
python之模块
一、模块的介绍
(1)python模块,是一个python文件,以一个.py文件,包含了python对象定义和pyhton语句
(2)python对象定义和python语句
(3)模块让你能够有逻辑地组织你的python代码段。
(4)把相关的代码分配到一个模块里能让你的代码更好用,更易懂
(5)模块能定义函数,类和变量,模块里也能包含可执行的代码
二、模块的导入
注意点:
(1)一个模块只要导入一次,不管你执行多少次import,一次就可以
(2)模块不调用时是置灰状态
1、
格式:import 模块名
使用:模块名.函数名
案例:
import time
print(1)
time.sleep(5) #休眠
print(2)
2、from 包名.模块名 import * (表示所有的函数)
from bao.aa import *
3、from 包名.模块名 import 函数名 (表示所有的函数)
4、通过取别名来调用函数
格式:from 模块名 import 函数名 as 别名
模块讲解:一、time模块
import time
1970年到现在经过的秒数
print(time.time()) #1651200498.799537
print(time.ctime()) #固定格式的当前时间
time.sleep(3)) # 休眠,也是强制等待
print(time.asctime()) #转化为asc码显示当前时间
print(time.strftime(“%H-%M-%S %y-%m-%d”)) #时间戳:按照格式输出内容:
二、random模块
生成随机浮点数,帧数,字符串,甚至帮助你随机选择列表中的一个元素,打乱一组数据等;
from random import *
print(random()) #生成0-1之间的浮点数,但是能取到0,不能取到1
print(randint(1,100)) #生成指定范围内整数,包括开始值和结束值
print(randrange(1,100,2)) # 生成指定范围内的奇数
print(randrange(0,100,2)) #生成指定范围内的偶数
f=[1,2,3,6,7,2]
print(sample(f,3)) #生成从一个固定集合中选n个数随机
print(choice(f)) #随机生成一个字符
shuffle(f)
print(list(f))
string 模块
print(string.digits) #0123456789 所有的数据
print(string.hexdigits) #0123456789abcdefABCDEF
print(string.ascii_uppercase) #ABCDEFGHIJKLMNOPQRSTUVWXYZ #所有的小写
print(string.ascii_lowercase) #abcdefghijklmnopqrstuvwxyz #所有小写
print(string.ascii_letters) #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ #所有的大小写print(string.ascii_letters+string.digits) #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 #所有大小写,字母和数字
加密模块:
import hashlib
base64
MD5
一、加密算法
md5、rsa、AES ,DES.BASE
DES 以64位为分组队数据加密,加密和解密是同一算法‘;
rsa加密 算法:是一种非对称加密算法(在公开秘钥加密和电子商业中rsa被广泛使用)
AES rijndael 加密法对称加密中最流行的算法之一(AES为分组密码)
案例:
base64加密
import base64
a=base64.b64encode(b"123456")
print(a) #b’MTIzNDU2’
base64解密
b=base64.b64decode(b"MTIzNDU2")
print(b) #b’123456’
备注:base64 编码包含ascll是包含字符,二是二进制数据
http://encode.chahuo.com/ 在线加解密
MD5加密
(1)md5 是一种算法,可以将一个字符串或文件,md5后,就可以生成一个固定为128bit的串,这个串,基本上唯一;
(2)python2中有md5
(3)python3将MD5 归纳到hash 模块,译作:‘散列’,直译为‘哈希’。
(4)md5 可以把任意长度的输入,通过种hash算法,变换成固定长度的输出,该输出就是散列值,也称摘要值,,该算法就是哈希函数,也称摘要函数。
(5)md5 是最常见的摘要算法,速度快,生成结果是固定16字节,通常用32位的16进制字符串表示。
(5)hash模块中包含MD5、sha1 ,sha256 ,sha512,等
(6)摘要;hash.digest() 返回摘要,作为二进制数据字符串值;
hash.hexdigeest 返回摘要,作为16进制数据字符串值
(7)案例1:
import hashlib
m=hashlib.md5() # 创建MD5对象
m.update(b"123456")
print(m.hexdigest()) #e10adc3949ba59abbe56e057f20f883e
十六直径转换输出
备注:
1、python中md5要加上b,python2不需要
2、md5 不能解密,但是加密是固定,关系是一一对应,可以被对撞。
案例1
import hashlib
m=hashlib.sha384()
m.update(b’123456’)
print(m.hexdigest())
案例2
import hashlib
m=hashlib.sha256()
m.update(b’123456’)
print(m.hexdigest())
案例:
import hashlib
m=hashlib.sha512()
m.update(b’123456’)
print(m.hexdigest())
-==================================
面试题:
(1)如果在工作中有很多数据,如果数据被改动,或传递别修改,看不出?
a、通过加密检查数据
通过加密对数据进行加密处理,生成加密字符,如果有改动,字符就不相同
b、比对数据不一样,如果加密的字符不相同,说明两个数据不一致
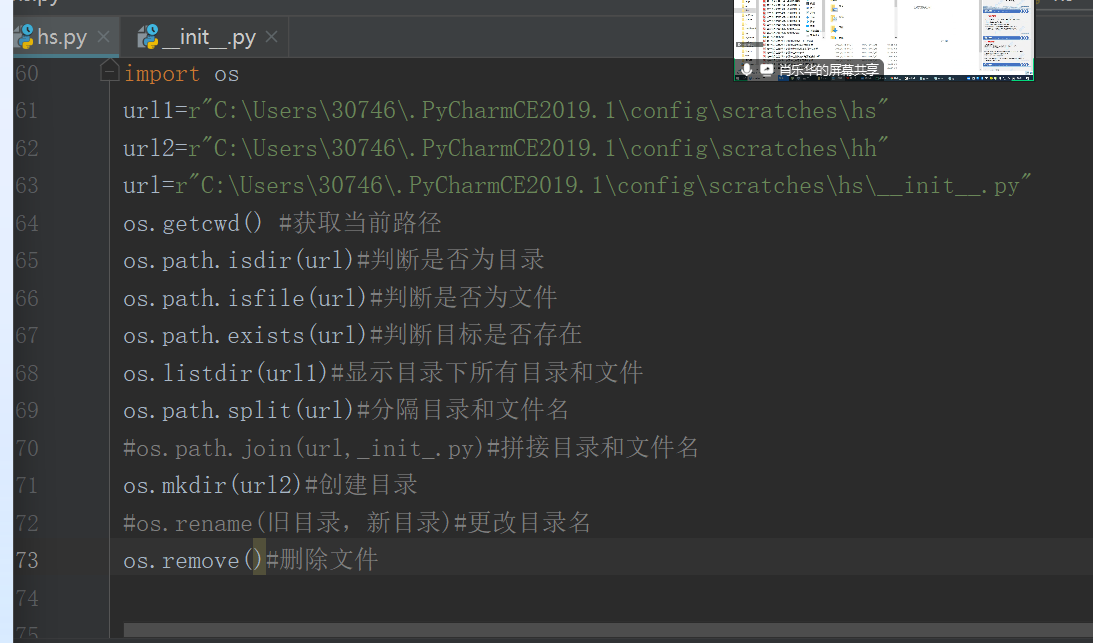
os模块:
os模块提供了多数操作系统的功能接口函数。当os模块被导入后,它会自适 应于不同的操作系统平台,根据不同的平台进行相应的操作,在python编 程时,经常和文件、目录打交道,所以离不了os模块。
os模块中常见的方法:
os.getcwd()获取当前执行命令所在目录
os.path.isfile()判断是否文件
os.path.isdir() #判断是否是目录
os.path.exists() #判断文件或目录是否存在
os.listdir(dirname) #列出指定目录下的目录或文件
os.path.split(name) #分割文件名与目录
os.path.join(path,name) #连接目录与文件名或目录
os.mkdir(dir) #创建一个目录
os.rename(old,new) #更改目录名称
os.remove() 删除文件
固定格式:
场景一:获取当前操作对象中的的的一个项目的绝对路径固定语法
import os
获取项目路径
p=os.path.abspath(os.path.dirname(os.getcwd()))
print()
获取当前文件的绝对路径,直接通过spliit对目录和文件进行分割
file_path=os.path.split(os.path.realpath(file))
print(file_path)
(‘C:\Users\Administrator\PycharmProjects\gs1\bao’, ‘python006.py’)
获取当前文件的绝对路径,直接通过spliit对目录
file_path=os.path.split(os.path.realpath(file))[0]
print(file_path)
获取当前文件的绝对路径,直接通过spliit对目录
file_path1=os.path.split(os.path.realpath(file))[1]
print(file_path1)
获取项目的绝对路径
v=os.path.dirname(os.path.dirname(file))
print(v)
项目路径和包进行拼接
hz_path=os.path.join(v,‘ss.txt’)
print(hz_path) #C:/Users/Administrator/PycharmProjects/gs1\ss.txt
print(os.path.abspath(file)) #获取绝对路径
print(os.path.dirname(os.path.abspath(file))) # 获取当前项目路径
python中re模块
一、re正则匹配基本介绍
正则匹配:使用re模块实现
1、什么是正则表达式?
正则表达式是一种对字符和特殊字符操作的一种逻辑公式,从特定的字符中,用正则表达字符来过滤的逻辑。
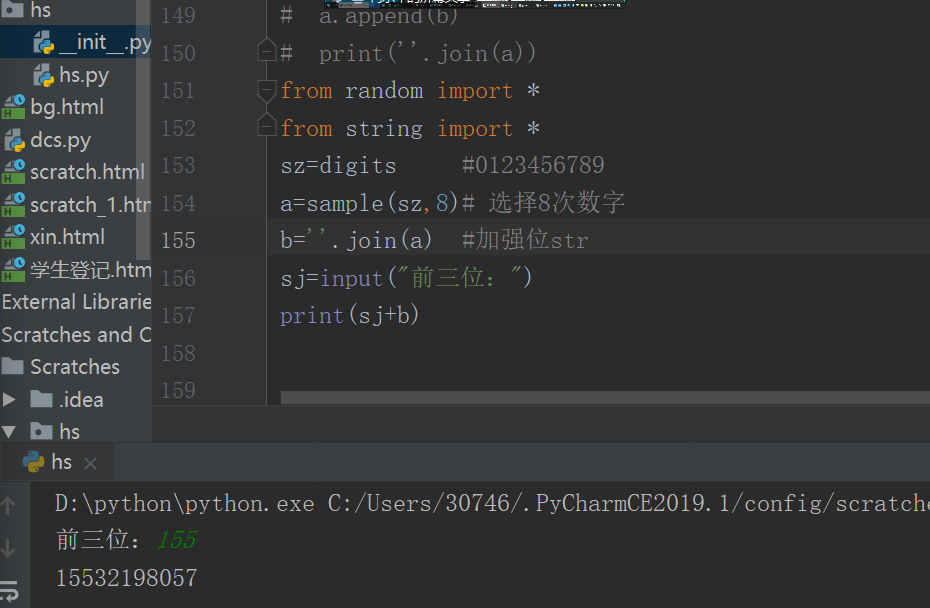
2、正则表达式是一种文本模式;
3、正则表达式可以帮助我们检查字符是否与某种模式匹配
4、re模块使pyhton语言用有全部的表达式功能
5、re表达式作用?
(1)快速高效查找和分析字符比对自读,也叫模式匹配,比如:查找,比对,匹配,替换,插入,添加,删除等能力。
(2)实现一个编译查看,一般在处理文件时用的多
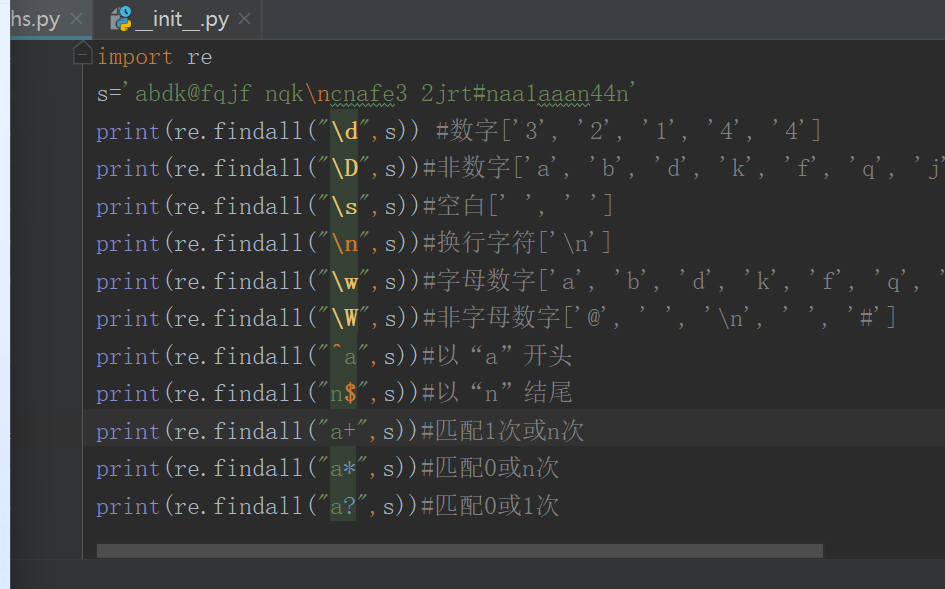
二、认识正则表达式中的特殊元素?
\d:数字0-9
\D:非数字
\s:空白字符
\n:换行符
\w 匹配字母数字
\W 匹配非字母数字
^:表示的匹配字符以什么开头
$:表示的匹配字符以什么结尾
:匹配前面的字符0次或n次 eg:ab (* 能匹配a 匹配ab 匹配abb )
+:匹配+前面的字符1次或n次
?:匹配?前面的字符0次或1次
{m}:匹配前一个字符m次
{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
1、findall
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[]
2、match
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败得到一个none值
注意:如果规则带了’+’,则匹配1次或者多次,无’+'只匹配一次
3、compile(不考虑)
编译模式生成对象,找到全部相关匹配为止,找不到返回一个列表[]
4、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则报错
group 以str 形式返回对象中match元素
span 以tuple形式返回范围
实战案例:
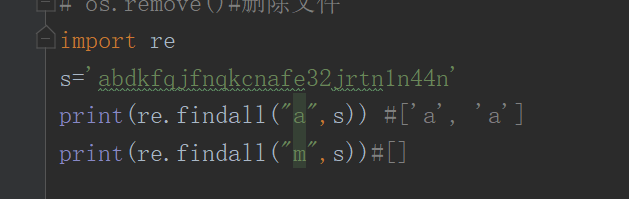
场景一、findall
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[]
(1)第一种情况查找字符汇总存在的字符
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.findall(‘a’,s)
print© #[‘a’, ‘a’, ‘a’] 显示查找的字符
(2)第二种情况查找不存在的字符
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.findall(‘z’,s)
print© #[] 显示的是一个空了列场景
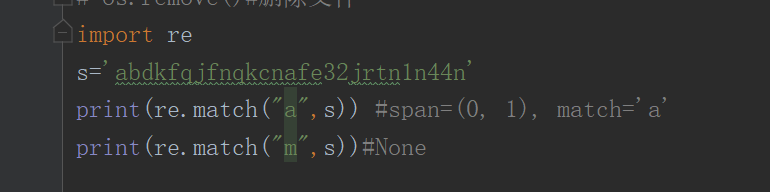
二、match 匹配开头
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败得到一个值就报错
第一种情况:开头是匹配的是存在的字符
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.match(‘a’,s)
print(c.span()) #显示结果是索引位:(0, 1)
第二种情况:开头匹配的是不存在字符
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.match(‘z’,s)
print© #None
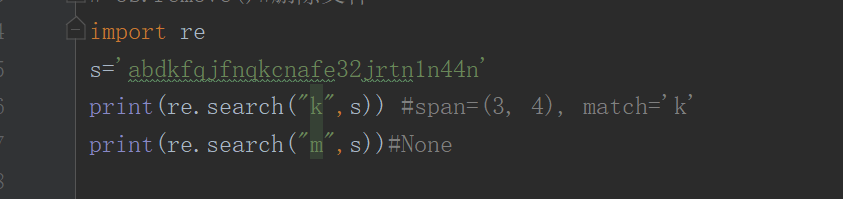
场景三、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则None
第一种情况:查看的字符存在,返回字符的索引位
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.search(‘1’,s)
print(c.span()) #(7, 8)
第2种情况:查看的字符不存在,返回字符的是none
import re # 导入re模块
s=‘anb1dckk12356afjmba’
c=re.search(‘9’,s)
print© # None
(1)\d:数字0-9 ,返回的结果是列表的格式
案例:
import re # 导入re模块
s=‘anb1dckk12356afjmba’
c=re.findall(‘\d’,s)
print© #[‘1’, ‘1’, ‘2’, ‘3’, ‘5’, ‘6’]
(2)\D:非数字
案例:
import re # 导入re模块
s=‘anb1dckk12356afjmba’
c=re.findall(‘\D’,s)
print©
(3)\s:空白字符
import re # 导入re模块
s=‘a nb1dck k12356a fjmba’
c=re.findall(‘\s’,s)
print© #[’ ', ’ ', ’ ', ’ ', ’ ']
(4)\n:换行符
案例:
import re # 导入re模块
s=‘a nb1\ndck k123 \n 56a fjmba’
c=re.findall(‘\n’,s)
print© #[‘\n’, ‘\n’]
(5)\w 匹配字母数字
案例:
import re # 导入re模块
s=‘a nb1*k123jmba’
c=re.findall(‘\w’,s)
print© #[‘a’, ‘n’, ‘b’, ‘1’, ‘k’, ‘1’, ‘2’, ‘3’, ‘j’, ‘m’, ‘b’, ‘a’]
(6)\W 匹配非字母数字
案例:
import re # 导入re模块
s=‘a nb1k123jmba’
c=re.findall(‘\W’,s)
print© #[’ ', '’, ‘', '’, ‘', '’]
(7)^:表示的匹配字符以什么开头
案例:
import re # 导入re模块
s=‘anb1*k123jmba’
c=re.findall(‘^a’,s)
print© #[‘a’]
KaTeX parse error: Expected 'EOF', got '#' at position 30: …案例: import re #̲ 导入re模块 s='anb1…’,s)
print© #[‘b’]
$以xx结尾
import re
str1="b@@@cd 1ef\n%%2 ajhij\nk 3a"
f=re.findall("b$",str1)
print(f)
()匹配前面的字符0次或n次 eg:ab ( 能匹配a 匹配ab 匹配abb )
案例:
import re # 导入re模块
s=‘anb1aa**k123aaaajmb’
c=re.findall('a’,s)
print©
[‘a’, ‘’, ‘’, ‘’, ‘’, ‘aa’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘aaaa’, ‘’, ‘’, ‘’, ‘’, ‘’]
+:匹配+前面的字符1次或n次
案例:
import re # 导入re模块
s=‘anb1aa**k123aaaa*jmaaaaaab’
c=re.findall(‘a+’,s)
print© #[‘a’, ‘aa’, ‘aaaa’, ‘aaaaaa’]
?:匹配?前面的字符0次或1次
案例:
import re # 导入re模块
s=‘anb1aak123aaaa*jmaaaaaab’
c=re.findall(‘a?’,s)
print©
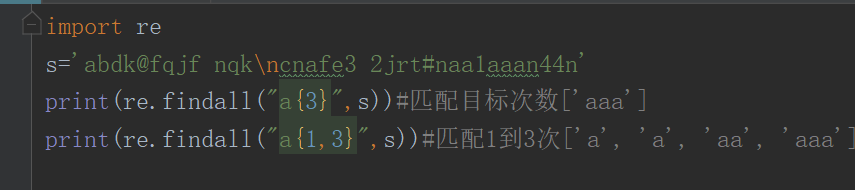
{m}:匹配前一个字符m次
案例:
import re # 导入re模块
s=‘abnb1abcak123aaaa*jmaasaasaab’
c=re.findall(‘a{3}’,s)
print©#[‘aaa’]
{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
案例:
s=‘abnb1abca**k123aaaa*jmaaasasaab’
c=re.findall(‘a{2,3}’,s)
print© #[‘aaa’, ‘aa’, ‘aa’, ‘aa’]
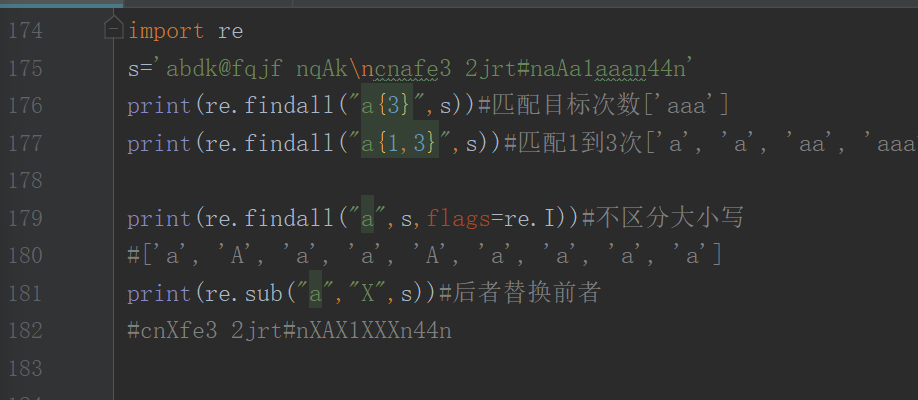
re 标识符:
flags=标识符
(1)re.I(大写的i) 不区分大小写
import re # 导入re模块
s=‘abnb1AabcaAk123jmaaasasaab’
c=re.findall(‘a’,s,flags=re.I)
print© #[‘a’, ‘A’, ‘a’, ‘a’, ‘A’, ‘a’, ‘a’, ‘a’, ‘a’, ‘a’, ‘a’]
sub 替换
import re # 导入re模块
s=‘abnb1AabcaAk123jmaaasasaab’
c=re.sub(‘\d’,‘拱墅’,s)
print©
python标准模块之json
定义:json (java script object notation)是轻量级的文本数据交换格式
案例json:
json和字典 一样
一、json模块可以实现json数据的序列化和反序列化
(1)序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式
实现方法:load() loads()
(2)反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象
实现方法:dump() dumps()
查看 dump用法:ctrl+点击dump
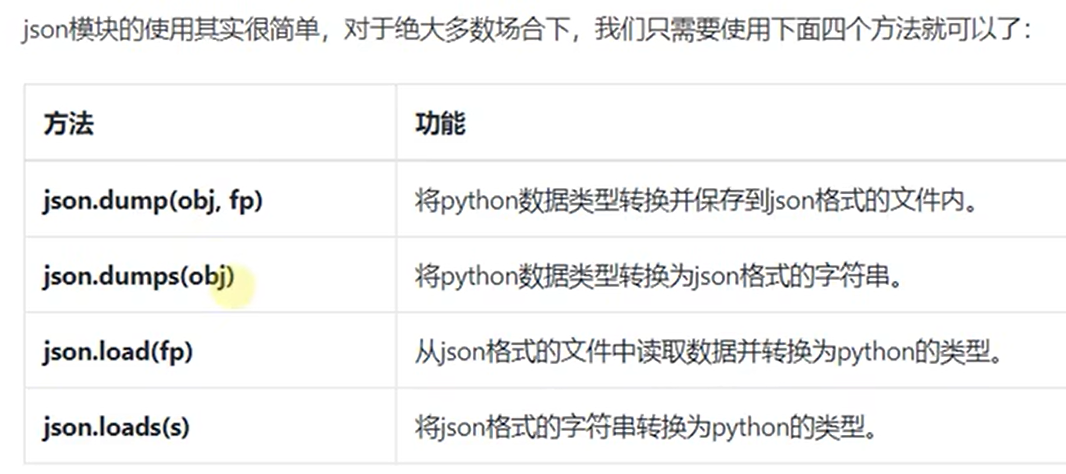
1、由python对象格式化成为json()dumps
案例1:将字典格式转化字符
j={'name':'zs','age':18,"no":["123","456"],"sex":"男"}
print(j)#{'name': 'zs', 'age': 18, 'no': ['123', '456'], 'sex': '男'}
print(type(j))#<class 'dict'>
jsonzfc=json.dumps(j,ensure_ascii=False)# 将一个字典转换称json
print(jsonzfc) #{"name": "zs", "age": 18, "no": ["123", "456"], "sex": "男"}
print(type(jsonzfc)) #<class 'str'>
备注:
1、python中的字典是单引号,字符是双引号
2、字典是大写True, 字符是小写
================================================
dump 方法:
定义:往文件中添加字符json
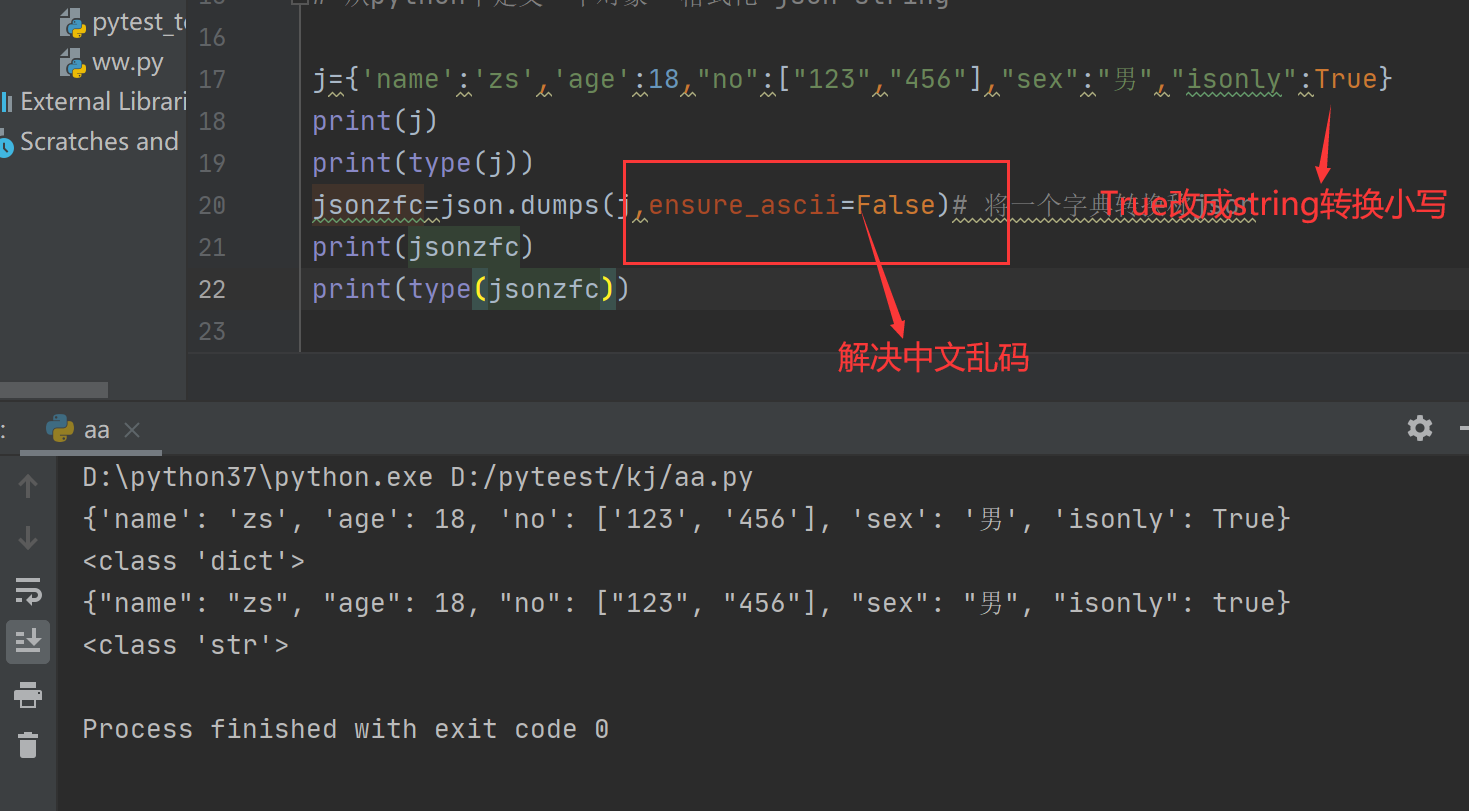
案例1:
j={'name':'zs','age':18,"no":["123","456"],"sex":"男","isonly":True}
print(j)
print(type(j))
jsonzfc=json.dumps(j,ensure_ascii=False)# 将一个字典转换称json
print(jsonzfc)
print(type(jsonzfc))
dump
json.dump(j,open("data.json","a"))
===================================================·
indent=4 indent 分隔符 ,排序
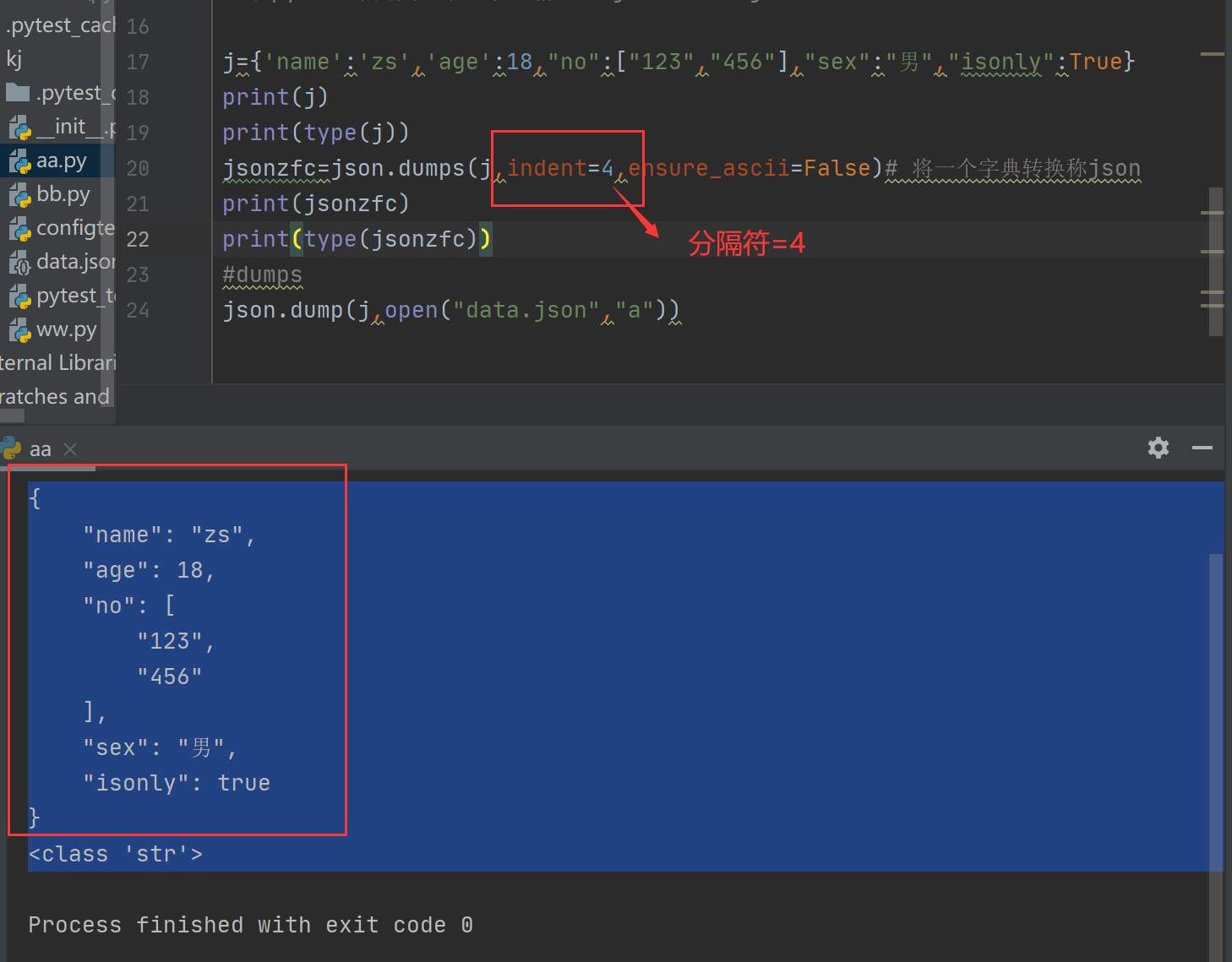
对json中字符 排序
sort_keys=True 排序;

三、 json string 转化称python对象
(1)字符类型转换成字典
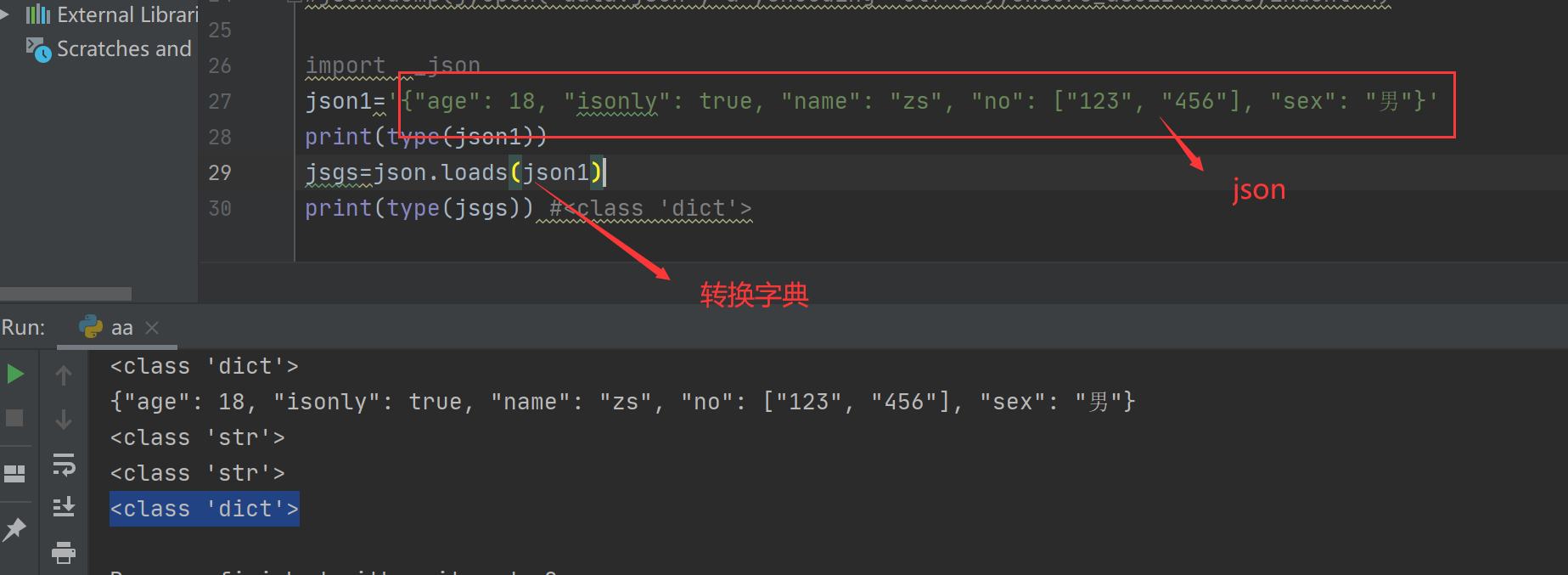
import _json
json1='{"age": 18, "isonly": true, "name": "zs", "no": ["123", "456"], "sex": "男"}'
print(type(json1))
jsgs=json.loads(json1)
print(type(jsgs)) #<class 'dict'>
(2)字符类型转换成元组
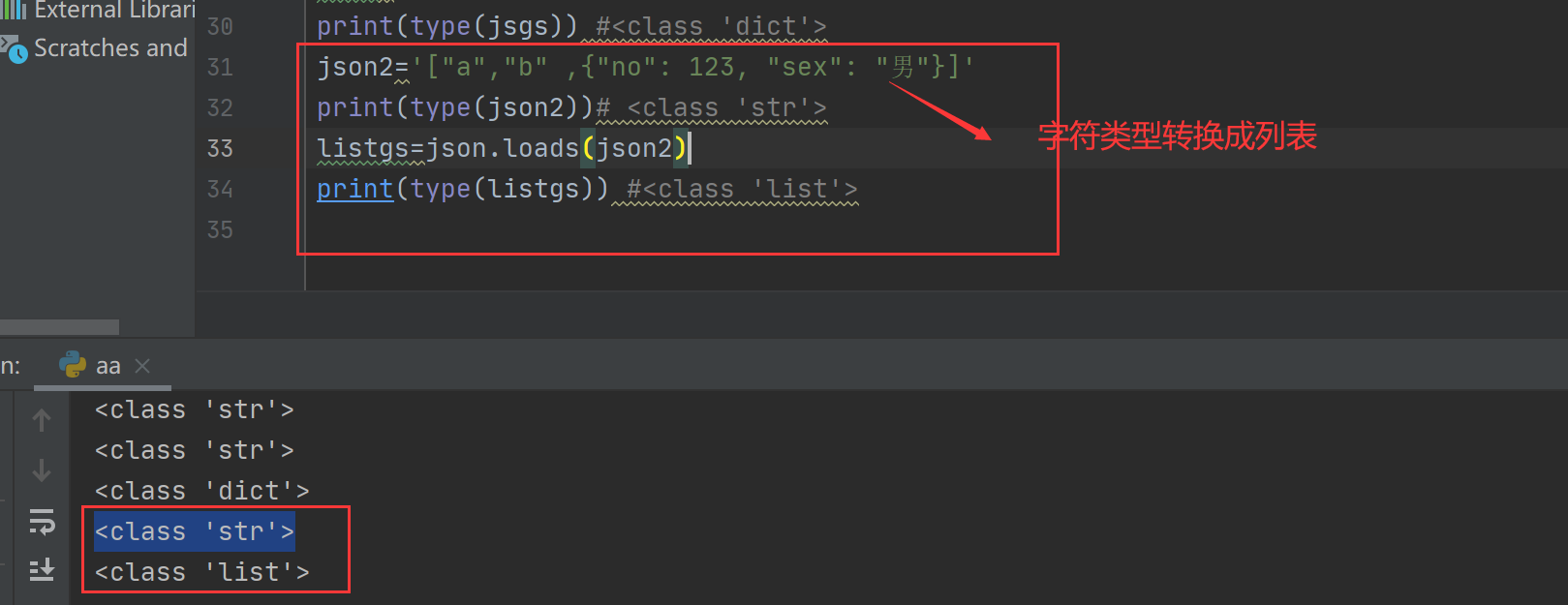
案例:
json2='["a","b" ,{"no": 123, "sex": "男"}]'
print(type(json2))# <class 'str'>
listgs=json.loads(json2)
print(type(listgs)) #<class 'list'>
四、load文件转换成 对象方式
1、创建json格式:
{"age": 18, "isonly": true, "name": "zs", "no": ["123", "456"], "sex": "男"}
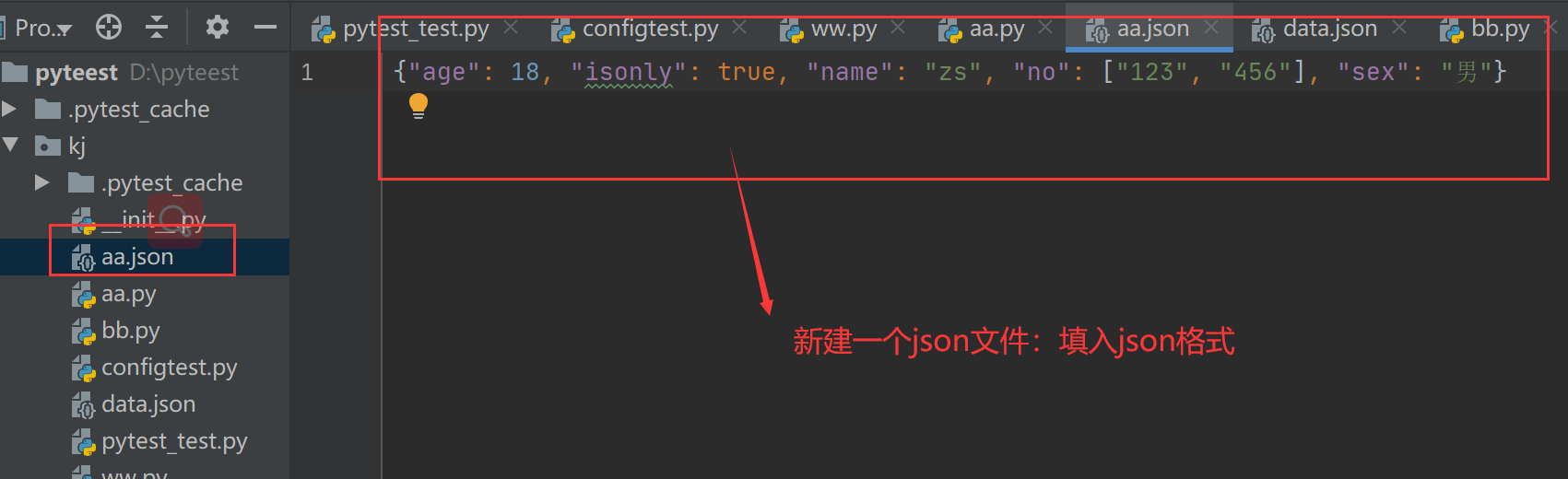
2、将 文件中的json通过load转换字典
import json
dxwj=json.load(open('aa.json','r',encoding="utf-8"))
print(type(dxwj))
print(dxwj)


