

爬取B站热门视频并进行可视化分析
(一)选题背景
爬虫是从互联网上抓取对于我们有价值的信息。选择此题正是因为随着信息化的发展,大数据时代对信息的采需求和集量越来越大,相应的处理量也越来越大,正是因为如此,爬虫相应的岗位也开始增多,因此,学好这门课也是为将来就业打下扎实的基础。bilibili在当今众多视频网站中,有许多年轻人都在使用这个软件,通过爬取其中热门视频爬取b站热门视频的各各板块,从播放量,点赞数,弹幕数,分享数,投币数,收藏数,分析当代年轻人对什么类型的视频更加喜爱
(二)主题式网络爬虫设计方案
1.主题式网络爬虫名称:
爬取B站热门视频并进行可视化分析
2.主题式网络爬虫爬取的内容与数据特征分析
内容:爬取b站热门视频的各各板块,从播放量,点赞数,弹幕数,分享数,投币数,收藏数进行可视化分析
特征分析:对播放量,点赞数,弹幕数,分享数,投币数,收藏数计数,然后进行可视化
3.主题式网络爬虫设计方案概述
思路:爬取数据,进行可视化。
难点:词云生成产生错误
(三)数据源
爬取数据地址:
(四)具体步骤
爬取数据
解析数据源网页
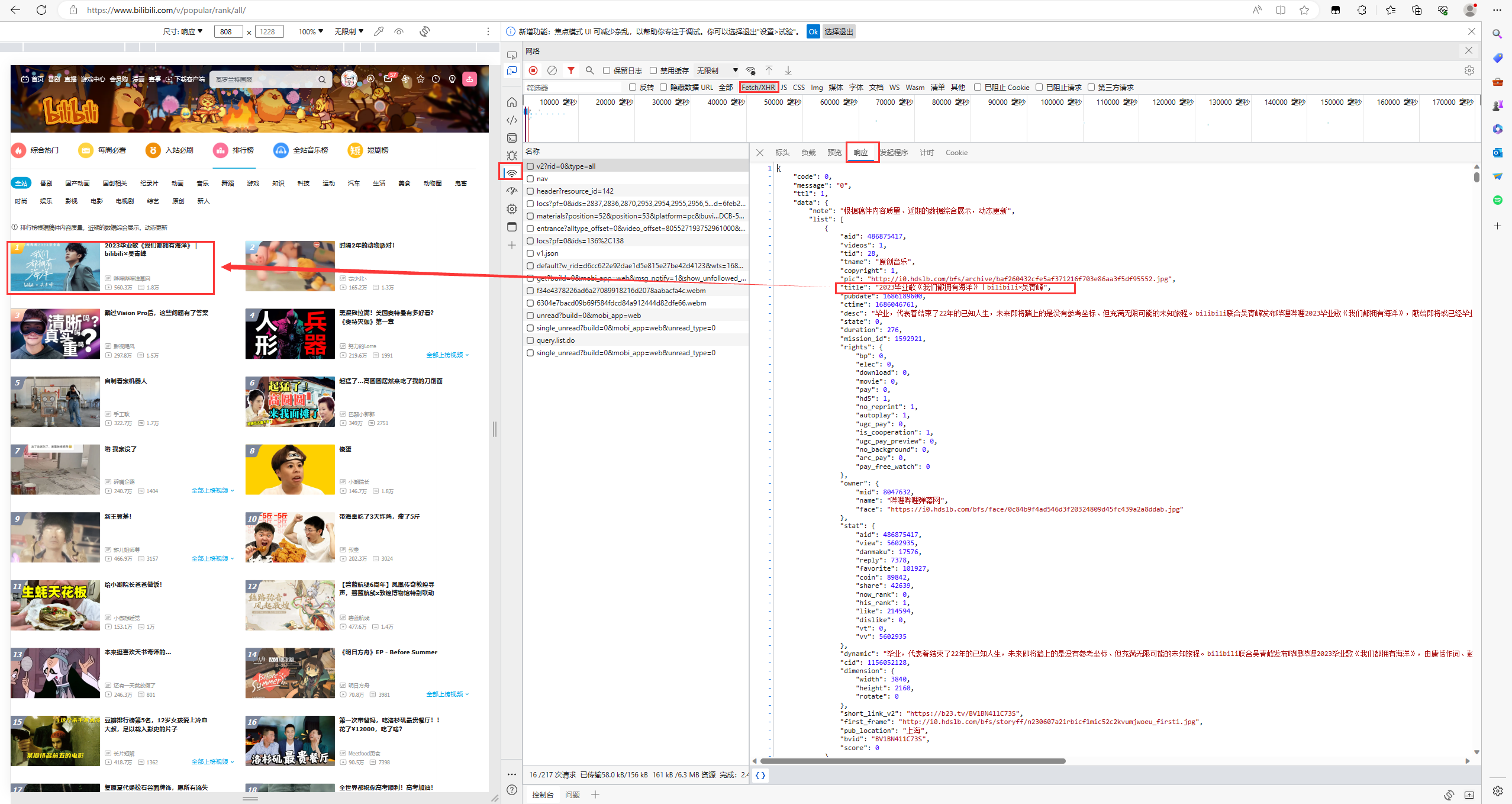
可以看到,页面分为不同的版块,包括全站、番剧、国产动面等等。用Chrome浏览器,右键打开开发者模式,选择网络->XHR这个选项,重新刷新一下页面,依次查看每个链接的预览内容,通过链接返回的数据,找出目标
爬取代码
import requests import pandas as pd
确定url地址

url_dict = { '全站': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all', # '番剧': 'https://api.bilibili.com/pgc/web/rank/list?day=3&season_type=1', # # '国产动画': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=4', # # '国创相关': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=168&type=all', # # '纪录片': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=3', # '动画': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=1&type=all', '音乐': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=3&type=all', '舞蹈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=129&type=all', '游戏': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=4&type=all', '知识': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=36&type=all', '科技': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=188&type=all', '运动': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=234&type=all', '汽车': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=223&type=all', '生活': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=160&type=all', '美食': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=211&type=all', '动物圈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=217&type=all', '鬼畜': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=119&type=all', '时尚': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=155&type=all', '娱乐': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=5&type=all', '影视': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=181&type=all', # # '电影': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=2', # # # '电视剧': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=5', # '原创': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=origin', '新人': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=rookie', }
伪装
headers = { 'Accept': 'application/json, text/plain, */*', 'Origin': 'https://www.bilibili.com', 'Host': 'api.bilibili.com', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Safari/605.1.15', 'Accept-Language': 'zh-cn', 'Connection': 'keep-alive', 'Referer': 'https://www.bilibili.com/v/popular/rank/all' }
获得数据
for i in url_dict.items(): url = i[1] # url地址 tab_name = i[0] # tab页名称 title_list = [] play_cnt_list = [] # 播放数 danmu_cnt_list = [] # 播放数 coin_cnt_list = [] # 投币数 like_cnt_list = [] # 点赞数 dislike_cnt_list = [] # 点踩数 share_cnt_list = [] # 分享数 favorite_cnt_list = [] # 收藏数 author_list = [] score_list = [] video_url = []
然后,经过分析返回数据的json格式 然后,经过分析返回数据的json格式
print(r.status_code)
# pprint(r.content.decode('utf-8'))
# r.encoding = 'utf-8'
# pprint(r.json())
json_data = r.json()
list_data = json_data['data']['list']
for data in list_data:
title_list.append(data['title'])
play_cnt_list.append(data['stat']['view'])
danmu_cnt_list.append(data['stat']['danmaku'])
coin_cnt_list.append(data['stat']['coin'])
like_cnt_list.append(data['stat']['like'])
dislike_cnt_list.append(data['stat']['dislike'])
share_cnt_list.append(data['stat']['share'])
favorite_cnt_list.append(data['stat']['favorite'])
author_list.append(data['owner']['name'])
score_list.append(data['score'])
video_url.append('https://www.bilibili.com/video/' + data['bvid'])
except Exception as e:
print("爬取失败:{}".format(str(e)))
最后,将DataFrame数据保存到excel
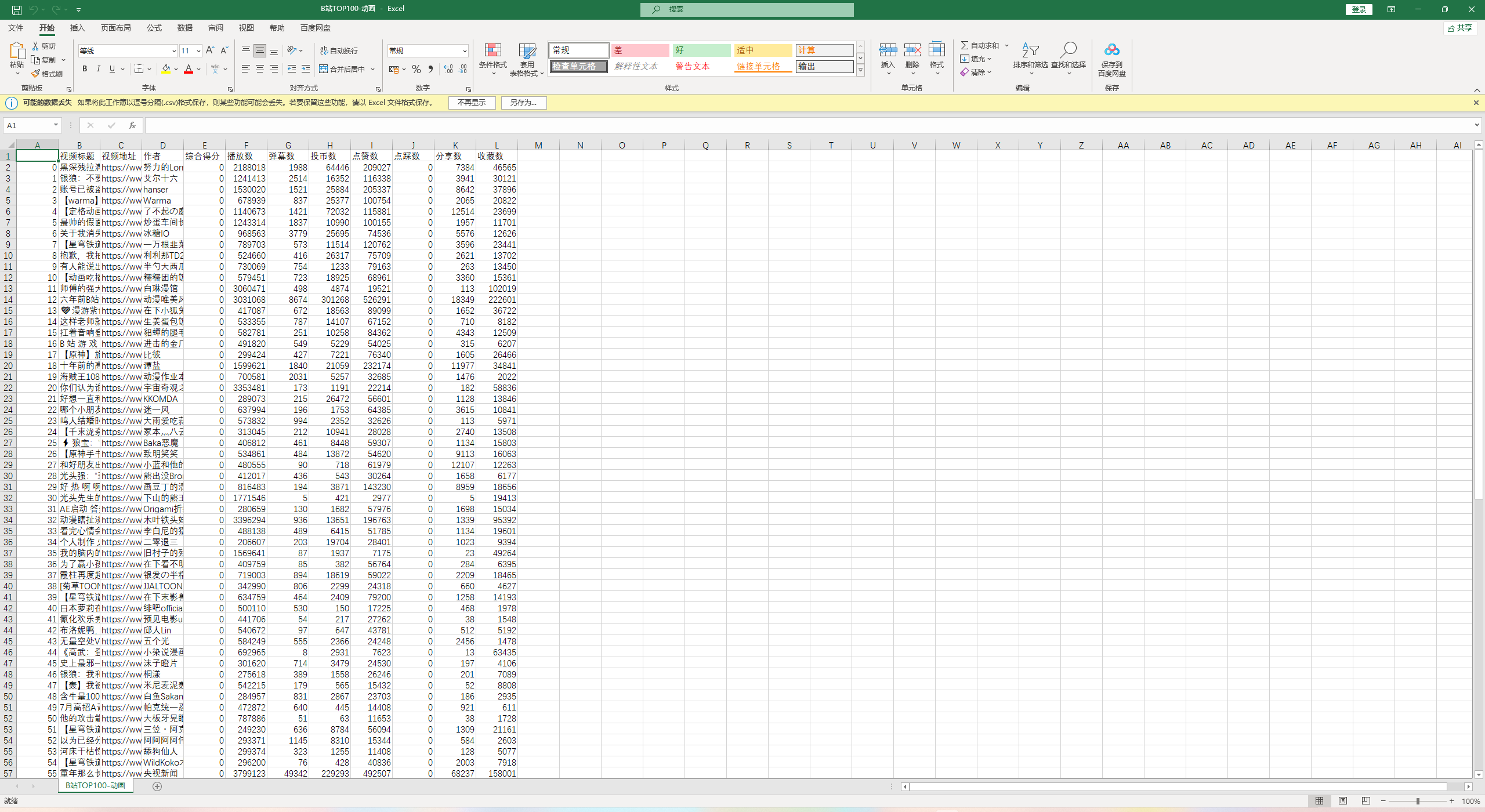
df = pd.DataFrame( {'视频标题': title_list, '视频地址': video_url, '作者': author_list, '综合得分': score_list, '播放数': play_cnt_list, '弹幕数': danmu_cnt_list, '投币数': coin_cnt_list, '点赞数': like_cnt_list, '点踩数': dislike_cnt_list, '分享数': share_cnt_list, '收藏数': favorite_cnt_list, }) df.to_csv('B站TOP100-{}.csv'.format(tab_name), encoding='utf_8_sig') # utf_8_sig修复乱码问题 print('写入成功: ' + 'B站TOP100-{}.csv'.format(tab_name)) df = pd.read_csv(csv)
查看结果
爬取的模块

模块查看
数据可视话分析
导入库
import pandas as pd import matplotlib.pyplot as plt from wordcloud import ImageColorGenerator, WordCloud import numpy as np from PIL import Image
数据读取
df = pd.read_csv(csv)
数据概览,用shape查看数据形状
df.shape
用head查看前5行
df.head(5)
用info查看信息
df.info()
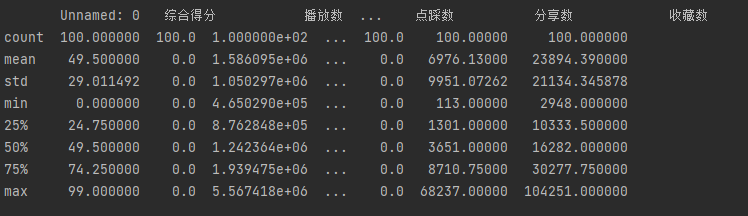
用describe查看统计性分析
df.describe()
数据清洗
查看是否存在真空值
df.isna().any()
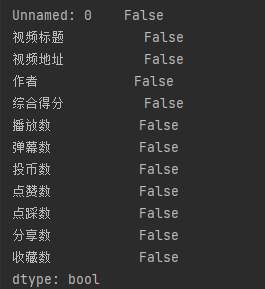
每一列都是False没有空值
查看是否存在重复值
df.duplicated().any()

看到False没有重复值
删除没有列
df.drop(['点踩数', '综合得分'], axis=1, inplace=True)
因为其踩点都是0所以没有意义
删除后查看结果

可视化分析
数据中,有播放数、弹幕数、投币数、点赞数、分享数、收藏数等众多数据指标。我想分析出,这些指标中,谁和综合得分的关系最大,决定性最高。
直接采用pandas自带的corr函数,得出相关性(spearman相关)矩阵:
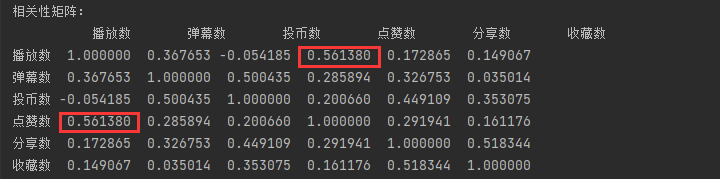
可以看出,点赞数和综合得分的相关性最高,达到了0.56。
根据此分析结论,进一步画出点赞数和综合得分的分布散点图,验证此结论的正确性。
plt.figure(figsize=(20, 8)) plt.title('相关性分析: 播放数x点赞数', fontdict={'size': 20}) plt.xlabel('点赞数') plt.ylabel('播放数') plt.scatter(x, y) plt.savefig('相关性分析-散点图.png')

得出结论:随着点赞数增多,综合得分呈明显上升趋势,进一步得出,二者存在正相关的关系。
饼图
综合得分划分分布区间,绘制出分布饼图。
bins = [0, 1500000, 2000000, 2500000, 3000000, 10000000] labels = [ '0-150w', '150w-200w', '200w-250w', '250w-300w', '300w-1000w' ]
绘制饼图
segments = pd.cut(score_list, bins, labels=labels) counts = pd.value_counts(segments, sort=False).values.tolist() plt.figure(figsize=(20, 8)) plt.pie(counts, labels=labels, colors=['cyan', 'yellowgreen', 'lightskyblue', 'aquamarine', 'aliceblue'], # explode=(0.15, 0, 0, 0, 0), autopct='%.2f%%', ) plt.title("播放数-分布饼图") plt.savefig('播放数-饼图.png')

得出结论:综合得分在0至150w这个区间的视频最多,有62个视频(占比62%)
箱形图
把这几个数据指标,绘制在同一张图里
df_play = df['播放数'] df_danmu = df['弹幕数'] df_coin = df['投币数'] df_like = df['点赞数'] df_share = df['分享数'] df_fav = df['收藏数'] plt.figure(figsize=(20, 8)) plt.title('数据分布-箱型图', fontdict={'size': 20}) plt.boxplot([ df_play, df_danmu, df_coin, df_like, df_share, df_fav, ], labels=[ '播放数', '弹幕数', '投币数', '点赞数', '分享数', '收藏数', ]) plt.ylabel('数量') plt.savefig('箱型图分析_一张图.png')
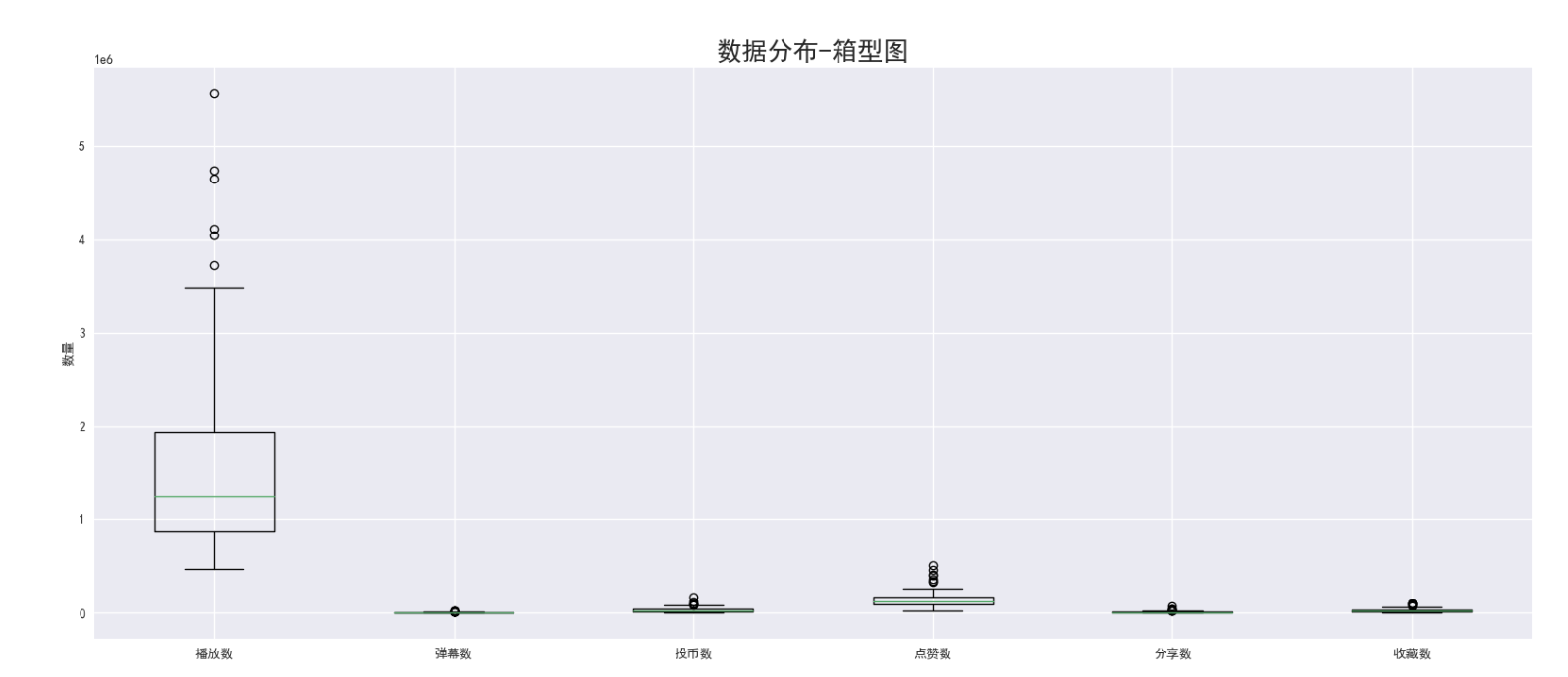
由于播放数远远大于其他数据指标,不在一个数量级,导致其他数据指标的box都挤到一块了,可视化效果很差,所以,每个box画到一个图里,避免这种情况的发生
plt.figure(figsize=(20, 8)) plt.subplot(2, 3, 1) plt.boxplot(df_play) plt.title('播放数') plt.subplot(2, 3, 2) plt.boxplot(df_danmu) plt.title('弹幕数') plt.subplot(2, 3, 3) plt.boxplot(df_coin) plt.title('投币数') plt.subplot(2, 3, 4) plt.boxplot(df_like) plt.title('点赞数') plt.subplot(2, 3, 5) plt.boxplot(df_share) plt.title('分享数') plt.subplot(2, 3, 6) plt.boxplot(df_fav) plt.title('收藏数') plt.suptitle("各指标数据分布-箱型图", fontsize=20) plt.savefig('箱型图分析_多张图.png')
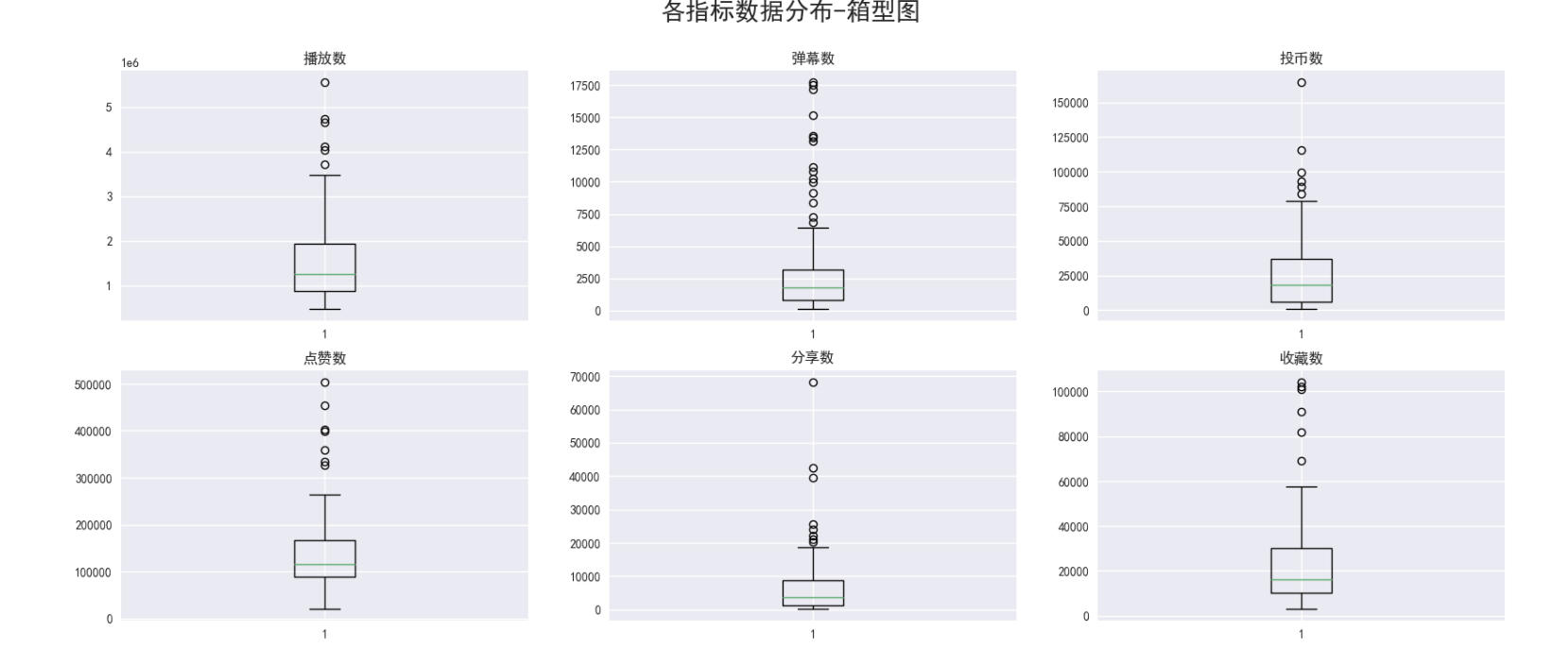
得出结论:每个数据指标都存在极值的情况(最大值距离box很远),数据比较离散,方差较大。
词云图
author_list = df['作者'].values.tolist() author_str = ' '.join(author_list) stopwords = [] coloring = np.array(Image.open("背景图.jpeg")) backgroud_Image = coloring wc = WordCloud( scale=5, margin=0, background_color="black", max_words=1200, width=200, height=200, font_path='C:\Windows\Fonts\simsunb.ttf', stopwords=stopwords, mask=backgroud_Image, color_func=ImageColorGenerator(coloring), random_state=800 ) wc.generate_from_text(author_str) wc.to_file('视频作者_词云图.png') print('图片已生成: 视频作者_词云图.png')

词云出现了错误无法显示中文而产生问题出在
font_path='C:\Windows\Fonts\simsunb.ttf',
(五)总代码
import requests import pandas as pd url_dict = { '全站': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all', # '番剧': 'https://api.bilibili.com/pgc/web/rank/list?day=3&season_type=1', # # '国产动画': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=4', # # '国创相关': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=168&type=all', # # '纪录片': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=3', # '动画': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=1&type=all', '音乐': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=3&type=all', '舞蹈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=129&type=all', '游戏': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=4&type=all', '知识': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=36&type=all', '科技': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=188&type=all', '运动': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=234&type=all', '汽车': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=223&type=all', '生活': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=160&type=all', '美食': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=211&type=all', '动物圈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=217&type=all', '鬼畜': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=119&type=all', '时尚': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=155&type=all', '娱乐': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=5&type=all', '影视': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=181&type=all', # # '电影': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=2', # # # '电视剧': 'https://api.bilibili.com/pgc/season/rank/web/list?day=3&season_type=5', # '原创': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=origin', '新人': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=rookie', } headers = { 'Accept': 'application/json, text/plain, */*', 'Origin': 'https://www.bilibili.com', 'Host': 'api.bilibili.com', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Safari/605.1.15', 'Accept-Language': 'zh-cn', 'Connection': 'keep-alive', 'Referer': 'https://www.bilibili.com/v/popular/rank/all' } for i in url_dict.items(): url = i[1] tab_name = i[0] title_list = [] play_cnt_list = [] danmu_cnt_list = [] coin_cnt_list = [] like_cnt_list = [] dislike_cnt_list = [] share_cnt_list = [] favorite_cnt_list = [] author_list = [] score_list = [] video_url = [] try: r = requests.get(url, headers=headers) print(r.status_code) # pprint(r.content.decode('utf-8')) # r.encoding = 'utf-8' # pprint(r.json()) json_data = r.json() list_data = json_data['data']['list'] for data in list_data: title_list.append(data['title']) play_cnt_list.append(data['stat']['view']) danmu_cnt_list.append(data['stat']['danmaku']) coin_cnt_list.append(data['stat']['coin']) like_cnt_list.append(data['stat']['like']) dislike_cnt_list.append(data['stat']['dislike']) share_cnt_list.append(data['stat']['share']) favorite_cnt_list.append(data['stat']['favorite']) author_list.append(data['owner']['name']) score_list.append(data['score']) video_url.append('https://www.bilibili.com/video/' + data['bvid']) print('*' * 30) except Exception as e: print("爬取失败:{}".format(str(e))) df = pd.DataFrame( {'视频标题': title_list, '视频地址': video_url, '作者': author_list, '综合得分': score_list, '播放数': play_cnt_list, '弹幕数': danmu_cnt_list, '投币数': coin_cnt_list, '点赞数': like_cnt_list, '点踩数': dislike_cnt_list, '分享数': share_cnt_list, '收藏数': favorite_cnt_list, }) df.to_csv('B站TOP100-{}.csv'.format(tab_name), encoding='utf_8_sig') print('写入成功: ' + 'B站TOP100-{}.csv'.format(tab_name)) df = pd.read_csv(csv)
import pandas as pd import matplotlib.pyplot as plt from wordcloud import ImageColorGenerator, WordCloud import numpy as np from PIL import Image plt.style.use('seaborn') plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False csv = 'B站TOP100-全站.csv' df = pd.read_csv(csv) print(df.shape) print(df.head(5)) print(df.info()) print(df.describe()) print(df.isna().any()) print(df.duplicated().any()) print('columns:') print(df.columns) df.drop(['点踩数', '综合得分'], axis=1, inplace=True) print('删除后的columns:') print(df.columns) df_corr = df[['播放数', '弹幕数', '投币数', '点赞数', '分享数', '收藏数']] print('相关性矩阵:') print(df_corr.corr(method='spearman')) x = df['点赞数'] y = df['播放数'] plt.figure(figsize=(20, 8)) plt.title('相关性分析: 播放数x点赞数', fontdict={'size': 20}) plt.xlabel('点赞数') plt.ylabel('播放数') plt.scatter(x, y) plt.savefig('相关性分析-散点图.png') # plt.show() score_list = df['播放数'].values.tolist() bins = [0, 1500000, 2000000, 2500000, 3000000, 10000000] labels = [ '0-150w', '150w-200w', '200w-250w', '250w-300w', '300w-1000w' ] segments = pd.cut(score_list, bins, labels=labels) counts = pd.value_counts(segments, sort=False).values.tolist() plt.figure(figsize=(20, 8)) plt.pie(counts, labels=labels, colors=['cyan', 'yellowgreen', 'lightskyblue', 'aquamarine', 'aliceblue'], # explode=(0.15, 0, 0, 0, 0), autopct='%.2f%%', ) plt.title("播放数-分布饼图") plt.savefig('播放数-饼图.png') # plt.show() df_play = df['播放数'] df_danmu = df['弹幕数'] df_coin = df['投币数'] df_like = df['点赞数'] df_share = df['分享数'] df_fav = df['收藏数'] plt.figure(figsize=(20, 8)) plt.title('数据分布-箱型图', fontdict={'size': 20}) plt.boxplot([ df_play, df_danmu, df_coin, df_like, df_share, df_fav, ], labels=[ '播放数', '弹幕数', '投币数', '点赞数', '分享数', '收藏数', ]) plt.ylabel('数量') plt.savefig('箱型图分析_一张图.png') # plt.show() plt.figure(figsize=(20, 8)) plt.subplot(2, 3, 1) plt.boxplot(df_play) plt.title('播放数') plt.subplot(2, 3, 2) plt.boxplot(df_danmu) plt.title('弹幕数') plt.subplot(2, 3, 3) plt.boxplot(df_coin) plt.title('投币数') plt.subplot(2, 3, 4) plt.boxplot(df_like) plt.title('点赞数') plt.subplot(2, 3, 5) plt.boxplot(df_share) plt.title('分享数') plt.subplot(2, 3, 6) plt.boxplot(df_fav) plt.title('收藏数') plt.suptitle("各指标数据分布-箱型图", fontsize=20) plt.savefig('箱型图分析_多张图.png') # 保存图片 # plt.show() author_list = df['作者'].values.tolist() author_str = ' '.join(author_list) stopwords = [] coloring = np.array(Image.open("背景图.jpeg")) backgroud_Image = coloring wc = WordCloud( scale=5, margin=0, background_color="black", max_words=1200, width=200, height=200, font_path='C:\Windows\Fonts\simsunb.ttf', stopwords=stopwords, mask=backgroud_Image, color_func=ImageColorGenerator(coloring), random_state=800 ) wc.generate_from_text(author_str) wc.to_file('视频作者_词云图.png') print('图片已生成: 视频作者_词云图.png')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构