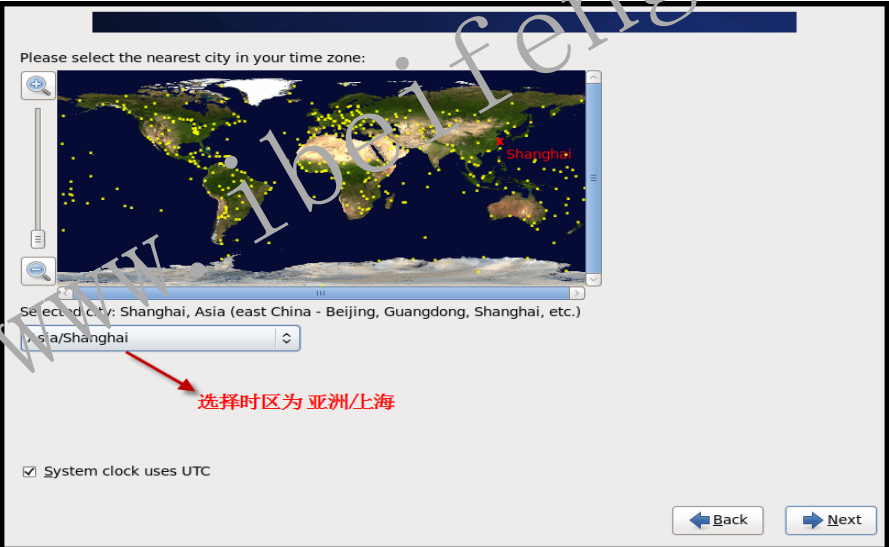
- 1.2.9 选择时区
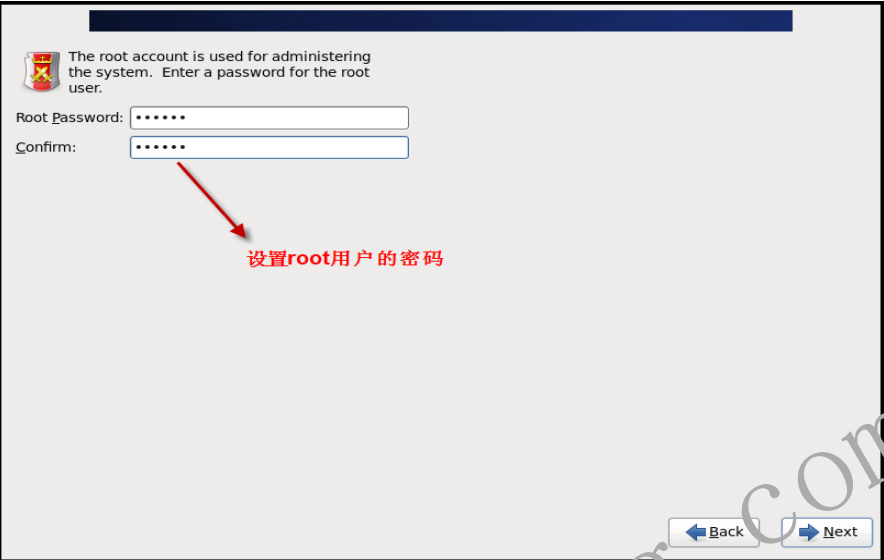
- 1.2.10 设置root用户名密码
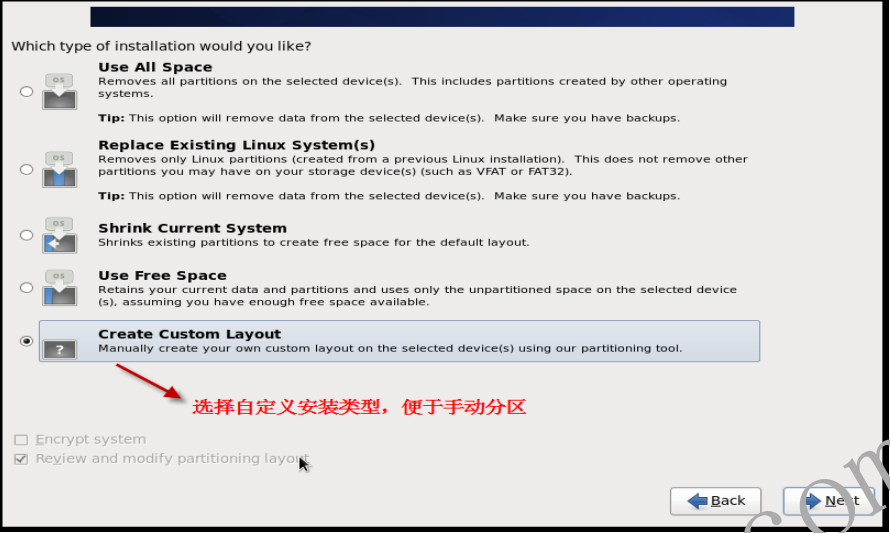
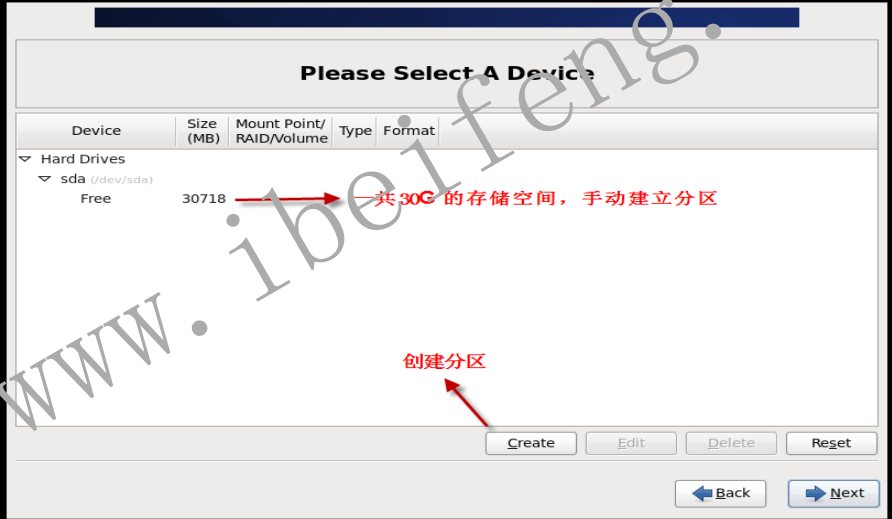
- 1.2.11 创建磁盘分区,选择自定义安装类型
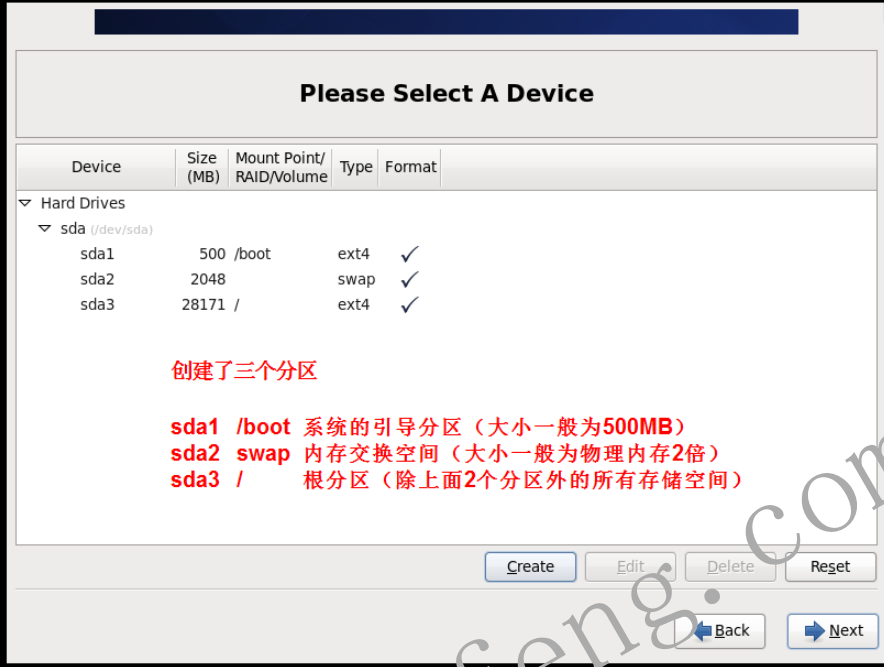
- 1.2.12 创建/boot分区
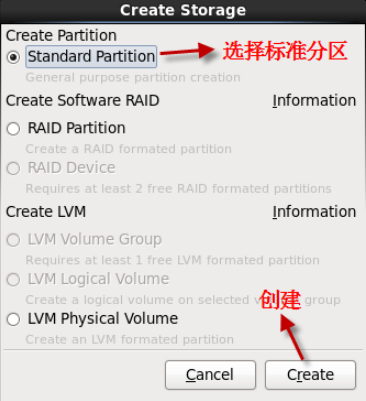
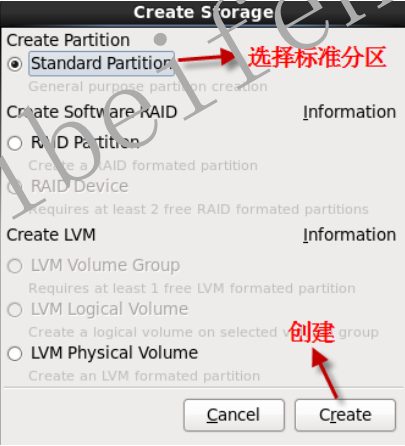
- 1.2.13 创建标准分区
- 1.2.14 分配/boot分区大小
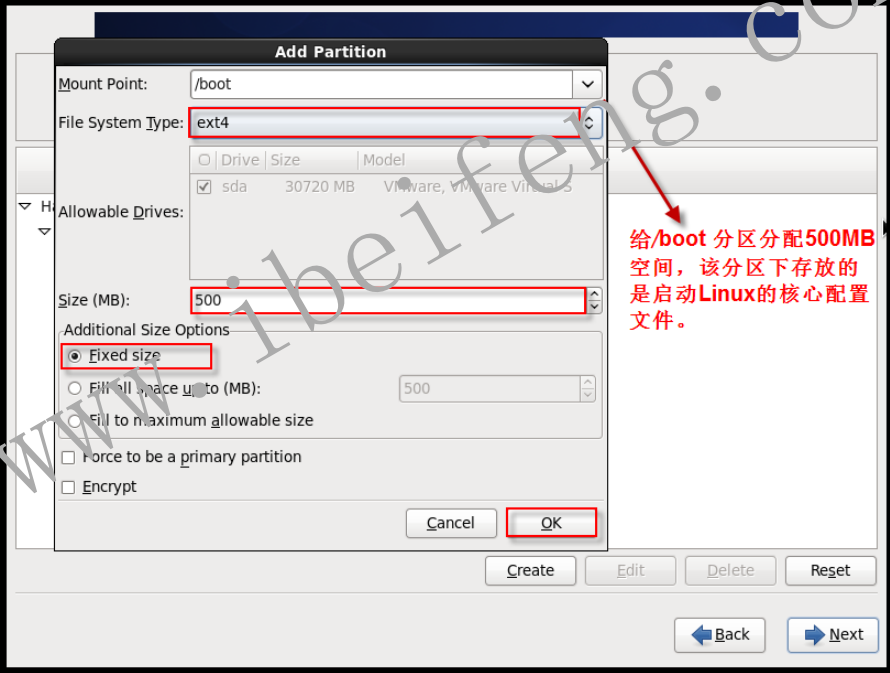
- 1.2.15 创建swap分区
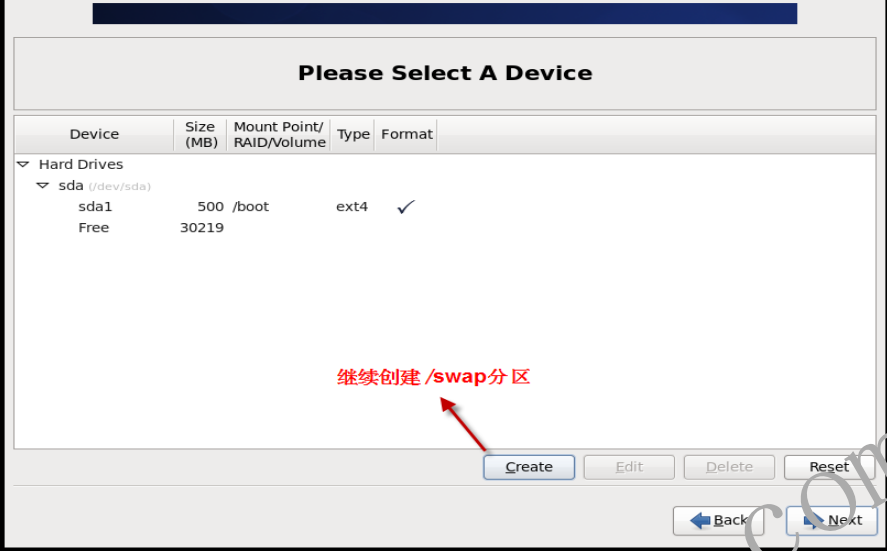
- 1.2.16 创建标准分区
- 1.2.17 分配/swap分区大小
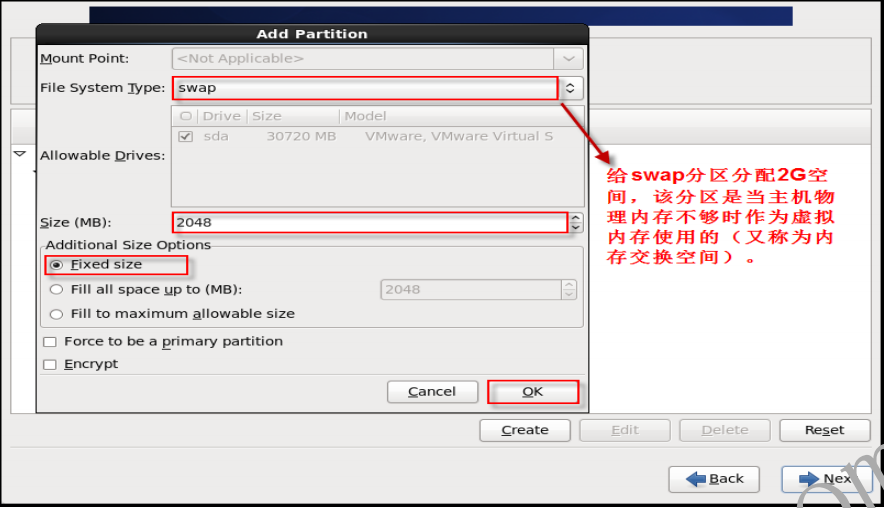
- 1.2.18 分配根目录分区
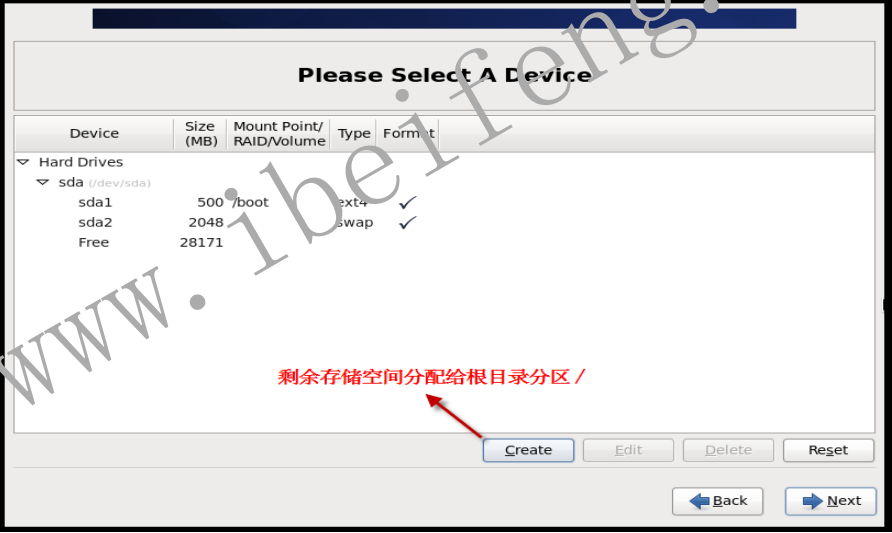
- 1.2.19 创建标准分区
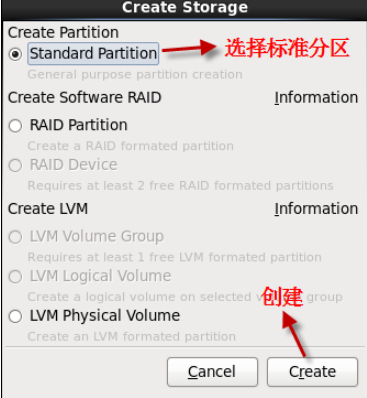
- 1.2.20 分配根目录分区大小

- 1.2.21 分区结束
- 1.2.22 格式化文件系统
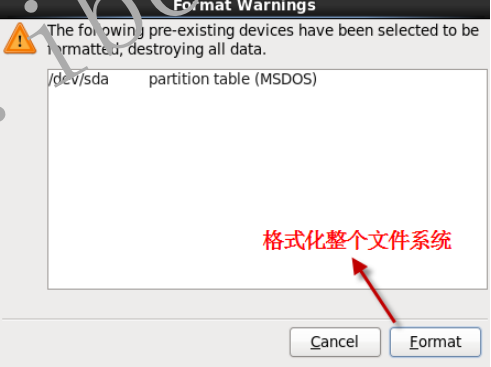
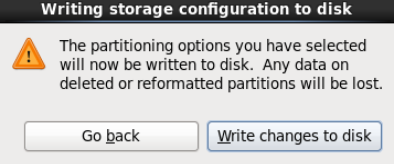
- 1.2.23 将配置写入磁盘,磁盘格式化
- 1.2.24 下一步
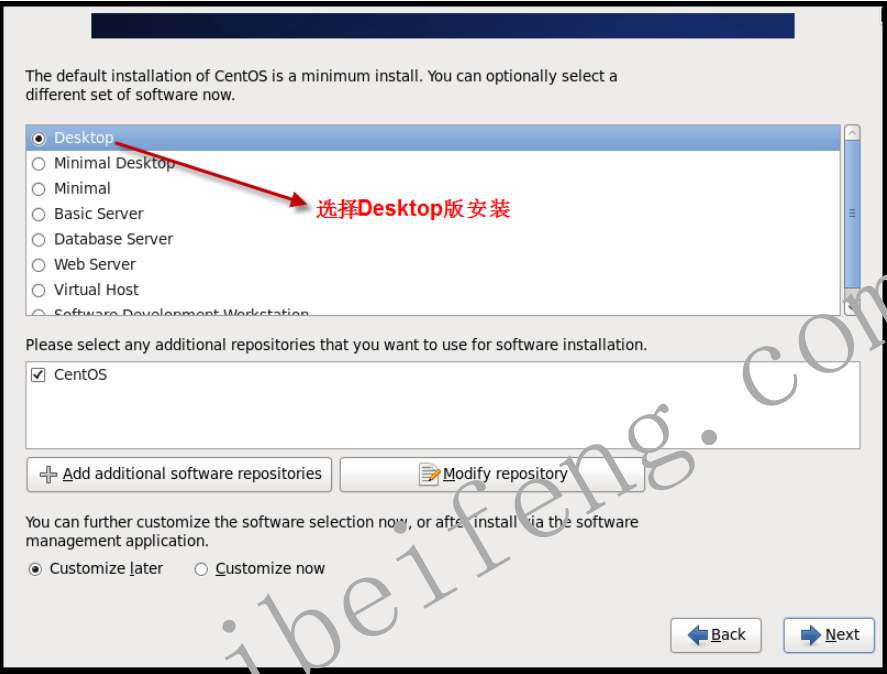
- 1.2.25 选择安装的系统版本(桌面版、最小集成版等)
- 1.2.26 等待系统安装和自动即可。
2 虚拟机统一IP
2.1 Vmware – 编辑 – 虚拟网络编辑器
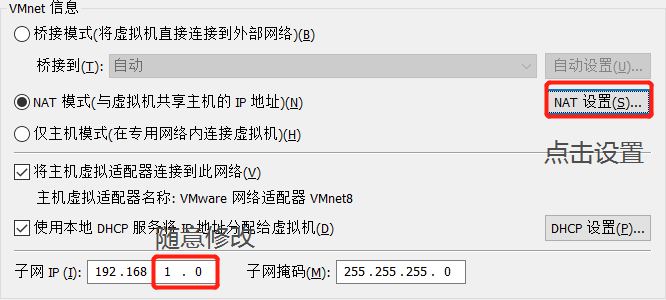
2.2 点NAT设置查看信息
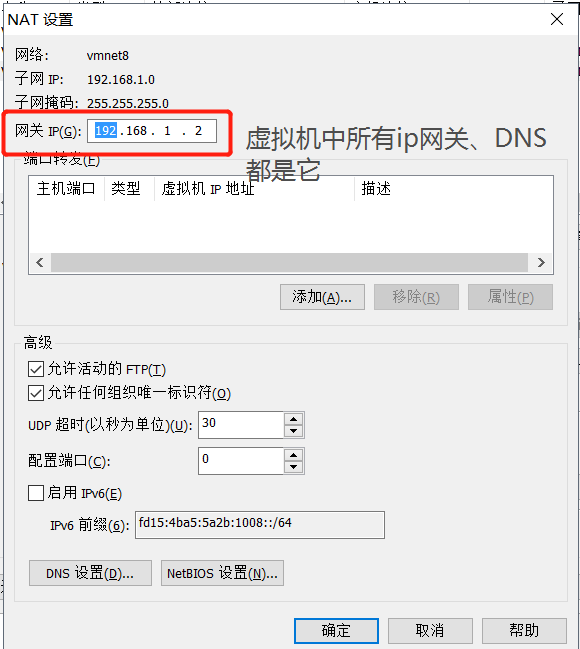
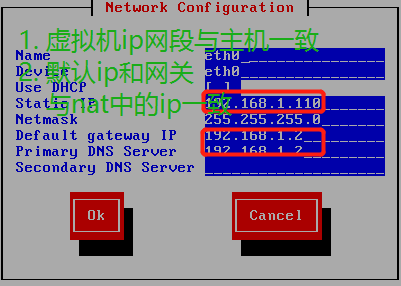
2.3 设置静态ip
虚拟机通过setup设置ip,设置静态ip,克隆虚拟机系统
-
虚拟机ip网段要同上面设置的ip网段一致
-
子网掩码统一255.255.255.0
-
默认网关ip、DNS即为第2张图,nat网关ip
-
保存关闭,ping主机和外网,若ping通,则完成,若ping不通,则往下看下一个步骤
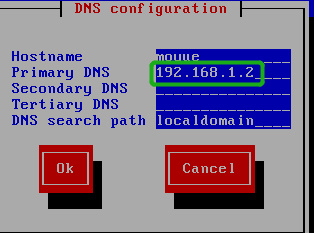
2.4 DNS配置
如果上一步还不能完成设置:setup中的DNS配置,这个配置要么与nat的ip一致,要么不写(克隆虚拟机问题)

2.5 克隆的虚拟机系统ip设置
- 直接复制要克隆的虚拟机,并在Vmware中导入并改名,名字随意
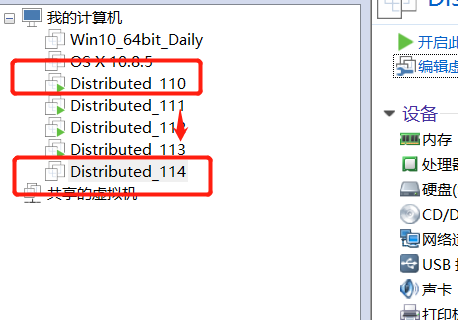
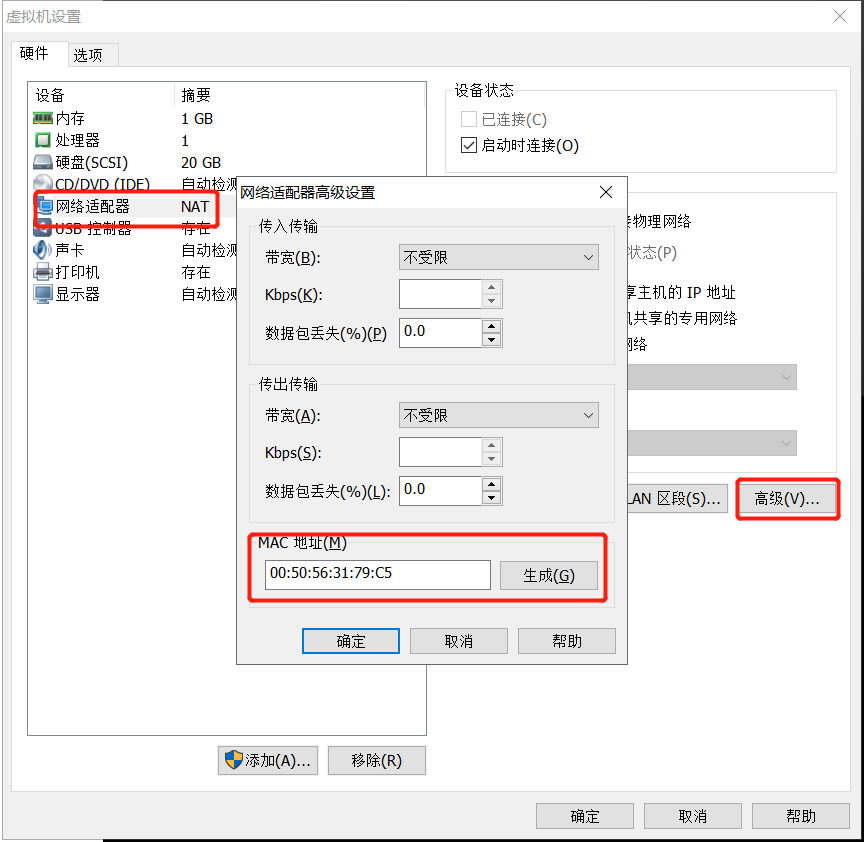
- 编辑克隆的虚拟机,修改mac地址。右键选择【设置】-【网络适配器】-【高级】,随便点几下【生成】按钮,记录一下 MAC 地址(本例:00:50:56:31:79:C5)
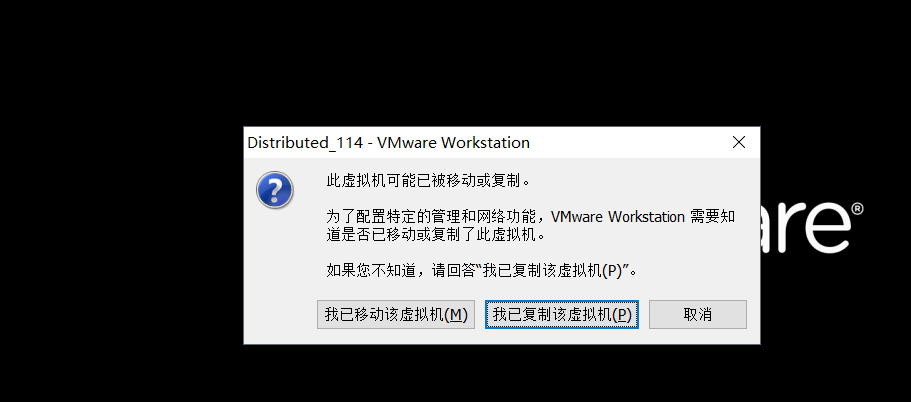
- 开机。对于使用复制方法的虚拟机,选择‘我已移动该虚拟机’或者‘我已复制该虚拟机’都可以
- setup中修改IP为我们任意自己要的IP,这里是从110 –> 114,修改静态IP的方法参照上面第3点。
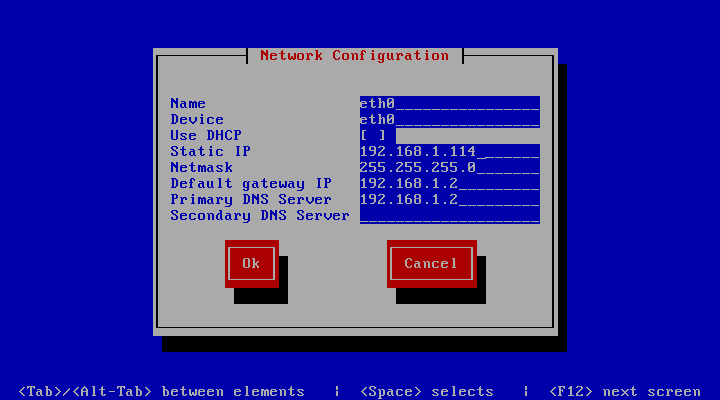
- 修改ifcfg-eth0文件,该文件所在目录/etc/sysconfig/networking/devices,如图

将网卡的mac地址修改为上面生成的00:50:56:31:79:C5
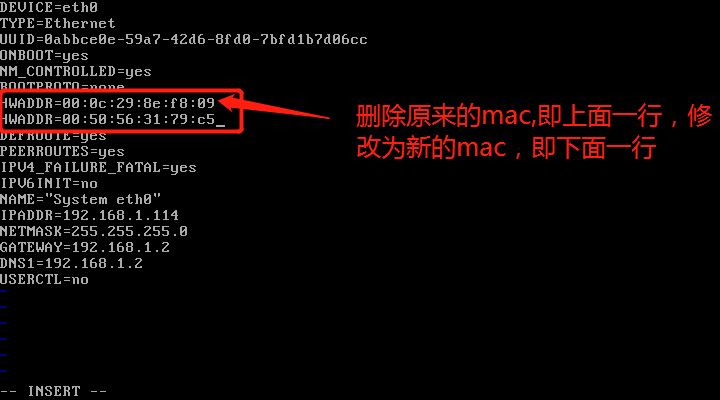
- 修改70-persistent-net.rules 文件,目录在/etc/udev/rules.d/70-persistent-net.rules,如图:

将第二个网卡,即eth1删掉,把eth0的mac地址修改为新的mac地址00:50:56:31:79:C5,保存后重启虚拟机即可
到此步,新克隆的虚拟机即可ping通主机和其他克隆机,也可以ping通外网
3 Linx安装命令
在线安装某个软件,yum install softwareName,例如: yum install gcc
新Linux系统必须安装的软件:gcc、telnet
如果要卸载,使用命令 yum remove softwareName
对于自己编写都命令,发送到linux端后,需要修改权限,才能执行 chmod 777 fileName
4 安装JDK和配置环境变量
-
解压jdk
tar zxvf jdk名 path -
配置环境变量
vi /etc/profile
shift + g定位到最后一行,在下一行插入如下代码
export JAVA_HOME=真实路径
export PATH=$PATH:$JAVA_HOME/bin
保存并退出,测试,安装成功
5 Redis软件的安装
1 首先安装GCC

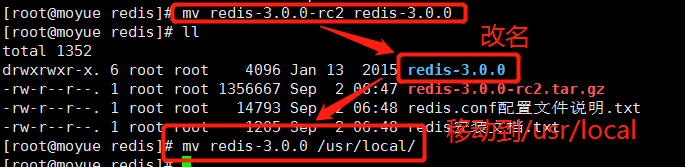
把安装包 redis-3.0.0-rc2.tar.gz 放到 /usr/local 目录下
2 解压安装包
解压 redis-3.0.0-rc2.tar.gz,并改成想要的名字,如 redis-3.0.0
tar -zxvf redis-3.0.0-rc2.tar.gz
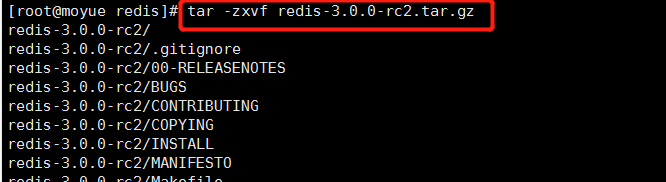

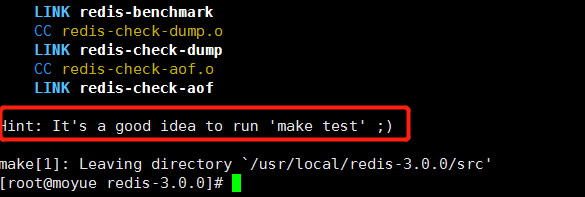
3 编译redis
进入 redis-3.0.0目录下,使用 make命令进行编译(需要系统预先安装好gcc)

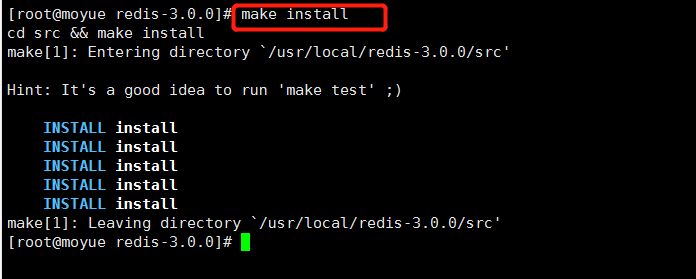
4 安装redis
使用 make install命令进行安装,安装完成后进入 bin目录下有 server和 cli即安装成功

5 保存reids目录
建立两个文件夹方便管理redis命令和配置文件,数据文件
mkdir -p /usr/local/redis/etc /*参数-p表示递归创建,etc用于存放配置文件,数据文件*/
mkdir -p /usr/local/redis/bin /*bin用于存放客户端,服务端命令文件*/

6 保存配置文件
将 redis-3.0.0/etc目录下的 redis.conf配置文件拷贝移动到 /usr/local/redis/etc下
cp redis.conf /usr/local/redis/etc

7 准备启动命令
将 redis-3.0.0/bin目录下的以下命令文件移动到 /usr/local/redis/bin下
cp mkreleasehdr.sh redis-benchmark redis-check-aof redis-check-dump redis-server redis-cli /usr/local/redis/bin

8 启动服务端
启动服务端:以指定配置文件的方式启动redis
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf

9 验证
验证启动是否成功
ps -ef |grep redis /*查看是否有redis服务*/
netstat -tunpl |grep 6379 /*查看端口*/


10 启动客户端
启动客户端: /usr/local/redis/bin/redis-cli

退出客户端: quit
11 关闭redis服务端
关闭redis服务端: kill -9 进程号(pid) 或者进入客户端,然后 shutdown
12 补充
修改配置文件 redis.conf中的参数 daemonize为yes,则以后台运行方式启动服务端

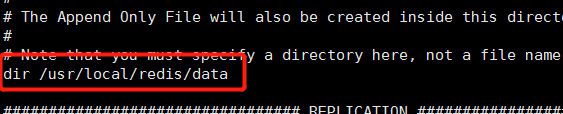
修改配置文件 redis.conf中的参数dir为 /usr/local/redis/data,将redis持久化文件保存到该目录下(提前创建好),默认(./)将数据持久化文件为服务端脚本所在目录,验证是否成功:启动服务端,再关闭,看data目录下是否生成 dump.rdb文件即可
6 Redis主从复制
1 主从复制
缓解主服务器读的压力,解决高并发读,一个Master可以有多个Slave,主节点可读可写,从节点只读不可写,当一个从节点被挂载为某个主节点上,则从节点会将主节点的持久化文件(RDB或者AOF)复制到自己的数据库保存地方上
2 准备工作
主服务器1台(安装了Redis,并保存测试数据,关闭防火墙或者开发6379端口)
从服务器n台(安装了Redis,清空存放都数据文件)
3 查看状态
首先主服务器启动redis服务,然后启动主服务器客户端并使用info命令查看当前redis服务端状态
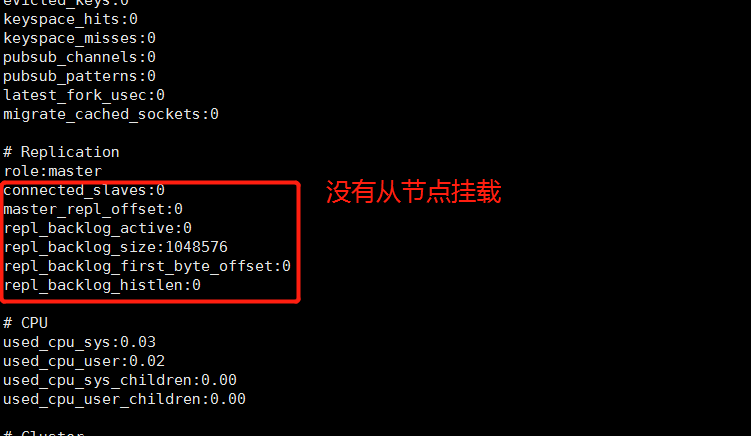
4 修改配置
其次从服务器修改 redis.conf配置文件:找到 slaveof <masterip> <masterport>,按提示添加

5 启动服务
启动从服务器,再从主节点客户端使用info命令再次查看主节点redis服务器状态
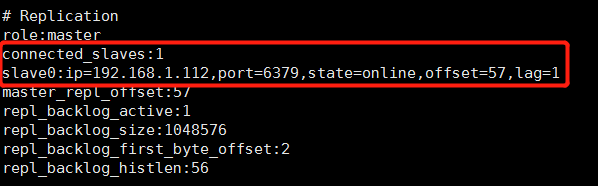
6 验证
此时进入从服务器数据存放目录,发现从服务器已经备份了主服务器的数据,表明主从复制成功,此时可以在从服务器客户端读取从主服务器自动同步过来的数据(只读,不可写)

7 总结
主从复制很简单,只需要修改从服务器 redis.conf配置文件:找到 slaveof <masterip> <masterport>,添加主服务器redis的绑定ip和端口
8 问题
Redis主从配置后,测试没有反应,两者没连上
原因:在redis主服务器上的redis.conf中bind字段,bind 127.0.0.1,被绑定到了本机,如果redis主服务器绑定了127.0.0.1,那么跨服务器IP的访问就会失败,从服务器用IP和端口访问主的时候,主服务器发现本机6379端口绑在了127.0.0.1上,也就是只能本机才能访问,外部请求会被过滤,这是Linux的网络安全策略管理的。
同理,如果bind的IP地址是172.168.10.70,那么本机通过localhost和127.0.0.1、或者直接输入命令redis-cli登录本机redis也就会失败了。只能加上本机ip才能访问到。
解决: 注释掉bind字段# bind 127.0.0.1
建议: 在研发、测试环境可以考虑bind 0.0.0.0,线上生产环境建议绑定IP地址。
7 高可用1:Redis哨兵监控
1 哨兵监控
监控主从复制的主服务器,如果主服务器宕机,则在从服务器中选举出一台升级为主服务器,原主服务器恢复使用后,会作为从服务器挂载到新主服务器上
2 准备工作
主从复制的服务器1套(4.3.2搭建的主从服务环境,假设主ip: 192.168.1.110)
哨兵服务器1台(安装了Redis,假设哨兵ip: 192.168.1.115)
3 启动主从环境
4 对于哨兵服务器
首先,Copy文件 redis3.0.0安装目录下 sentinel.conf到 /usr/local/redis/etc中
其次,修改 sentinel.conf文件:
sentinel monitor mymaster 192.168.1.110 6379 1 /*名称、ip、端口、投票选举次数*/
sentinel down-after-milliseconds mymaster 5000 /*1秒检测一次,超过5秒则认定为宕机*/
sentinel failover-timeout mymaster 900000
sentinel can-failover mymaster yes
sentinel parallel-syncs mymaster 2
之后,启动哨兵
/usr/local/redis/bin/redis-server /usr/local/redis/etc/sentinel.conf --sentinel &
之后,查看哨兵状态
/usr/local/redis/bin/redis-cli -h 192.168.1.115 -p 26379
进入客户端后: info Sentinel
5 验证
尝试关闭主服务器,再观察集群变化状况
8 高可用2:Redis+keepalive
9 Redis集群
1 Redis集群
可以解决高并发
2 准备工作
服务器1套
安装了Redis,假设主机ip: `192.168.1.110`,注意防火墙开发相应端口
拷贝集群命令文件redis-trib.rb到常用目录 /usr/local/redis/bin/
Ruby环境,集群命令文件redis-trib.rb需要Ruby环境作为支撑:
(1)yum install ruby
(2)yum install rubygems
(3)gem install redis(安装redis和ruby接口)
3 创建好目录
/usr/local/redis-cluster
/usr/local/redis-cluster/700* /*表示创建好7001-7006几个目录*/
4 准备配置文件
copy redis3.0.0目录下的redis.conf配置文件到700*目录下,并进行配置:
(1)daemonize yes
(2)port 700*
(3)bind 192.168.1.110 /*必须设置,否则运行可能会有问题*/
(4)dir /usr/local/redis-cluster/700*/ /*执行数据文件存放位置*/
(5)cluster-enabled yes /*开启集群模式*/
(6)cluster-config-file nodes700*.conf/*指定每个node配置文件,会保存其他节点信息*/
(7)cluster-node-timeout 5000
(8)appendonly yes /*开启aof,不使用rdb*/
(9)appendfsync always /*一有写操作,即开始持久化*/
5 启动redis实例
分别启动6个/usr/local/redis-cluster/700*下的redis
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/700*/redis.conf

6 集群
启动好6个实例实际上并不是集群环境,需要使用集群命令文件redis-trib.rb的相关命令进行集群操作
/usr/local/redis/bin/redis-trib.rb create --replicas 1 192.168.1.110:7001 192.168.1.110:7002 192.168.1.110:7003 192.168.1.110:7004 192.168.1.110:7005 192.168.1.110:7006
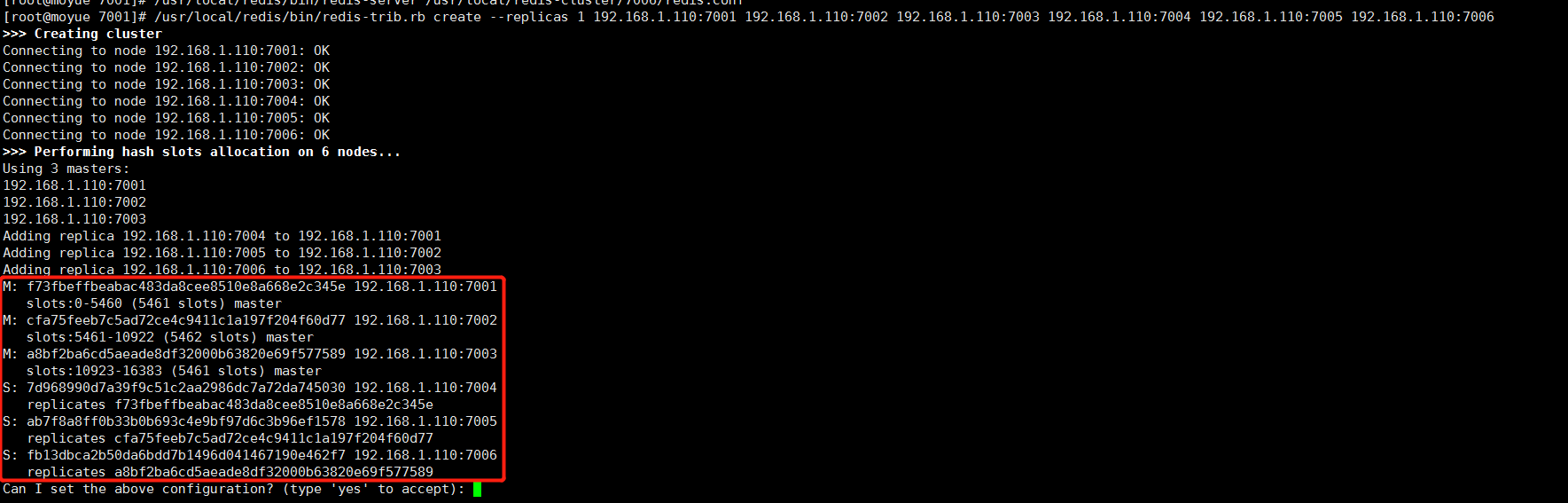
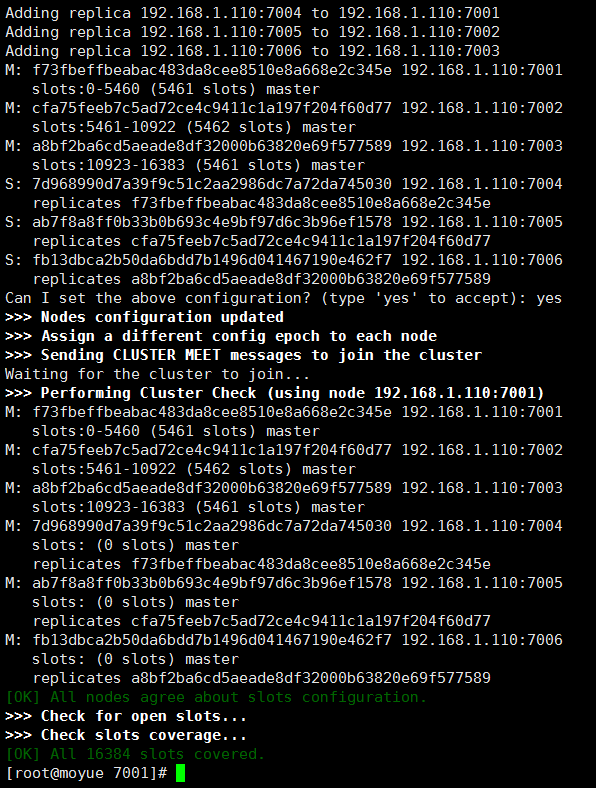
集群搭建成功
7 集群相关操作命令
开启,集群搭建完成后,只要一台一台机器的启动即可开启集群
查看状态,从任意客户端使用命令既可,cluster nodes:查看当前集群节点
(1)连接任意一个客户端即可:./redis-cli -c -h -p (-c表示集群模式,指定ip地址和端口号)如:/usr/local/redis/bin/redis-cli -c -h 192.168.1.171 -p 700*
(2)进行验证:cluster info(查看集群信息)、cluster nodes(查看节点列表)
(3)进行数据操作验证
(4)关闭集群则需要逐个进行关闭,使用命令:/usr/local/redis/bin/redis-cli -c -h 192.168.1.171 -p 700* shutdown
7.1 数据验证:
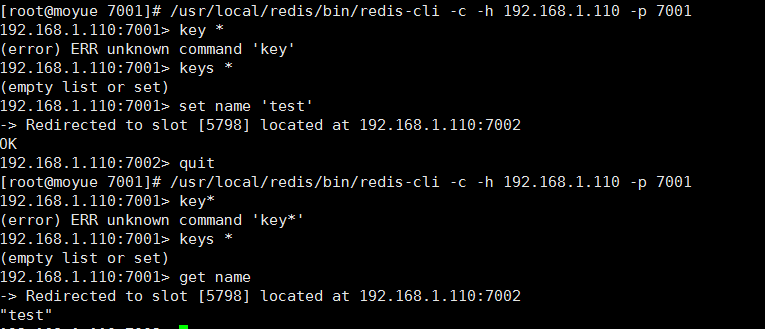
按顺序仔细看上图每条命令,包括命令执行的目录
(1)登陆7001客户端,查看到没有数据
(2)存数据,可以看到数据被存到7002节点,并且客户端自动转入7002客户端
(3)退出7002客户端,重新登陆7001客户端
(4)查看数据,可以看到7001仍然没有数据
(5)在7001客户端获取数据,可以看到数据被获得
由以上几步可以看出,向某主节点存数据,会自动转到其他节点,虽然某节点没有数据,但是其他节点有数据仍然可以被获得,这就是集群。
8 redis-trib.rb的命令
1 create:创建一个集群环境host1:port1 ... hostN:portN(集群中的主从节点比例)
2 call:可以执行redis命令
3 add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
4 del-node:移除一个节点
5 reshard:重新分片
6 check:检查集群状态
9 添加主节点
- 1 使用add-node命令:绿色为新增节点,红色为已知存在节点
/usr/local/redis3.0/src/redis-trib.rb add-node 192.168.1.171:7007 192.168.1.171:7001
- 2 手工分配slot槽
/usr/local/redis3.0/src/redis-trib.rb reshard 192.168.1.171:7001
(提示一)
How many slots do you want to move (from 1 to 16384)? 200
(提示二)
What is the receiving node ID? 382634a4025778c040b7213453fd42a709f79e28
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
(提示三)
Do you want to proceed with the proposed reshard plan (yes/no)? yes
1 提示一:是希望你需要多少个槽移动到新的节点上,可以自己设置,比如200个槽。
2 提示二:是你需要把这200个slot槽移动到那个节点上去(需要指定节点id),并且下个提示是输入all为从所有主节点(7001 7002 7003)中分别抽取响应的槽数(一共为200个槽到指定的新节点中!,并且会打印执行分片的计划。)
3 提示三:输入yes确认开始执行分片任务。
- 3 已经加入到集群中
10 添加从节点
1 同添加主节点的第一步,先将要加入集群的从节点加入集群
/usr/local/redis3.0/src/redis-trib.rb add-node 192.168.1.171:7008 192.168.1.171:7001
2 我们需要执行replicate命令来指定当前节点(从节点)的主节点id为哪个。
首先需要登录新加的7008节点的客户端,然后使用集群命令进行操作,把当前的7008(slave)节点指定到一个主节点下(这里使用之前创建的7007主节点,红色表示节点id)
/usr/local/redis/bin/redis-cli -c -h 192.168.1.171 -p 7008
192.168.1.171:7008> cluster replicate 382634a4025778c040b7213453fd42a709f79e28
192.168.1.171:7008> OK(提示OK则操作成功)
3 到此为止已经成功的添加完一个从节点了
11 删除从节点
删除从节点7008,输入del-node命令,指定删除节点ip和端口,以及节点id(红色为7008节点id)
/usr/local/redis3.0/src/redis-trib.rb
del-node 192.168.1.171:7008 97b0e0115326833724eb0ffe1d0574ee34618e9f
12 删除主节点
1 删除7007(master)节点之前,我们需要先把其全部的数据(slot槽)移动到其他节点上去(目前只能把master的数据迁移到一个节点上,暂时做不了平均分配功能)
/usr/local/redis3.0/src/redis-trib.rb reshard 192.168.1.171:7007
How many slots do you want to move (from 1 to 16384)? 199
(注释:这里不会是正好200个槽)
What is the receiving node ID? 614d0def75663f2620b6402a017014b57c912dad
(注释:这里是需要把数据移动到哪?7001的主节点id)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:382634a4025778c040b7213453fd42a709f79e28
(注释:这里是需要数据源,也就是我们的7007节点id)
Source node #2:done
(注释:这里直接输入done 开始生成迁移计划)
2 最后我们直接使用del-node命令删除7007主节点即可(红色表示7007的节点id)。
/usr/local/redis3.0/src/redis-trib.rb del-node
192.168.1.171:7007 382634a4025778c040b7213453fd42a709f79e28
13 删除整个集群
把所有集群环境下的nodes700*.conf删除即可,只要存在一个该配置文件,则集群删除失败,无法再创建集群。
14 集群无法启动问题
当出现集群无法启动时,删除临时的数据文件(nodes700*.conf),再次重新启动每一个redis服务,然后重新构造集群环境
15 Redis配置文件redis.conf参数介绍
# Redis 配置文件
# 当配置中需要配置内存大小时,可以使用 1k, 5GB, 4M 等类似的格式,其转换方式如下(不区分大小写)
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
# 内存配置大小写是一样的.比如 1gb 1Gb 1GB 1gB
# daemonize no 默认情况下,redis不是在后台运行的,如果需要在后台运行,把该项的值更改为yes
daemonize yes
# 当redis在后台运行的时候,Redis默认会把pid文件放在/var/run/redis.pid,你可以配置到其他地址。
# 当运行多个redis服务时,需要指定不同的pid文件和端口
pidfile /var/run/redis.pid
# 指定redis运行的端口,默认是6379
port 6379
# 指定redis只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求,
# 在生产环境中最好设置该项
# bind 127.0.0.1
# 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
# 0是关闭此设置
timeout 0
# 指定日志记录级别
# Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
# debug 记录很多信息,用于开发和测试
# varbose 有用的信息,不像debug会记录那么多
# notice 普通的verbose,常用于生产环境
# warning 只有非常重要或者严重的信息会记录到日志
loglevel debug
# 配置log文件地址
# 默认值为stdout,标准输出,若后台模式会输出到/dev/null
#logfile stdout
logfile /var/log/redis/redis.log
# 可用数据库数
# 默认值为16,默认数据库为0,数据库范围在0-(database-1)之间
databases 16
# 保存数据到磁盘,格式如下:
# save <seconds> <changes>
# 指出在多长时间内,有多少次更新操作,就将数据同步到数据文件rdb。
# 相当于条件触发抓取快照,这个可以多个条件配合
# 比如默认配置文件中的设置,就设置了三个条件
# save 900 1 900秒内至少有1个key被改变
# save 300 10 300秒内至少有300个key被改变
# save 60 10000 60秒内至少有10000个key被改变
save 900 1
save 300 10
save 60 10000
# 存储至本地数据库时(持久化到rdb文件)是否压缩数据,默认为yes
rdbcompression yes
# 本地持久化数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
# 工作目录
# 数据库镜像备份的文件放置的路径。
# 这里的路径跟文件名要分开配置是因为redis在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,
# 再把该该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中。
# AOF文件也会存放在这个目录下面
# 注意这里必须制定一个目录而不是文件
dir ./
# 主从复制. 设置该数据库为其他数据库的从数据库.
# 设置当本机为slave服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
# slaveof <masterip> <masterport>
# 当master服务设置了密码保护时(用requirepass制定的密码)
# slav服务连接master的密码
# masterauth <master-password>
# 当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:
# 1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续相应客户端的请求
# 2) 如果slave-serve-stale-data是指为no,出去INFO和SLAVOF命令之外的任何请求都会返回一个
# 错误"SYNC with master in progress"
# slave-serve-stale-data yes
# 从库会按照一个时间间隔向主库发送PINGs.可以通过repl-ping-slave-period设置这个时间间隔,默认是10秒
# repl-ping-slave-period 10
# repl-timeout 设置主库批量数据传输时间或者ping回复时间间隔,默认值是60秒
# 一定要确保repl-timeout大于repl-ping-slave-period
# repl-timeout 60
# 设置客户端连接后进行任何其他指定前需要使用的密码。
# 警告:因为redis速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解
# requirepass foobared
# 命令重命名.
# 在一个共享环境下可以重命名相对危险的命令。比如把CONFIG重名为一个不容易猜测的字符。举例: rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
# 如果想删除一个命令,直接把它重命名为一个空字符""即可,如下:
# rename-command CONFIG ""
# 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,
# 如果设置maxclients 0,表示不作限制。
# 当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients
reached错误信息
# maxclients 128
# 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key
# Redis同时也会移除空的list对象
# 当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作
# 注意:Redis新的vm机制,会把Key存放内存,Value会存放在swap区
# maxmemory的设置比较适合于把redis当作于类似memcached的缓存来使用,而不适合当做一个真实的DB。
# 当把Redis当做一个真实的数据库使用的时候,内存使用将是一个很大的开销
# maxmemory <bytes>
# 默认情况下,redis会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。
# 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。
# 开启appendonly模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态。
# 但是这样会造成appendonly.aof文件过大,所以redis还支持了BGREWRITEAOF指令,对appendonly.aof 进行重新整理。
# 你可以同时开启asynchronous dumps 和 AOF
appendonly no
# AOF文件名称 (默认: "appendonly.aof")
# appendfilename appendonly.aof
# Redis支持三种同步AOF文件的策略:
# no: 不进行同步,系统去操作 . Faster.
# always: always表示每次有写操作都进行同步. Slow, Safest.
# everysec: 表示对写操作进行累积,每秒同步一次.
# 默认是"everysec",按照速度和安全折中这是最好的。
# 如果想让Redis能更高效的运行,你也可以设置为"no",让操作系统决定什么时候去执行
# 或者相反想让数据更安全你也可以设置为"always"
# 如果不确定就用 "everysec".
# appendfsync always
# appendfsync everysec
# appendfsync no
# AOF策略设置为always或者everysec时,后台处理进程(后台保存或者AOF日志重写)会执行大量的I/O操作
# 在某些Linux配置中会阻止过长的fsync()请求。注意现在没有任何修复,即使fsync在另外一个线程进行处理
# 为了减缓这个问题,可以设置下面这个参数no-appendfsync-on-rewrite
durability.no-appendfsync-on-rewrite no
# AOF 自动重写,Automatic rewrite of the append only file
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写
# 它是这样工作的:Redis会记住上次进行些日志后文件的大小(如果从开机以来还没进行过重写,那日子大小在开机的时候确定)
# 基础大小会同现在的大小进行比较。如果现在的大小比基础大小大制定的百分比,重写功能将启动
# 同时需要指定一个最小大小用于AOF重写,这个用于阻止即使文件很小但是增长幅度很大也去重写AOF文件的情况
# 设置 percentage 为0就关闭这个特性
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# Redis Slow Log 记录超过特定执行时间的命令。执行时间不包括I/O计算比如连接客户端,返回结果等,只是命令执行时间
# 可以通过两个参数设置slow log:一个是告诉Redis执行超过多少时间被记录的参数slowlog-log-slower-than(微妙),
# 另一个是slow log 的长度。当一个新命令被记录的时候最早的命令将被从队列中移除
# 下面的时间以微妙微单位,因此1000000代表一分钟。
# 注意制定一个负数将关闭慢日志,而设置为0将强制每个命令都会记录
slowlog-log-slower-than 10000
# 对日志长度没有限制,只是要注意它会消耗内存
# 可以通过 SLOWLOG RESET回收被慢日志消耗的内存
slowlog-max-len 1024
# 当hash中包含超过指定元素个数并且最大的元素没有超过临界时,
# hash将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值
# Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,
# 这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value
redisObject的encoding为zipmap,
# 当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
# list数据类型多少节点以下会采用去指针的紧凑存储格式。
# list数据类型节点值大小小于多少字节会采用紧凑存储格式。
list-max-ziplist-entries 512
list-max-ziplist-value 64
# set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储。
set-max-intset-entries 512
# zsort数据类型多少节点以下会采用去指针的紧凑存储格式。
# zsort数据类型节点值大小小于多少字节会采用紧凑存储格式。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用
# 当你的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置为no。
# 如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存
activerehashing yes
# 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
# include /path/to/local.conf
# include /path/to/other.conf
10 MongoDB软件的安装
-
1 上传安装包并解压,将解压出来的目录重命名为mongodb
-
2 将mongodb目录移动到/usr/local/下
-
3 进入mongodb目录,mkdir db创建一个目录来存放数据,mkdir logs来存放日志
-
4 修改mongodb.conf参数
| 参数 | 描述 |
|---|---|
| dbpath=/usr/local/mongodb/db | 数据存放目录 |
| logpath=/usr/local/mongodb/logs/mongodb.log | 日志存放目录 |
| port=27017 | 指定端口 |
| fork=true | 后台启动 |
| nohttpinterface=true | web界面不让打开查看 |
- 5 设置开机启动
vi /etc/rc.d/rc.local
/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/config/mongodb.conf
- 6 关机重启后删除lock文件
rm -rf /usr/local/mongodb/db/mongod.lock
11 Nginx
- 1 安装编译需要的依赖库
yum install pcre
yum install pcre-devel
yum install zlib
yum install zlib-devel
- 2 解压文件:
tar -zxvf nginx-1.6.2.tar.gz,拷贝到/usr/local/目录,得到nginx-1.6.2目录
cd /usr/local/nginx 目录下: 看到如下4个目录
| 目录 | 描述 |
|---|---|
| conf | 配置文件 |
| html | 网页文件 |
| logs | 日志文件 |
| sbin | 主要二进制程序 |
- 3 在
nginx-1.6.2目录进行configure配置:./configure --prefix=/usr/local/nginx得到
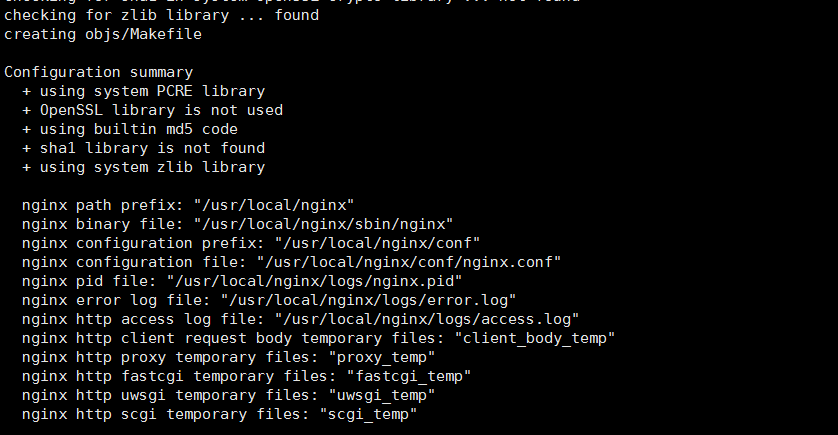
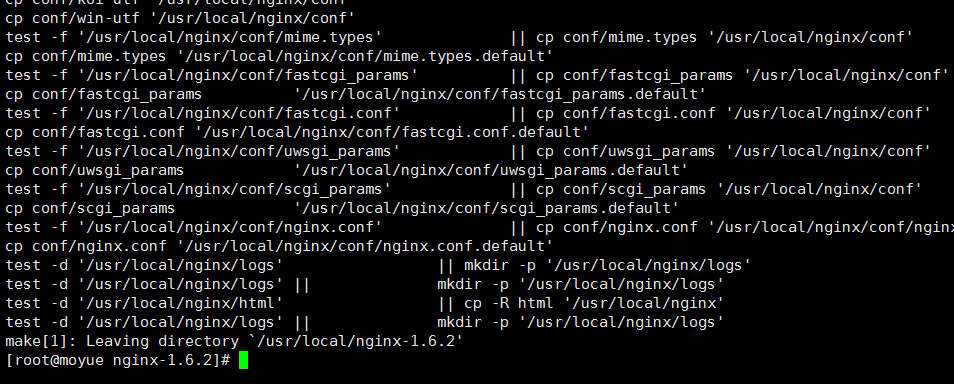
- 4 在nginx-1.6.2目录编译安装
make && make install,得到
- 5 启动Nginx
启动命令: /usr/local/nginx/sbin/nginx
关闭命令: /usr/local/nginx/sbin/nginx -s stop
重启命令: /usr/local/nginx/sbin/nginx -s reload
成功:查看是否启动 `netstat -ano | grep 80
失败:可能为80端口被占用等
- 6 验证
浏览器访问地址:http://192.168.1.110 (看到欢迎页面即可)
- 7 整合示例
修改nginx.conf文件
vim /usr/local/nginx/conf/nginx.conf
server {
listen 80;
server_name localhost:80;
location / {
proxy_pass http://localhost:8080;
}
}
- 8 Nginx配置文件
#错误日志保存位置
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#进程号保存文件
#pid logs/nginx.pid;
#设定负载均衡的服务器列表
#weigth参数表示权值,权值越高被分配到的几率越大
#max_fails 当有#max_fails个请求失败,就表示后端的服务器不可用,默认为1,将其设置为0可以关闭检查
#fail_timeout 在以后的#fail_timeout时间内nginx不会再把请求发往已检查出标记为不可用的服务器
#这里指定多个源服务器,ip:端口,80端口的话可写可不写
upstream myproject {
server 192.168.1.78:8080 weight=5 max_fails=2 fail_timeout=600s;
#server 192.168.1.222:8080 weight=3 max_fails=2 fail_timeout=600s;
}
server {
#监听IP端口
listen 80;
#主机名
server_name localhost;
#设置字符集
#charset koi8-r;
#本虚拟server的访问日志 相当于局部变量
#access_log logs/host.access.log main;
#对本server"/"启用负载均衡
location / {
#root /root; #定义服务器的默认网站根目录位置
#index index.php index.html index.htm; #定义首页索引文件的名称
proxy_pass http://myproject; #请求转向myproject定义的服务器列表
#以下是一些反向代理的配置可删除.
# client_max_body_size 10m; #允许客户端请求的最大单文件字节数
# client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数,
# proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时)
# proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时)
# proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收超时)
# proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息的缓冲区大小
# proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以下的话,这样设置
# proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2)
# proxy_temp_file_write_size 64k; #设定缓存文件夹大小,大于这个值,将从upstream服务器传
}
}

