
爬虫大作业
1.选一个自己感兴趣的主题(所有人不能雷同)。
答:本次我选择的主题是爬去广州大学的“广大要闻”,工有333页,每页有20条新闻。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
答:第一,首先打开广州大学的新闻页:http://news.gzhu.edu.cn/guangdayaowen/,看到此页有20条新闻,获取总的新闻页数的代码实现如下:
#获取文章总页数
def getCount(url):
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
count = soup.select('.epages')[0].select("a")[0].text
print(count)
return count
3.对爬了的数据进行文本分析,生成词云。
答:第一,将获取的新闻内容,存到文本里面去:
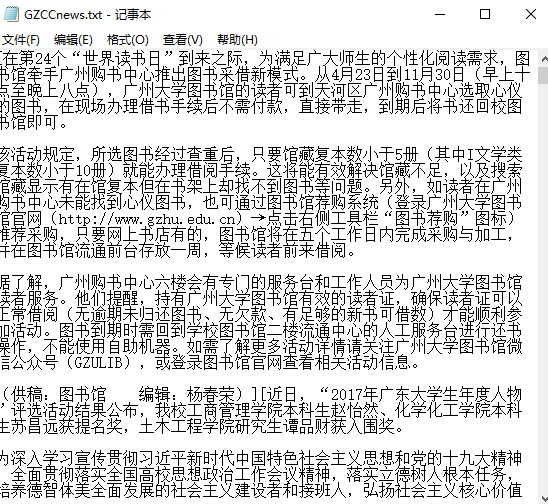
第二,将所获取到的新闻内容,插入图片,生成一张词云图:

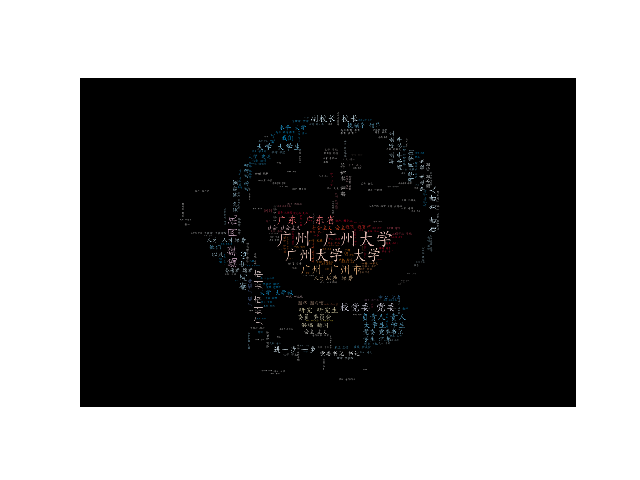
4.对文本分析结果进行解释说明。
答:文本获取到的字符信息并不是我们想要的效果,因此,为了达到我们想要的效果,我就将所获取到的文本信息,生成一个词云图,这样我们就可以比较直观地看出,广州大学地新闻网地信息主要在强调些什么,从而达到此次爬取的目的。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
答:在做这个大作业的过程中,我遇到了一下的一些问题和寻找解决办法:
第一,在是先这个完整的爬取过程,遇到的最大的问题就是在那个获取页面的总页数上,由于我学习还不深入,因此在这里停顿了好久,想不到很好的解决办法去解决这个问题,后来就去请教同学,在同学的帮助下,我成功的将自己所遇到的问题成功解决了。
第二,遇到的第二个问题,就是在安装生成词云的时候,导入有错误,因为不知道自己的python是多少位的,就胡乱下载错了,如:
后来选择合适的版本即:cp-36-cp-36m-win32.whl版本的来下载,cp指的是系统上安装的python版本,32表示安装的python版本是32位,不是操作系统
打开cmd运行,切换到指定目录运行
执行以下命令
pip install wordcloud-1.3.3-cp36-cp36m-win32.whl pip install wordcloud
最后就安装成功了。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
# -*- codding: UTF-8 -*-
# -*- author: WF -*-
import requests
from bs4 import BeautifulSoup
from util.expretion import filter_tags
import time
baseUrl="http://news.gzhu.edu.cn"
url =baseUrl+ "/guangdayaowen/index.html"
def writeNewDetail(content):
f = open('GZCCnews.txt','a',encoding='utf-8') #a是添加add的意思
f.write(content)
f.close()
#
def getList(url):
linkList=[]
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
list = soup.select('.news_list')[0].select("table")[1].select("li")
for i in list:
if len(i.select('a')) > 0: # 排除为空的li
list1 = i.select('a')[0].attrs['href']
print(list1)
linkList.append(list1)
print("*******************分页************************")
return (linkList)
#获取文章总页数
def getCount(url):
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
count = soup.select('.epages')[0].select("a")[0].text
print(count)
return count
#获取一篇文章详情
def getNewDetail(url):
detail_res = requests.get(url)
detail_res.encoding = 'utf-8'
detail_soup = BeautifulSoup(detail_res.text, 'html.parser') # 打开新闻详情页并解析
title=detail_soup.select(".title_info")[0].select("h1")[0].text
text=detail_soup.select("#text")
comment= filter_tags(str(text))
return comment
#获取一页的文章详情
def getPageDetail(linkList):
for item in linkList:
comment = getNewDetail(baseUrl + item)
writeNewDetail(comment)
if __name__ == '__main__':
count=getCount(url)
for item in range(1,int(count)+1):
linkList = []
if(item==1):
linkList = getList(url)
else:
linkList = getList(baseUrl+"/guangdayaowen/index" + "_" + str(item) + ".html")
getPageDetail(linkList)
print("第:"+str(item)+"页")
time.sleep(1)
#生成词云
# -*- codding: UTF-8 -*-
# -*- author: WF -*-
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import codecs
import numpy as np
from PIL import Image
import re
file = codecs.open('GZCCnews.txt', 'r', 'utf-8')
image=np.array(Image.open('D:/pythonWork/a.jpg'))
font=r'C:\Windows\Fonts\simkai.ttf'
word=file.read()
#去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\!\@\#\\\&\*\%]", "",word)
wordlist_after_jieba = jieba.cut(resultword, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split)
my_wordcloud = WordCloud(font_path=font,mask=image,background_color='black',max_words = 100,max_font_size = 300,random_state=50).generate(wl_space_split)
#根据图片生成词云
iamge_colors = ImageColorGenerator(image)
my_wordcloud.recolor(color_func = iamge_colors)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片,当关闭图片时才会生效,中断程序不会保存
my_wordcloud.to_file('result.jpg')
总结:第一,这次的爬取数据,主要是爬取广州大学的校园新闻,让我们能更进一步地了解到其他校园的校园新闻,获取其他学校的信息,来对比我们学校与其学校的异同之处。
第二,通过这次的爬虫经历,使我进一步了解pathon的语法的使用,让我学会了如何去爬取自己所需要的数据。同时,我还可以将所爬到的数据生成成词云,进一步直观地看到所爬取出来的数据。
第三,更深的感受是,还是要多练习,多思考,遇到不懂的地方可以虚心地向有经验的同学请教。

