


单词统计
package 输出频率; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.text.DecimalFormat; import java.util.HashMap; import java.util.Map; //piao单词统计 public class Pipei { public static Map<String,Integer> map1=new HashMap<String,Integer>(); static int g_Wordcount[]=new int[27]; static int g_Num[]=new int[27]; static String []unUse=new String[] { "it", "in", "to", "of", "the", "and", "that", "for" }; public static void main(String arg[]) { //daoruFiles("piao.txt","tongji"); traverseFolder2("D:\\piao"); } public static void daoruFiles(String a,String dc) { map1.clear(); try { daoru(a); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } String sz[]; Integer num[]; final int MAXNUM=10; //统计的单词出现最多的前n个的个数 for(int i=0;i<g_Wordcount.length;i++) { g_Wordcount[i]=0; g_Num[i]=i; } sz=new String[MAXNUM+1]; num=new Integer[MAXNUM+1]; Pipei pipei=new Pipei(); int account =1; //Vector<String> ve1=new Vector<String>(); try { daoru(a); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } System.out.println("英文单词的出现情况如下:"); int g_run=0; for(g_run=0;g_run<MAXNUM+1;g_run++) { account=1; for(Map.Entry<String,Integer> it : Pipei.map1.entrySet()) { if(account==1) { sz[g_run]=it.getKey(); num[g_run]=it.getValue(); account=2; } if(account==0) { account=1; continue; } if(num[g_run]<it.getValue()) { sz[g_run]=it.getKey(); num[g_run]=it.getValue(); } //System.out.println("英文单词: "+it.getKey()+" 该英文单词出现次数: "+it.getValue()); } Pipei.map1.remove(sz[g_run]); } int g_count=1; String tx1=new String(); String tx2=new String(); for(int i=0;i<g_run;i++) { if(sz[i]==null) continue; if(sz[i].equals("")) continue; tx1+="出现次数第"+(g_count)+"的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]+"\r\n"; System.out.println("出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]); g_count++; } try { daochu(tx1,dc+"2.txt"); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } //------------------------------ int temp=g_Wordcount[0]; int numtemp=0; for(int i=0;i<26;i++) { for(int j=i;j<26;j++) { if(g_Wordcount[j]>g_Wordcount[i]) { temp=g_Wordcount[i]; g_Wordcount[i]=g_Wordcount[j]; g_Wordcount[j]=temp; numtemp=g_Num[i]; g_Num[i]=g_Num[j]; g_Num[j]=numtemp; } } } int sum=0; for(int i=0;i<26;i++) { sum+=g_Wordcount[i]; } for(int i=0;i<26;i++) { char c=(char) ('a'+g_Num[i]); tx2+=c+":"+String.format("%.2f%% \r\n", (double)g_Wordcount[i]/sum*100); } try { daochu(tx2,dc+"1.txt"); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } //------------------------------ } public static void daoru(String s) throws IOException { File a=new File(s); FileInputStream b = new FileInputStream(a); InputStreamReader c=new InputStreamReader(b,"UTF-8"); String string2=new String(""); while(c.ready()) { char string1=(char) c.read(); if(WordNum(string1)>=0) { g_Wordcount[WordNum(string1)]+=1; } //------------------------ if(!isWord(string1)) { if(!isBaseWord(string2)) { if(map1.containsKey(string2.toLowerCase())) { Integer num1=map1.get(string2.toLowerCase())+1; map1.put(string2.toLowerCase(),num1); } else { Integer num1=1; map1.put(string2.toLowerCase(),num1); } } string2=""; } else { if(isInitWord(string1)) { string2+=string1; } } } if(!string2.isEmpty()) { if(!isBaseWord(string2)) { if(map1.containsKey(string2.toLowerCase())) { Integer num1=map1.get(string2.toLowerCase())+1; map1.put(string2.toLowerCase(),num1); } else { Integer num1=1; map1.put(string2.toLowerCase(),num1); } } string2=""; } c.close(); b.close(); } public static void daochu(String txt,String outfile) throws IOException { File fi=new File(outfile); FileOutputStream fop=new FileOutputStream(fi); OutputStreamWriter ops=new OutputStreamWriter(fop,"UTF-8"); ops.append(txt); ops.close(); fop.close(); } public static boolean isWord(char a) { if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a=='\'') return true; return false; } public static boolean isInitWord(char a) { if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a>'0'&&a<'9'||a=='\'') return true; return false; } public static boolean isBaseWord(String word) { for(int i=0;i<unUse.length;i++) { if(unUse[i].equals(word)||word.length()==1) return true; } return false; } public static int WordNum(char a) { if(a<='z'&&a>='a') return a-'a'; else if(a<='Z'&&a>='A') return a-'A'; return -1; } //----递归文件夹 public static void traverseFolder2(String path) { File file = new File(path); if (file.exists()) { File[] files = file.listFiles(); if (null == files || files.length == 0) { System.out.println("文件夹是空的!"); return; } else { for (File file2 : files) { if (file2.isDirectory()) { System.out.println("文件夹:" + file2.getAbsolutePath()); traverseFolder2(file2.getAbsolutePath()); } else { System.out.println("文件:" + file2.getAbsolutePath()); String name=file2.getName(); daoruFiles(file2.getAbsolutePath(), file2.getParentFile()+"\\"+name.replace(".txt", "")+"tongji"); } } } } else { System.out.println("文件不存在!"); } } }
测试截图:
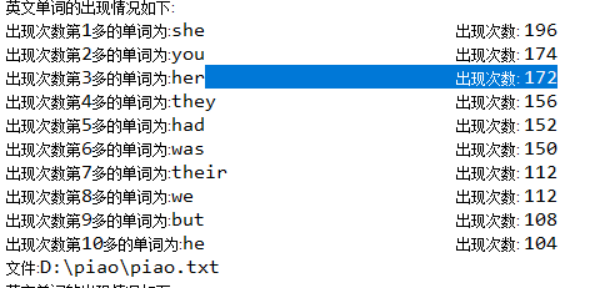

设计思想:
首先需要将将要被统计的单词存储到文件夹里面。然后通过文件读取出文件中的单词,将单词分解成为一个一个字母,通过比较查询,将单词频率以及最常用的单词输出出来。
