
机器学习裂纹识别
基于逻辑斯谛回归算法的裂纹识别
(一)选题背景
裂纹识别一直是机器视觉领域的重要研究内容,尤其是与之相关的自动检测算法在近年来备受关注。深度学习作为机器学习的一个分支,其在裂纹识别方面已显现出强大的功能和灵活性。裂纹是指材料在应力和/或环境作用下产生的裂隙,它存在于道路、机械、建筑等各种结构中。裂纹是引起大型复杂结构被破坏的主要原因之一。
早期初始的裂纹通常微小,隐匿而不易被发现,容易被人们忽略,但裂纹的深入扩展往往会导致重大灾难性事故的发生,如航空灾难、桥梁坍塌和油气管线爆裂等,给国家和社会造成巨大的损失。因此,对早期初始微小裂纹的准确检测至关重要。传统裂纹识别主要依赖人工,存在成本高、耗时长和可靠性偏低等问题,而实现裂纹自动化、智能化检测是目前裂纹识别领域的研究热点。
(二)对选题任务的理解
在分析了研究内容之后了解到需要做的是获取已经给出的40000张图片的数据,即用数据的形式表示出所给出的40000张图片,然后将得到 的数据进行划分 后对模型进行训练,之后对测试集中的数据进行预测并在预测之后求得预测结果的准确率
(三)选题内容
项目对象为含有裂纹和不含裂纹的两类图像样本数据集组成,选择合适的算法,完成数据集分类任务。
项目数据集包括: 含有裂纹(Positive)样本20000个 不含裂纹(Negative)样本20000个 将数据集的20%作为测试集,输出模型的预测结果。
(四)思路
在试图直接去获取图片数据多次报错之后,通过查找资料发现需要对图片进行预处理来减小数据的总量,通过查找资料和对之前所学的整理 想到了将图片转换为灰度图,而在单纯地将图片转换为灰度图之后仍然存在数据太多的情况,于是想到了对图片的大小进行调整以及对图像进行 细分等方法来减小40000张图片的数据量。当将40000张图片的数据量缩小后,通过建立逻辑斯谛回归模型,对图像参数处理并针对测试集进行 预测并求得预测结果的准确率。
(五)关键技术
解决这一任务的关键在于选择一种处理图像数据的算法和解决由于图像数据太多而无法正常计算的问题。这里选择使用逻辑斯谛回归对处理之 后的图像数据进行处理,而处理数据选择了将其转换为灰度图以及对其大小进行调整等措施
(六)实现步骤
1.定义create_dataset函数
2.在函数内部对文件中的40000张图片进行处理,包括:将图片转为灰度图、调整大小、生成细分图像、计算图像亮度标准化因子、标准化图像 并将其重新拉平等
3.将处理之后的数据进行保存
4.将数据集合并并打乱顺序
5.打印出图像数组的形状和标签数组进行验证
(一)数据源
https://www.kaggle.com/datasets/arnavr10880/concrete-crack-images-for-classification


(二)实现的代码
引入库
import os import random import shutil from shutil import copy2 import os.path as osp def data_set_split(src_data_folder, target_data_folder, train_scale=0.6, val_scale=0.2, test_scale=0.2): print("开始数据集划分") class_names = os.listdir(src_data_folder)
在目标目录下创建文件夹
# 在目标目录下创建文件夹 split_names = ['train', 'val', 'test'] for split_name in split_names: split_path = os.path.join(target_data_folder, split_name) if os.path.isdir(split_path): pass else: os.mkdir(split_path)
然后在split_path的目录下创建类别文件夹
# 然后在split_path的目录下创建类别文件夹 for class_name in class_names: class_split_path = os.path.join(split_path, class_name) if os.path.isdir(class_split_path): pass else: os.mkdir(class_split_path)
按照比例划分数据集,并进行数据图片的复制
首先进行分类遍历
# 按照比例划分数据集,并进行数据图片的复制 # 首先进行分类遍历 for class_name in class_names: current_class_data_path = os.path.join(src_data_folder, class_name) current_all_data = os.listdir(current_class_data_path) current_data_length = len(current_all_data) current_data_index_list = list(range(current_data_length)) random.shuffle(current_data_index_list) train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name) val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name) test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name) train_stop_flag = current_data_length * train_scale val_stop_flag = current_data_length * (train_scale + val_scale) current_idx = 0 train_num = 0 val_num = 0 test_num = 0 for i in current_data_index_list: src_img_path = os.path.join(current_class_data_path, current_all_data[i]) if current_idx <= train_stop_flag: copy2(src_img_path, train_folder) train_num = train_num + 1 elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag): copy2(src_img_path, val_folder) val_num = val_num + 1 else: copy2(src_img_path, test_folder) test_num = test_num + 1 current_idx = current_idx + 1 print("*********************************{}*************************************".format(class_name)) print( "{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length)) print("训练集{}:{}张".format(train_folder, train_num)) print("验证集{}:{}张".format(val_folder, val_num)) print("测试集{}:{}张".format(test_folder, test_num)) if __name__ == '__main__': src_data_folder = "/media/neaucs2/tc/dataset/Crack/Dataset" # 原始数据集路径 target_data_folder = src_data_folder + "_" + "split" if osp.isdir(target_data_folder): print("target folder 已存在, 正在删除...") shutil.rmtree(target_data_folder) os.mkdir(target_data_folder) print("Target folder 创建成功") data_set_split(src_data_folder, target_data_folder) print("*****************************************************************") print("数据集划分完成,请在{}目录下查看".format(target_data_folder))

(三)数据增强和测试指标的代码集中在这里
导入必备的包
# 导入必备的包 import numpy as np import pandas as pd import os from PIL import Image import cv2 import math
网络模型构建需要的包
# 网络模型构建需要的包 import torch import torchvision import timm import torch.nn as nn import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from tqdm import tqdm from collections import defaultdict import matplotlib.pyplot as plt from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.model_selection import train_test_split, cross_validate, StratifiedKFold, cross_val_score
Metric 测试准确率需要的包
# Metric 测试准确率需要的包 from sklearn.metrics import f1_score, accuracy_score, recall_score
Augmentation 数据增强要使用到的包
# Augmentation 数据增强要使用到的包 import albumentations from albumentations.pytorch.transforms import ToTensorV2 from torchvision import datasets, models, transforms
这个库主要用于定义如何进行数据增强。
# 这个库主要用于定义如何进行数据增强。 # https://zhuanlan.zhihu.com/p/149649900?from_voters_page=true def get_torch_transforms(img_size=224): data_transforms = { 'train': transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.RandomHorizontalFlip(p=0.2), transforms.RandomRotation((-5, 5)), transforms.RandomAutocontrast(p=0.2), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } return data_transforms
训练集的预处理以及数据增强
# 训练集的预处理以及数据增强 def get_train_transforms(img_size=320): return albumentations.Compose( [ albumentations.Resize(img_size, img_size), albumentations.HorizontalFlip(p=0.5), albumentations.VerticalFlip(p=0.5), albumentations.Rotate(limit=180, p=0.7), albumentations.ShiftScaleRotate( shift_limit=0.25, scale_limit=0.1, rotate_limit=0 ), albumentations.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225], max_pixel_value=255.0, always_apply=True ), ToTensorV2(p=1.0), ] )
验证集和测试集的预处理
# 验证集和测试集的预处理 def get_valid_transforms(img_size=224): return albumentations.Compose( [ albumentations.Resize(img_size, img_size), albumentations.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225], max_pixel_value=255.0, always_apply=True ), ToTensorV2(p=1.0) ] )
加载csv格式的数据
# 加载csv格式的数据 class LeafDataset(Dataset): def __init__(self, images_filepaths, labels, transform=None): self.images_filepaths = images_filepaths # 数据集路径是个列表 self.labels = labels # 标签也是个列表 self.transform = transform # 数据增强 def __len__(self): # 返回数据的长度 return len(self.images_filepaths) def __getitem__(self, idx): # 迭代器,这里使用的是cv,所以一定不要出现中文路径 image_filepath = self.images_filepaths[idx] image = cv2.imread(image_filepath) # 读取图片 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 图片的颜色通道转化 label = self.labels[idx] # 读取图片标签 if self.transform is not None: # 对图片做处理 image = self.transform(image=image)["image"] # 这个转化做的是传入一个图片,返回的是一个字典,我们应该将转化之后的图片那部分取出 # 返回处理之后的图片和标签 return image, label
测试准确率
# 测试准确率 def accuracy(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() return accuracy_score(target, y_pred)
计算f1
# 计算f1 def calculate_f1_macro(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() return f1_score(target, y_pred, average='macro')
计算recall
# 计算recall def calculate_recall_macro(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() # tp fn fp return recall_score(target, y_pred, average="macro", zero_division=0)
训练的时候输出信息使用
# 训练的时候输出信息使用 class MetricMonitor: def __init__(self, float_precision=3): self.float_precision = float_precision self.reset() def reset(self): self.metrics = defaultdict(lambda: {"val": 0, "count": 0, "avg": 0}) def update(self, metric_name, val): metric = self.metrics[metric_name] metric["val"] += val metric["count"] += 1 metric["avg"] = metric["val"] / metric["count"] def __str__(self): return " | ".join( [ "{metric_name}: {avg:.{float_precision}f}".format( metric_name=metric_name, avg=metric["avg"], float_precision=self.float_precision ) for (metric_name, metric) in self.metrics.items() ] )
调整学习率
# 调整学习率 def adjust_learning_rate(optimizer, epoch, params, batch=0, nBatch=None): """ adjust learning of a given optimizer and return the new learning rate """ new_lr = calc_learning_rate(epoch, params['lr'], params['epochs'], batch, nBatch) for param_group in optimizer.param_groups: param_group['lr'] = new_lr return new_lr """ learning rate schedule """
计算学习率
# 计算学习率 def calc_learning_rate(epoch, init_lr, n_epochs, batch=0, nBatch=None, lr_schedule_type='cosine'): if lr_schedule_type == 'cosine': t_total = n_epochs * nBatch t_cur = epoch * nBatch + batch lr = 0.5 * init_lr * (1 + math.cos(math.pi * t_cur / t_total)) elif lr_schedule_type is None: lr = init_lr else: raise ValueError('do not support: %s' % lr_schedule_type) return lr
(四)模型训练及展示训练过程曲线
# from torchutils import * from torchvision import datasets, models, transforms import numpy as np import os.path as osp import torch.nn as nn import os import ssl import torch import matplotlib %matplotlib inline # matplotlib.use('TkAgg') ssl._create_default_https_context = ssl._create_unverified_context if torch.cuda.is_available(): device = torch.device('cuda:0') else: device = torch.device('cpu') print(f'Using device: {device}') # 固定随机种子,保证实验结果是可以复现的 seed = 42 os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True data_path = "/media/neaucs2/tc/dataset/Crack/Dataset_split" # 数据集路径 # 超参数设置 params = { # 'model': 'vit_tiny_patch16_224', # 选择预训练模型 'model': 'resnet50d', # 选择预训练模型 # 'model': 'efficientnet_b3a', # 选择预训练模型 "img_size": 227, # 图片输入大小 "train_dir": osp.join(data_path, "train"), # 训练集路径 "val_dir": osp.join(data_path, "val"), # 验证集路径 'device': device, # 设备 'lr': 1e-3, # 学习率 'batch_size': 64, # 批次大小 'num_workers': 0, # 进程 'epochs': 10, # 轮数 "save_dir": "../checkpoints_new/", # 保存路径 "pretrained": False, "num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目 'weight_decay': 1e-5 # 学习率衰减 } # 定义模型 class SELFMODEL(nn.Module): def __init__(self, model_name=params['model'], out_features=params['num_classes'], pretrained=True): super().__init__() self.model = timm.create_model(model_name, pretrained=pretrained) # 从预训练的库中加载模型 # classifier if model_name[:3] == "res": n_features = self.model.fc.in_features # 修改全连接层数目 self.model.fc = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目 elif model_name[:3] == "vit": n_features = self.model.head.in_features # 修改全连接层数目 self.model.head = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目 else: n_features = self.model.classifier.in_features self.model.classifier = nn.Linear(n_features, out_features) # resnet修改最后的全链接层 print(self.model) # 返回模型 def forward(self, x): # 前向传播 x = self.model(x) return x # 定义训练流程 def train(train_loader, model, criterion, optimizer, epoch, params): metric_monitor = MetricMonitor() # 设置指标监视器 model.train() # 模型设置为训练模型 nBatch = len(train_loader) stream = tqdm(train_loader) for i, (images, target) in enumerate(stream, start=1): # 开始训练 images = images.to(params['device'], non_blocking=True) # 加载数据 target = target.to(params['device'], non_blocking=True) # 加载模型 output = model(images) # 数据送入模型进行前向传播 loss = criterion(output, target.long()) # 计算损失 f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算准确率分数 metric_monitor.update('Loss', loss.item()) # 更新损失 metric_monitor.update('F1', f1_macro) # 更新f1 metric_monitor.update('Recall', recall_macro) # 更新recall metric_monitor.update('Accuracy', acc) # 更新准确率 optimizer.zero_grad() # 清空学习率 loss.backward() # 损失反向传播 optimizer.step() # 更新优化器 lr = adjust_learning_rate(optimizer, epoch, params, i, nBatch) # 调整学习率 stream.set_description( # 更新进度条 "Epoch: {epoch}. Train. {metric_monitor}".format( epoch=epoch, metric_monitor=metric_monitor) ) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"] # 返回结果 # 定义验证流程 def validate(val_loader, model, criterion, epoch, params): metric_monitor = MetricMonitor() # 验证流程 model.eval() # 模型设置为验证格式 stream = tqdm(val_loader) # 设置进度条 with torch.no_grad(): # 开始推理 for i, (images, target) in enumerate(stream, start=1): images = images.to(params['device'], non_blocking=True) # 读取图片 target = target.to(params['device'], non_blocking=True) # 读取标签 output = model(images) # 前向传播 loss = criterion(output, target.long()) # 计算损失 f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算acc metric_monitor.update('Loss', loss.item()) # 后面基本都是更新进度条的操作 metric_monitor.update('F1', f1_macro) metric_monitor.update("Recall", recall_macro) metric_monitor.update('Accuracy', acc) stream.set_description( "Epoch: {epoch}. Validation. {metric_monitor}".format( epoch=epoch, metric_monitor=metric_monitor) ) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"] # 展示训练过程的曲线 def show_loss_acc(acc, loss, val_acc, val_loss, sava_dir): # 从history中提取模型训练集和验证集准确率信息和误差信息 # 按照上下结构将图画输出 plt.figure(figsize=(8, 8)) plt.subplot(2, 1, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.ylabel('Accuracy') plt.ylim([min(plt.ylim()), 1]) plt.title('Training and Validation Accuracy') plt.subplot(2, 1, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.ylabel('Cross Entropy') plt.title('Training and Validation Loss') plt.xlabel('epoch') # 保存在savedir目录下。 save_path = osp.join(save_dir, "results.png") plt.savefig(save_path, dpi=100) if __name__ == '__main__': accs = [] losss = [] val_accs = [] val_losss = [] data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式 train_transforms = data_transforms['train'] # 训练集数据处理方式 valid_transforms = data_transforms['val'] # 验证集数据集处理方式 train_dataset = datasets.ImageFolder(params["train_dir"], train_transforms) # 加载训练集 valid_dataset = datasets.ImageFolder(params["val_dir"], valid_transforms) # 加载验证集 if params['pretrained'] == True: save_dir = osp.join(params['save_dir'], params['model']+"_pretrained_" + str(params["img_size"])) # 设置模型保存路径 else: save_dir = osp.join(params['save_dir'], params['model'] + "_nopretrained_" + str(params["img_size"])) # 设置模型保存路径 if not osp.isdir(save_dir): # 如果保存路径不存在的话就创建 os.makedirs(save_dir) # print("save dir {} created".format(save_dir)) train_loader = DataLoader( # 按照批次加载训练集 train_dataset, batch_size=params['batch_size'], shuffle=True, num_workers=params['num_workers'], pin_memory=True, ) val_loader = DataLoader( # 按照批次加载验证集 valid_dataset, batch_size=params['batch_size'], shuffle=False, num_workers=params['num_workers'], pin_memory=True, ) print(train_dataset.classes) model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'], pretrained=params['pretrained']) # 加载模型 # model = nn.DataParallel(model) # 模型并行化,提高模型的速度 # resnet50d_1epochs_accuracy0.50424_weights.pth model = model.to(params['device']) # 模型部署到设备上 criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数 optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器 # 损失函数和优化器可以自行设置修改。 # criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数 # optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器 best_acc = 0.0 # 记录最好的准确率 # 只保存最好的那个模型。 for epoch in range(1, params['epochs'] + 1): # 开始训练 acc, loss = train(train_loader, model, criterion, optimizer, epoch, params) val_acc, val_loss = validate(val_loader, model, criterion, epoch, params) accs.append(acc) losss.append(loss) val_accs.append(val_acc) val_losss.append(val_loss) if val_acc >= best_acc: # 保存的时候设置一个保存的间隔,或者就按照目前的情况,如果前面的比后面的效果好,就保存一下。 # 按照间隔保存的话得不到最好的模型。 save_path = osp.join(save_dir, f"{params['model']}_{epoch}epochs_accuracy{acc:.5f}_weights.pth") torch.save(model.state_dict(), save_path) best_acc = val_acc show_loss_acc(accs, losss, val_accs, val_losss, save_dir) print("训练已完成,模型和训练日志保存在: {}".format(save_dir))
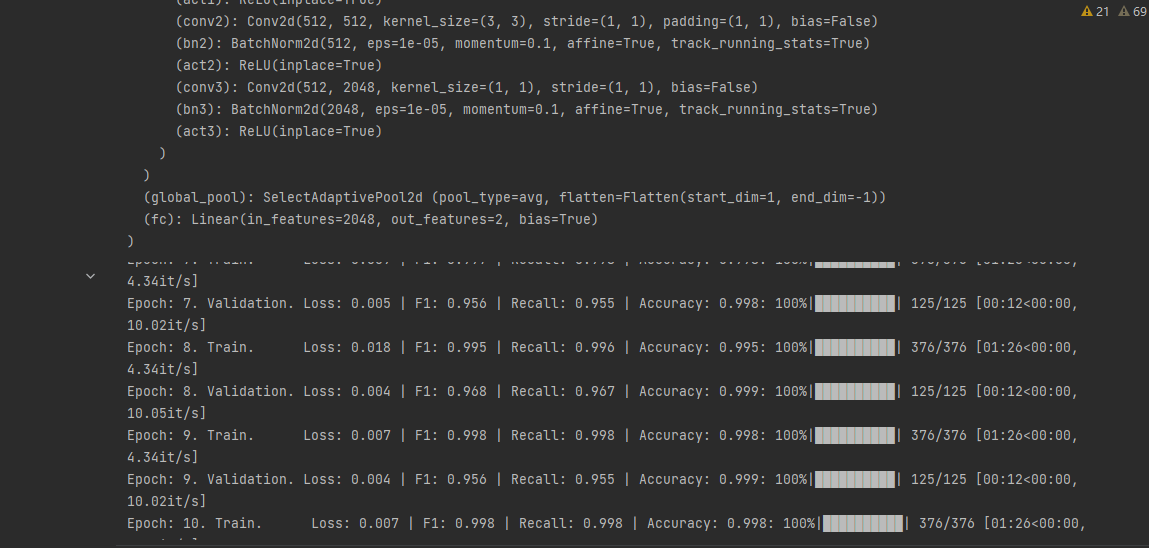
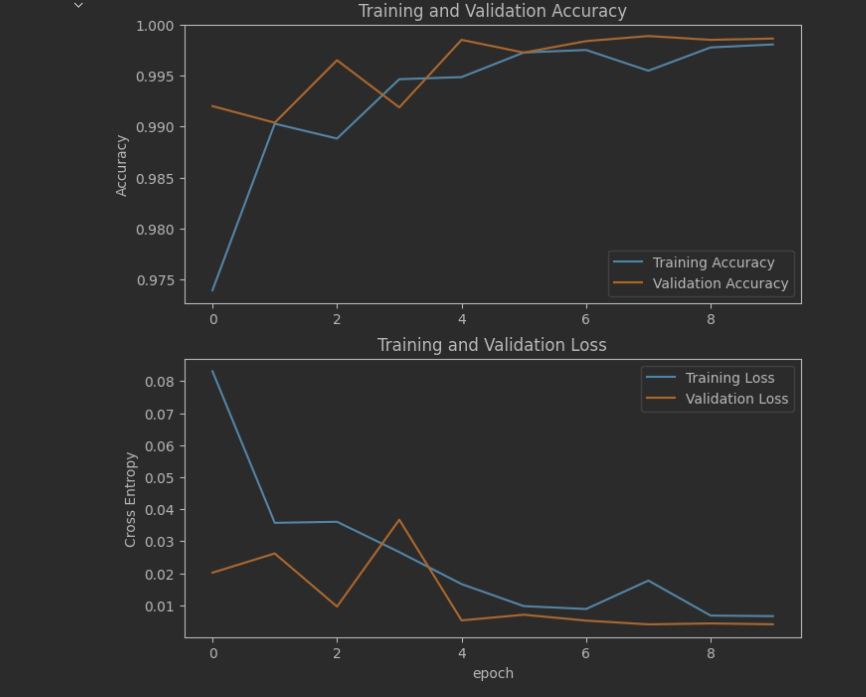
(五)数据测试准确率
# from torchutils import * from torchvision import datasets, models, transforms import os.path as osp import os if torch.cuda.is_available(): device = torch.device('cuda:0') else: device = torch.device('cpu') print(f'Using device: {device}') # 固定随机种子,保证实验结果是可以复现的 seed = 42 os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True # noqa torch.backends.cudnn.benchmark = True # noqa data_path = "/media/neaucs2/tc/dataset/Crack/Dataset_split/" # 修改为数据集根目录 model_path = "/media/neaucs2/tc/111/checkpoints_new/resnet50d_nopretrained_227/resnet50d_8epochs_accuracy0.99547_weights.pth" # todo 模型地址 model_name = 'resnet50d' # 模型名称 img_size = 227 # 数据集训练时输入模型的大小 # 超参数设置 params = { # 'model': 'vit_tiny_patch16_224', # 选择预训练模型 # 'model': 'efficientnet_b3a', # 选择预训练模型 'model': model_name, # 选择预训练模型 "img_size": img_size, # 图片输入大小 "test_dir": osp.join(data_path, "test"), # 测试集子目录 'device': device, # 设备 'batch_size': 64, # 批次大小 'num_workers': 0, # 进程 "num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目 } # 定义测试流程 def test(val_loader, model, params, class_names): metric_monitor = MetricMonitor() # 验证流程 model.eval() # 模型设置为验证格式 stream = tqdm(val_loader) # 设置进度条 # 对模型分开进行推理 test_real_labels = [] test_pre_labels = [] with torch.no_grad(): # 开始推理 for i, (images, target) in enumerate(stream, start=1): images = images.to(params['device'], non_blocking=True) # 读取图片 target = target.to(params['device'], non_blocking=True) # 读取标签 output = model(images) # 前向传播 target_numpy = target.cpu().numpy() y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu().numpy() test_real_labels.extend(target_numpy) test_pre_labels.extend(y_pred) f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算acc metric_monitor.update('F1', f1_macro) # 后面基本都是更新进度条的操作 metric_monitor.update("Recall", recall_macro) metric_monitor.update('Accuracy', acc) stream.set_description( "mode: {epoch}. {metric_monitor}".format( epoch="test", metric_monitor=metric_monitor) ) class_names_length = len(class_names) heat_maps = np.zeros((class_names_length, class_names_length)) for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels): heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1 heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1) heat_maps_float = heat_maps / heat_maps_sum show_heatmaps(title="Crack Detect", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float, save_name="Crack_Detect_{}.png".format(model_name)) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['F1']["avg"], \ metric_monitor.metrics['Recall']["avg"] # 绘制测试热力图 def show_heatmaps(title, x_labels, y_labels, harvest, save_name): # 这里是创建一个画布 fig, ax = plt.subplots() im = ax.imshow(harvest, cmap="OrRd") # 这里是修改标签 # We want to show all ticks... ax.set_xticks(np.arange(len(y_labels))) ax.set_yticks(np.arange(len(x_labels))) # ... and label them with the respective list entries ax.set_xticklabels(y_labels) ax.set_yticklabels(x_labels) # 因为x轴的标签太长了,需要旋转一下,更加好看 # Rotate the tick labels and set their alignment. plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor") # 添加每个热力块的具体数值 # Loop over data dimensions and create text annotations. for i in range(len(x_labels)): for j in range(len(y_labels)): text = ax.text(j, i, round(harvest[i, j], 2), ha="center", va="center", color="black") ax.set_xlabel("Predict label") ax.set_ylabel("Actual label") ax.set_title(title) fig.tight_layout() plt.colorbar(im) plt.savefig(save_name, dpi=100) if __name__ == '__main__': data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式 valid_transforms = data_transforms['val'] # 验证集数据集处理方式 test_dataset = datasets.ImageFolder(params["test_dir"], valid_transforms) class_names = test_dataset.classes print(class_names) test_loader = DataLoader( # 按照批次加载训练集 test_dataset, batch_size=params['batch_size'], shuffle=True, num_workers=params['num_workers'], pin_memory=True, ) # 加载模型 model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'], pretrained=False) # 加载模型结构,这里不需要加载预训练模式,所以模型结构过程中pretrained设置为False即可。 weights = torch.load(model_path) model.load_state_dict(weights) model.eval() model.to(device) # 指标上的测试结果包含三个方面,分别是acc、f1和recall, 除此之外,还有相应的热力图输出 acc, f1, recall = test(test_loader, model, params, class_names) print("测试结果:") print(f"acc: {acc}, F1: {f1}, recall: {recall}") print("测试集识别准确率: {0}%".format(acc*100.0)) print("测试完成,Crack Detect保存在{}下".format("record"))
测试结果
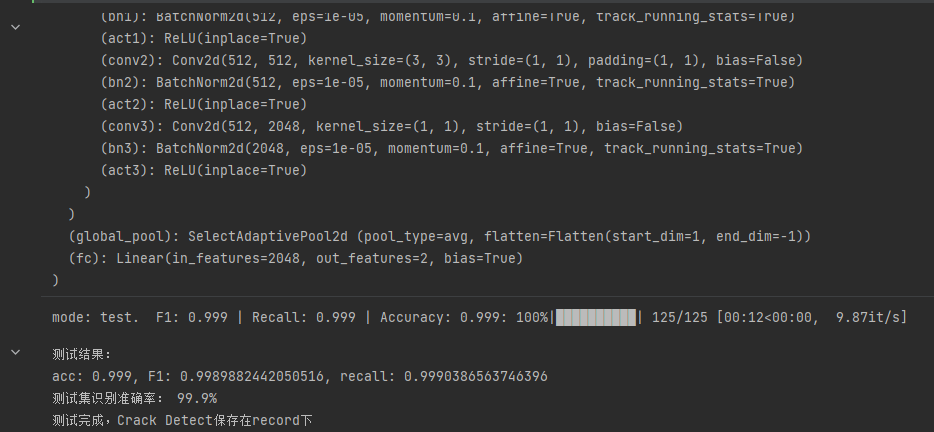

(六)结果分析
由输出的图像数据形状可知,通过转换为灰度图和调整图片大小等操作确实使得图片的数据量有了很大的减小。 而在对图像数据进行逻辑斯谛回归 计算之后得到的准确率也是较高的,但是下方出现的警告的表明仍然存在计算过多的问题
(七)主要代码
import os from PIL import Image import numpy as np import cv2 #定义了一个函数create_dataset #path是文件路径,存在找不到文件的情况时候需要对其进行修改 #label是图片对应的标签,用于区分不同种类的图片 def create_dataset(path, label): images = [] #用于储存处理之后的图片 imgw = 64 #图片处理之后的宽度 for filename in os.listdir(path): #遍历文件内的图片 img = cv2.imread(os.path.join(path, filename)) #读取图片 img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #转换为灰度图 imgmean = np.sum(img) / 227 / 227 #计算图像矩阵内所有像素点的平均值(灰度均值) img = cv2.resize(img, (imgw,imgw)) #调整图片大小 imglen = imgw * imgw #计算得到图像矩阵的面积,即像素总数 imglenp = 0 #初始化灰度值小于灰度均值的像素点数量为0 imgmeanp = 0 #初始化灰度值小于灰度均值的像素点的灰度值总和为0 cross = 8 #图像分割时使用8连通,及判定像素点和周围像素点的连接关系时考虑周围的8 #计算图像亮度标准化因子并生成细分图像 for i in range(0,imgw // cross): #处理图片中每个像素点的灰度值 for j in range(0,imgw // cross): if img[i * cross,j * cross]>imgmean: imglenp = imglenp + 1 #所有采样像素点的灰度值总和 imgmeanp =imgmeanp + img[i * cross,j * cross] #如果像素点的灰度值大于平均值,采样数+1并计算所有采样像素点灰度 if imglenp > 0: imgmeanp = imgmeanp / imglenp img = abs(img / imgmeanp -1) #abs函数可以确保归一化后的像素值(像素点的灰度值)只有正数 else: img = abs(img / imgmean -1) img = np.array(img).reshape(-1, 1) #将处理后的数据变为一维的数据存储 images.append(img) #将处理后的图片和对应的标签存储起来 images = np.asarray(images) #将图片列表转换为numpy数组 labels = np.ones((len(images),)) * label # 将图片对应的标签储存为一个一维数组 return images, labels Positive_path = 'Dataset/Positive' Negative_path = 'Dataset/Negative' #图片所在的路径 #对两种图片进行处理和存储,将图片数组和标签分别存储为Positive_images, Positive_labels
Positive_images, Positive_labels = create_dataset(Positive_path, 1) Negative_images, Negative_labels = create_dataset(Negative_path, 0) # 将两个数据集合并,并且打乱顺序 #将存储两种样本的数组堆叠起来形成一个新的images,np.vstack表示将两个数组进行垂直方向上的堆叠 images = np.vstack((Positive_images, Negative_images)) #将存储两种样本标签的数组堆叠起来形成一个新的labels,np.concatenate表示将两个数组进行水平方向上的拼接 labels = np.concatenate((Positive_labels, Negative_labels)) #生成一个随机排列 indices = np.random.permutation(len(images)) #将原有的images和labels之间的对应关系打破,并将含有裂纹和不含裂纹两种数据混合在一起 images = images[indices] labels = labels[indices] print(images.shape) print(labels)
from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # 将三维数组转换为二维数组 images_flat = images.reshape(images.shape[0], -1) # 划分训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(images_flat, labels, test_size=0.2) # 定义逻辑回归分类器 classifier = LogisticRegression() # 训练分类器 classifier.fit(x_train, y_train) # 在测试集上测试分类器的准确率 score = classifier.score(x_test, y_test) print("测试集识别准确率:{}%".format(score*100))



总结
可能是因为逻辑回归是一种较为基础的分类算法, 相比于深度学习模型(如CNN模型),其模型复杂度较低,因此在复杂度较高的数据集上表现也会更差一些。而CNN模型作为一种深度学习模型, 能够利用多层卷积和池化等操作学习图像中更加丰富和抽象的特征表示,在视觉分类等方面有着非常广泛的应用,并且在很多数据集上都能取得很好 的表现。因此,若是对于复杂的图像数据集,采用基于CNN模型的分类算法可能会获得更好的分类性能。 通过这次研究性学习我们对于如何处理图 像数据有了更多的认识,尤其是预处理方面的操作。同时对之前所学到的逻辑斯谛回归也有了深刻的了解。通过使用逻辑回归作为分类算法,发现该 模型能够在一定程度上对图像进行简单分类,但是,在面对更加复杂的数据集时,可能需要更深入的特征提取和更强大的分类模型,例如采用卷积神 经网络(CNN)进行图像分类,能够获得更好的分类效果。
总代码
import os import random import shutil from shutil import copy2 import os.path as osp def data_set_split(src_data_folder, target_data_folder, train_scale=0.6, val_scale=0.2, test_scale=0.2): print("开始数据集划分") class_names = os.listdir(src_data_folder) # 在目标目录下创建文件夹 split_names = ['train', 'val', 'test'] for split_name in split_names: split_path = os.path.join(target_data_folder, split_name) if os.path.isdir(split_path): pass else: os.mkdir(split_path) # 然后在split_path的目录下创建类别文件夹 for class_name in class_names: class_split_path = os.path.join(split_path, class_name) if os.path.isdir(class_split_path): pass else: os.mkdir(class_split_path) # 按照比例划分数据集,并进行数据图片的复制 # 首先进行分类遍历 for class_name in class_names: current_class_data_path = os.path.join(src_data_folder, class_name) current_all_data = os.listdir(current_class_data_path) current_data_length = len(current_all_data) current_data_index_list = list(range(current_data_length)) random.shuffle(current_data_index_list) train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name) val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name) test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name) train_stop_flag = current_data_length * train_scale val_stop_flag = current_data_length * (train_scale + val_scale) current_idx = 0 train_num = 0 val_num = 0 test_num = 0 for i in current_data_index_list: src_img_path = os.path.join(current_class_data_path, current_all_data[i]) if current_idx <= train_stop_flag: copy2(src_img_path, train_folder) train_num = train_num + 1 elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag): copy2(src_img_path, val_folder) val_num = val_num + 1 else: copy2(src_img_path, test_folder) test_num = test_num + 1 current_idx = current_idx + 1 print("*********************************{}*************************************".format(class_name)) print( "{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length)) print("训练集{}:{}张".format(train_folder, train_num)) print("验证集{}:{}张".format(val_folder, val_num)) print("测试集{}:{}张".format(test_folder, test_num)) if __name__ == '__main__': src_data_folder = "/media/neaucs2/tc/dataset/Crack/Dataset" # 原始数据集路径 target_data_folder = src_data_folder + "_" + "split" if osp.isdir(target_data_folder): print("target folder 已存在, 正在删除...") shutil.rmtree(target_data_folder) os.mkdir(target_data_folder) print("Target folder 创建成功") data_set_split(src_data_folder, target_data_folder) print("*****************************************************************") print("数据集划分完成,请在{}目录下查看".format(target_data_folder)) #%% # 数据增强和测试指标的代码集中在这里 # 导入必备的包 import numpy as np import pandas as pd import os from PIL import Image import cv2 import math # 网络模型构建需要的包 import torch import torchvision import timm import torch.nn as nn import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from tqdm import tqdm from collections import defaultdict import matplotlib.pyplot as plt from sklearn.preprocessing import LabelEncoder, OneHotEncoder from sklearn.model_selection import train_test_split, cross_validate, StratifiedKFold, cross_val_score # Metric 测试准确率需要的包 from sklearn.metrics import f1_score, accuracy_score, recall_score # Augmentation 数据增强要使用到的包 import albumentations from albumentations.pytorch.transforms import ToTensorV2 from torchvision import datasets, models, transforms # 这个库主要用于定义如何进行数据增强。 # https://zhuanlan.zhihu.com/p/149649900?from_voters_page=true def get_torch_transforms(img_size=224): data_transforms = { 'train': transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.RandomHorizontalFlip(p=0.2), transforms.RandomRotation((-5, 5)), transforms.RandomAutocontrast(p=0.2), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } return data_transforms # 训练集的预处理以及数据增强 def get_train_transforms(img_size=320): return albumentations.Compose( [ albumentations.Resize(img_size, img_size), albumentations.HorizontalFlip(p=0.5), albumentations.VerticalFlip(p=0.5), albumentations.Rotate(limit=180, p=0.7), albumentations.ShiftScaleRotate( shift_limit=0.25, scale_limit=0.1, rotate_limit=0 ), albumentations.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225], max_pixel_value=255.0, always_apply=True ), ToTensorV2(p=1.0), ] ) # 验证集和测试集的预处理 def get_valid_transforms(img_size=224): return albumentations.Compose( [ albumentations.Resize(img_size, img_size), albumentations.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225], max_pixel_value=255.0, always_apply=True ), ToTensorV2(p=1.0) ] ) # 加载csv格式的数据 class LeafDataset(Dataset): def __init__(self, images_filepaths, labels, transform=None): self.images_filepaths = images_filepaths # 数据集路径是个列表 self.labels = labels # 标签也是个列表 self.transform = transform # 数据增强 def __len__(self): # 返回数据的长度 return len(self.images_filepaths) def __getitem__(self, idx): # 迭代器,这里使用的是cv,所以一定不要出现中文路径 image_filepath = self.images_filepaths[idx] image = cv2.imread(image_filepath) # 读取图片 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 图片的颜色通道转化 label = self.labels[idx] # 读取图片标签 if self.transform is not None: # 对图片做处理 image = self.transform(image=image)["image"] # 这个转化做的是传入一个图片,返回的是一个字典,我们应该将转化之后的图片那部分取出 # 返回处理之后的图片和标签 return image, label # 测试准确率 def accuracy(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() return accuracy_score(target, y_pred) # 计算f1 def calculate_f1_macro(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() return f1_score(target, y_pred, average='macro') # 计算recall def calculate_recall_macro(output, target): y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu() target = target.cpu() # tp fn fp return recall_score(target, y_pred, average="macro", zero_division=0) # 训练的时候输出信息使用 class MetricMonitor: def __init__(self, float_precision=3): self.float_precision = float_precision self.reset() def reset(self): self.metrics = defaultdict(lambda: {"val": 0, "count": 0, "avg": 0}) def update(self, metric_name, val): metric = self.metrics[metric_name] metric["val"] += val metric["count"] += 1 metric["avg"] = metric["val"] / metric["count"] def __str__(self): return " | ".join( [ "{metric_name}: {avg:.{float_precision}f}".format( metric_name=metric_name, avg=metric["avg"], float_precision=self.float_precision ) for (metric_name, metric) in self.metrics.items() ] ) # 调整学习率 def adjust_learning_rate(optimizer, epoch, params, batch=0, nBatch=None): """ adjust learning of a given optimizer and return the new learning rate """ new_lr = calc_learning_rate(epoch, params['lr'], params['epochs'], batch, nBatch) for param_group in optimizer.param_groups: param_group['lr'] = new_lr return new_lr """ learning rate schedule """ # 计算学习率 def calc_learning_rate(epoch, init_lr, n_epochs, batch=0, nBatch=None, lr_schedule_type='cosine'): if lr_schedule_type == 'cosine': t_total = n_epochs * nBatch t_cur = epoch * nBatch + batch lr = 0.5 * init_lr * (1 + math.cos(math.pi * t_cur / t_total)) elif lr_schedule_type is None: lr = init_lr else: raise ValueError('do not support: %s' % lr_schedule_type) return lr #%% # from torchutils import * from torchvision import datasets, models, transforms import numpy as np import os.path as osp import torch.nn as nn import os import ssl import torch import matplotlib %matplotlib inline # matplotlib.use('TkAgg') ssl._create_default_https_context = ssl._create_unverified_context if torch.cuda.is_available(): device = torch.device('cuda:0') else: device = torch.device('cpu') print(f'Using device: {device}') # 固定随机种子,保证实验结果是可以复现的 seed = 42 os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True data_path = "/media/neaucs2/tc/dataset/Crack/Dataset_split" # 数据集路径 # 超参数设置 params = { # 'model': 'vit_tiny_patch16_224', # 选择预训练模型 'model': 'resnet50d', # 选择预训练模型 # 'model': 'efficientnet_b3a', # 选择预训练模型 "img_size": 227, # 图片输入大小 "train_dir": osp.join(data_path, "train"), # 训练集路径 "val_dir": osp.join(data_path, "val"), # 验证集路径 'device': device, # 设备 'lr': 1e-3, # 学习率 'batch_size': 64, # 批次大小 'num_workers': 0, # 进程 'epochs': 10, # 轮数 "save_dir": "../checkpoints_new/", # 保存路径 "pretrained": False, "num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目 'weight_decay': 1e-5 # 学习率衰减 } # 定义模型 class SELFMODEL(nn.Module): def __init__(self, model_name=params['model'], out_features=params['num_classes'], pretrained=True): super().__init__() self.model = timm.create_model(model_name, pretrained=pretrained) # 从预训练的库中加载模型 # classifier if model_name[:3] == "res": n_features = self.model.fc.in_features # 修改全连接层数目 self.model.fc = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目 elif model_name[:3] == "vit": n_features = self.model.head.in_features # 修改全连接层数目 self.model.head = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目 else: n_features = self.model.classifier.in_features self.model.classifier = nn.Linear(n_features, out_features) # resnet修改最后的全链接层 print(self.model) # 返回模型 def forward(self, x): # 前向传播 x = self.model(x) return x # 定义训练流程 def train(train_loader, model, criterion, optimizer, epoch, params): metric_monitor = MetricMonitor() # 设置指标监视器 model.train() # 模型设置为训练模型 nBatch = len(train_loader) stream = tqdm(train_loader) for i, (images, target) in enumerate(stream, start=1): # 开始训练 images = images.to(params['device'], non_blocking=True) # 加载数据 target = target.to(params['device'], non_blocking=True) # 加载模型 output = model(images) # 数据送入模型进行前向传播 loss = criterion(output, target.long()) # 计算损失 f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算准确率分数 metric_monitor.update('Loss', loss.item()) # 更新损失 metric_monitor.update('F1', f1_macro) # 更新f1 metric_monitor.update('Recall', recall_macro) # 更新recall metric_monitor.update('Accuracy', acc) # 更新准确率 optimizer.zero_grad() # 清空学习率 loss.backward() # 损失反向传播 optimizer.step() # 更新优化器 lr = adjust_learning_rate(optimizer, epoch, params, i, nBatch) # 调整学习率 stream.set_description( # 更新进度条 "Epoch: {epoch}. Train. {metric_monitor}".format( epoch=epoch, metric_monitor=metric_monitor) ) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"] # 返回结果 # 定义验证流程 def validate(val_loader, model, criterion, epoch, params): metric_monitor = MetricMonitor() # 验证流程 model.eval() # 模型设置为验证格式 stream = tqdm(val_loader) # 设置进度条 with torch.no_grad(): # 开始推理 for i, (images, target) in enumerate(stream, start=1): images = images.to(params['device'], non_blocking=True) # 读取图片 target = target.to(params['device'], non_blocking=True) # 读取标签 output = model(images) # 前向传播 loss = criterion(output, target.long()) # 计算损失 f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算acc metric_monitor.update('Loss', loss.item()) # 后面基本都是更新进度条的操作 metric_monitor.update('F1', f1_macro) metric_monitor.update("Recall", recall_macro) metric_monitor.update('Accuracy', acc) stream.set_description( "Epoch: {epoch}. Validation. {metric_monitor}".format( epoch=epoch, metric_monitor=metric_monitor) ) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"] # 展示训练过程的曲线 def show_loss_acc(acc, loss, val_acc, val_loss, sava_dir): # 从history中提取模型训练集和验证集准确率信息和误差信息 # 按照上下结构将图画输出 plt.figure(figsize=(8, 8)) plt.subplot(2, 1, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.ylabel('Accuracy') plt.ylim([min(plt.ylim()), 1]) plt.title('Training and Validation Accuracy') plt.subplot(2, 1, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.ylabel('Cross Entropy') plt.title('Training and Validation Loss') plt.xlabel('epoch') # 保存在savedir目录下。 save_path = osp.join(save_dir, "results.png") plt.savefig(save_path, dpi=100) if __name__ == '__main__': accs = [] losss = [] val_accs = [] val_losss = [] data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式 train_transforms = data_transforms['train'] # 训练集数据处理方式 valid_transforms = data_transforms['val'] # 验证集数据集处理方式 train_dataset = datasets.ImageFolder(params["train_dir"], train_transforms) # 加载训练集 valid_dataset = datasets.ImageFolder(params["val_dir"], valid_transforms) # 加载验证集 if params['pretrained'] == True: save_dir = osp.join(params['save_dir'], params['model']+"_pretrained_" + str(params["img_size"])) # 设置模型保存路径 else: save_dir = osp.join(params['save_dir'], params['model'] + "_nopretrained_" + str(params["img_size"])) # 设置模型保存路径 if not osp.isdir(save_dir): # 如果保存路径不存在的话就创建 os.makedirs(save_dir) # print("save dir {} created".format(save_dir)) train_loader = DataLoader( # 按照批次加载训练集 train_dataset, batch_size=params['batch_size'], shuffle=True, num_workers=params['num_workers'], pin_memory=True, ) val_loader = DataLoader( # 按照批次加载验证集 valid_dataset, batch_size=params['batch_size'], shuffle=False, num_workers=params['num_workers'], pin_memory=True, ) print(train_dataset.classes) model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'], pretrained=params['pretrained']) # 加载模型 # model = nn.DataParallel(model) # 模型并行化,提高模型的速度 # resnet50d_1epochs_accuracy0.50424_weights.pth model = model.to(params['device']) # 模型部署到设备上 criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数 optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器 # 损失函数和优化器可以自行设置修改。 # criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数 # optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器 best_acc = 0.0 # 记录最好的准确率 # 只保存最好的那个模型。 for epoch in range(1, params['epochs'] + 1): # 开始训练 acc, loss = train(train_loader, model, criterion, optimizer, epoch, params) val_acc, val_loss = validate(val_loader, model, criterion, epoch, params) accs.append(acc) losss.append(loss) val_accs.append(val_acc) val_losss.append(val_loss) if val_acc >= best_acc: # 保存的时候设置一个保存的间隔,或者就按照目前的情况,如果前面的比后面的效果好,就保存一下。 # 按照间隔保存的话得不到最好的模型。 save_path = osp.join(save_dir, f"{params['model']}_{epoch}epochs_accuracy{acc:.5f}_weights.pth") torch.save(model.state_dict(), save_path) best_acc = val_acc show_loss_acc(accs, losss, val_accs, val_losss, save_dir) print("训练已完成,模型和训练日志保存在: {}".format(save_dir)) #%% # from torchutils import * from torchvision import datasets, models, transforms import os.path as osp import os if torch.cuda.is_available(): device = torch.device('cuda:0') else: device = torch.device('cpu') print(f'Using device: {device}') # 固定随机种子,保证实验结果是可以复现的 seed = 42 os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True # noqa torch.backends.cudnn.benchmark = True # noqa data_path = "/media/neaucs2/tc/dataset/Crack/Dataset_split/" # 修改为数据集根目录 model_path = "/media/neaucs2/tc/111/checkpoints_new/resnet50d_nopretrained_227/resnet50d_8epochs_accuracy0.99547_weights.pth" # todo 模型地址 model_name = 'resnet50d' # 模型名称 img_size = 227 # 数据集训练时输入模型的大小 # 超参数设置 params = { # 'model': 'vit_tiny_patch16_224', # 选择预训练模型 # 'model': 'efficientnet_b3a', # 选择预训练模型 'model': model_name, # 选择预训练模型 "img_size": img_size, # 图片输入大小 "test_dir": osp.join(data_path, "test"), # 测试集子目录 'device': device, # 设备 'batch_size': 64, # 批次大小 'num_workers': 0, # 进程 "num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目 } # 定义测试流程 def test(val_loader, model, params, class_names): metric_monitor = MetricMonitor() # 验证流程 model.eval() # 模型设置为验证格式 stream = tqdm(val_loader) # 设置进度条 # 对模型分开进行推理 test_real_labels = [] test_pre_labels = [] with torch.no_grad(): # 开始推理 for i, (images, target) in enumerate(stream, start=1): images = images.to(params['device'], non_blocking=True) # 读取图片 target = target.to(params['device'], non_blocking=True) # 读取标签 output = model(images) # 前向传播 target_numpy = target.cpu().numpy() y_pred = torch.softmax(output, dim=1) y_pred = torch.argmax(y_pred, dim=1).cpu().numpy() test_real_labels.extend(target_numpy) test_pre_labels.extend(y_pred) f1_macro = calculate_f1_macro(output, target) # 计算f1分数 recall_macro = calculate_recall_macro(output, target) # 计算recall分数 acc = accuracy(output, target) # 计算acc metric_monitor.update('F1', f1_macro) # 后面基本都是更新进度条的操作 metric_monitor.update("Recall", recall_macro) metric_monitor.update('Accuracy', acc) stream.set_description( "mode: {epoch}. {metric_monitor}".format( epoch="test", metric_monitor=metric_monitor) ) class_names_length = len(class_names) heat_maps = np.zeros((class_names_length, class_names_length)) for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels): heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1 heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1) heat_maps_float = heat_maps / heat_maps_sum show_heatmaps(title="Crack Detect", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float, save_name="Crack_Detect_{}.png".format(model_name)) return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['F1']["avg"], \ metric_monitor.metrics['Recall']["avg"] # 绘制测试热力图 def show_heatmaps(title, x_labels, y_labels, harvest, save_name): # 这里是创建一个画布 fig, ax = plt.subplots() im = ax.imshow(harvest, cmap="OrRd") # 这里是修改标签 # We want to show all ticks... ax.set_xticks(np.arange(len(y_labels))) ax.set_yticks(np.arange(len(x_labels))) # ... and label them with the respective list entries ax.set_xticklabels(y_labels) ax.set_yticklabels(x_labels) # 因为x轴的标签太长了,需要旋转一下,更加好看 # Rotate the tick labels and set their alignment. plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor") # 添加每个热力块的具体数值 # Loop over data dimensions and create text annotations. for i in range(len(x_labels)): for j in range(len(y_labels)): text = ax.text(j, i, round(harvest[i, j], 2), ha="center", va="center", color="black") ax.set_xlabel("Predict label") ax.set_ylabel("Actual label") ax.set_title(title) fig.tight_layout() plt.colorbar(im) plt.savefig(save_name, dpi=100) if __name__ == '__main__': data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式 valid_transforms = data_transforms['val'] # 验证集数据集处理方式 test_dataset = datasets.ImageFolder(params["test_dir"], valid_transforms) class_names = test_dataset.classes print(class_names) test_loader = DataLoader( # 按照批次加载训练集 test_dataset, batch_size=params['batch_size'], shuffle=True, num_workers=params['num_workers'], pin_memory=True, ) # 加载模型 model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'], pretrained=False) # 加载模型结构,这里不需要加载预训练模式,所以模型结构过程中pretrained设置为False即可。 weights = torch.load(model_path) model.load_state_dict(weights) model.eval() model.to(device) # 指标上的测试结果包含三个方面,分别是acc、f1和recall, 除此之外,还有相应的热力图输出 acc, f1, recall = test(test_loader, model, params, class_names) print("测试结果:") print(f"acc: {acc}, F1: {f1}, recall: {recall}") print("测试集识别准确率: {0}%".format(acc*100.0)) print("测试完成,Crack Detect保存在{}下".format("record"))
