Redis@Redis
redis持久化的意义当然是 故障恢复,
当遇到为什么要用的问题时候,想一想没有用的场景怎么样,再想一想用了的场景怎么样
- 如果redis不做持久化,它是保存在内存中的,如果机器宕机了,数据就直接没有了,要恢复数据,只能大批量的读取数据库数据,这样的动作很慢,增大了数据库的压力。因此,不做持久化处理,是无法应对灾难性的故障的
- 如果做持久化,当机器宕机恢复后,无需从数据库重新读取数据,直接从持久化文件读取恢复即可
RDB: 每隔一段时间(几分钟,几小时),生成内存中数据的一份快照
AOF: 只要数据有变化,就将内存数据写入日志文件中,通过日志文件进行恢复
-
扩展性
- 数据库存储空间不够的使用,追加新的存储空间
- 水平扩展: 直接往主节点中添加一个新的主结点
- 垂直扩展: 直接增加主结点的空间内存,而不是追加新节点
-
高可用
- 采用水平扩展的时候,如果某一主节点挂掉,则将该节点下的从节点挂载到与该主节点联系的其他主节点上,然后等该挂掉的主节点修复完成,再将原先的子节点重新挂载回本主节点即可。这样保证了局部的节点挂掉,服务也能正常提供,不会影响
-
非关系型数据库
- key-value型,由hash表中一个键和一个指针指向特定的数据
代表: Redis/Voldemort/Oracle BDB - 列存储,用于应对分布式存储的海量数据,键仍存在,但指向多列数据
代表: HBase/Riak - 文档型,数据模型是版本化的文档,半结构化的文档以特定格式存储,如JSON
文档型数据库可以看作是key-value型的升级版,允许嵌套键值,查询效率也比key-value更高
代表: CouchDB/MongoDB - 图形数据库,图形结构的数据库使用灵活的图形模型,能扩展到多个服务器上,NoSQL数据库没有标准的查询语言
(SQL),因此进行数据库查询需要定制数据模型,许多NoSQL数据库都有REST式的数据接口或者查询API,如Neo4J/
InfoGrid/Infinite Graph
- key-value型,由hash表中一个键和一个指针指向特定的数据
-
Redis的安装与部署
- 安装步骤:
- 首先需要安装GCC,
- 把下载好的redis-3.0.0-rc2.tar.gz放到linux/usr/local文件夹下
- 解压tar -zxvf redis-3.0.0-rc2.tar.gz
- 进入到redis-3.0.0目录,进行编译make
- 进入到src目录下,安装make install 验证(II查看src下的目录,有redis-server/redis-cil即可)
- 建立两个文件夹存放redis命令和配置文件
mkdir -p /usr/local/redis/etc
mkdir -p /usr/local/redis/bin - 把redis-3.0.0下的redis.conf移动到/usr/local/redis/etc目录下
cp redis.conf /usr/local/redis/etc - 把redis-3.0.0/src里的mkreleasehdr.sh/redis-benchmark/redis-check-aof/redis-check-dump/redis-cli/redis-server文件移动到bin下
mv mkreleasehdr.sh redis-benchmark redis-check-aof redis-check-dump redis-cli/redis-server /usr/local/redis/bin - 启动时指定配置文件
./redis-server /usr/local/redis/etc/redis.conf(注意使用后台启动,即修改redis.conf里的9 daemonize改为yes) - 验证启动是否成功
ps -ef|grep redis 查看是否由redis服务或者查看端口,netstart -tunpl|grep 6379
进入redis客户端,./redis -cli 退出客户端 quit
退出redis服务
(1)pkill redis-server
(2)kill 进程号
(3)/usr/local/redis/bin/redis-cli shutdown
-
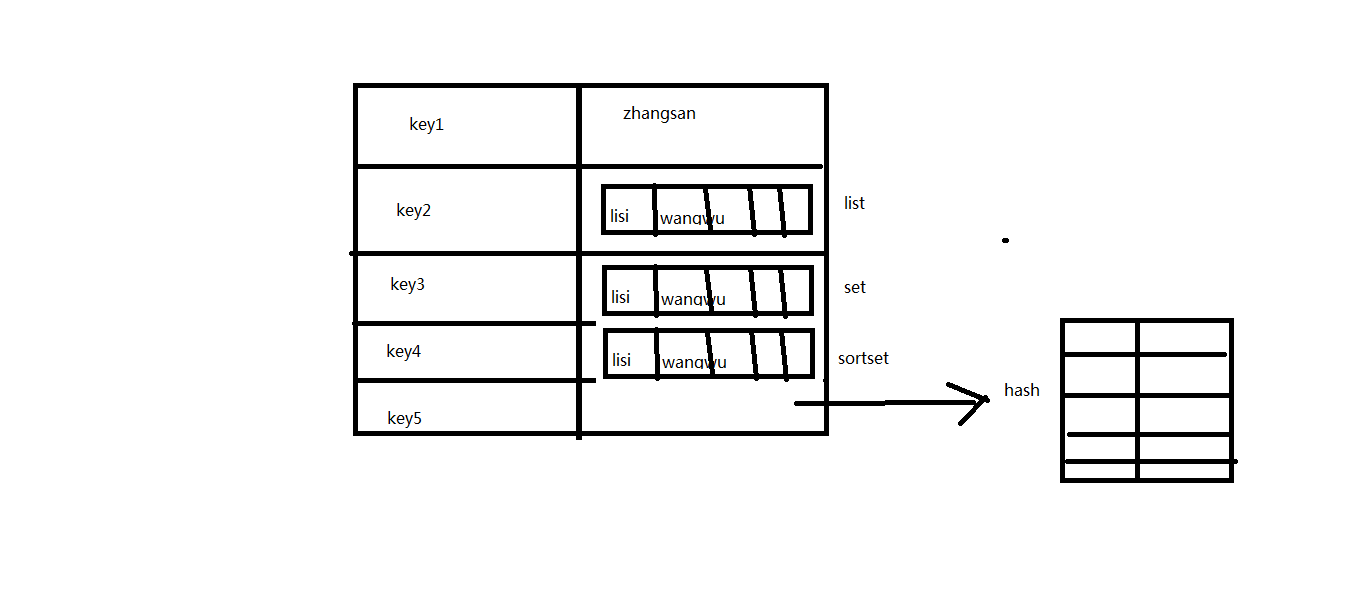
基础数据类型
-
高级命令
-
Redis与Java的使用
-
Redis集群搭建
- Redis的集群策略
- 主从形式
- 哨兵形式
- 集群模式
- Redis的集群策略
-
Redis集群与Spring的整合、TomcatRedis的Session共享