

学号:2017035101029
姓名:薛朋
码云仓库:https://gitee.com/xp149/word_frequency
一:程序分析:

|
打开文件,并将读取的文件到缓冲区 |
|
|
将添加到缓存区的文件中的代码,进行统计,存放在word_freq中
|
|
|
输出TOP的单词 |

|
将文件分析 把文件分析后的结果输出
|


二:程序改进:
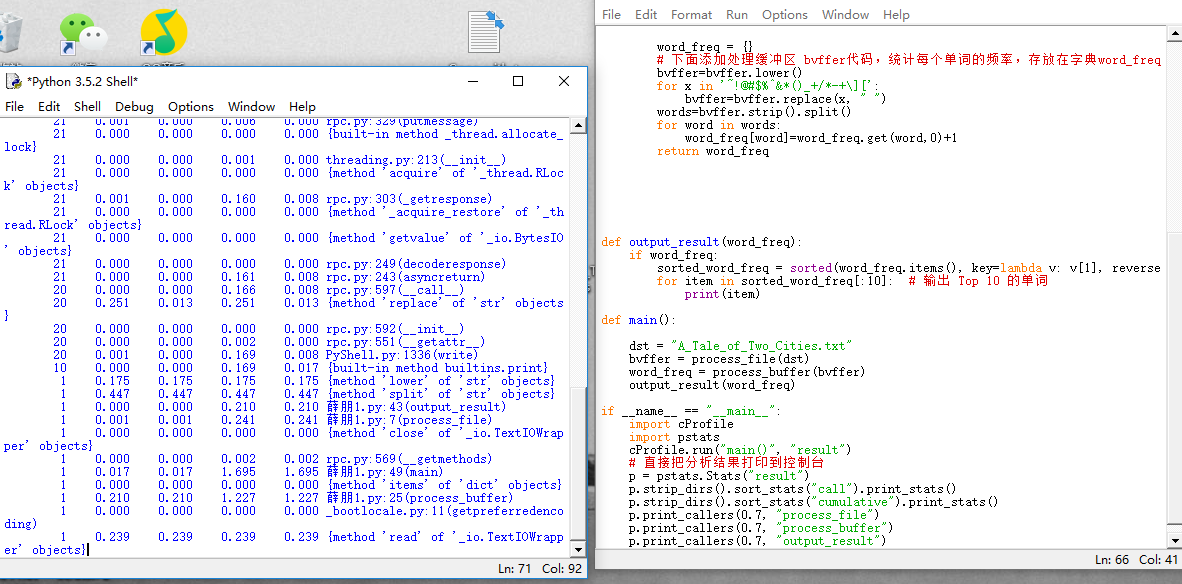
1.执行次数最多的代码

1 # filename: word_freq.py
2 # 阅读注释,在所有pass处删除pass,添加代码
3
4 from string import punctuation
5
6
7 def process_file(dst): # 读文件到缓冲区
8 try: # 打开文件
9 a =open("Gone_with_the_wind.txt","r")
10
11
12 except IOError:
13 print
14 return None
15 try: # 读文件到缓冲区
16 bvffer = a.read()
17 except:
18 print ("Read File Error!")
19 return None
20 a.close()
21
22 return bvffer
23
24
25 def process_buffer(bvffer):
26 if bvffer:
27
28 word_freq = {}
29 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
30 bvffer=bvffer.lower()
31 for x in '~!@#$%^&*()_+/*-+\][':
32 bvffer=bvffer.replace(x, " ")
33 words=bvffer.strip().split()
34 for word in words:
35 word_freq[word]=word_freq.get(word,0)+1
36 return word_freq
37
38
39
40
41
42
43 def output_result(word_freq):
44 if word_freq:
45 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
46 for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
47 print(item)
48
49 def main():
50
51 dst = "A_Tale_of_Two_Cities.txt"
52 bvffer = process_file(dst)
53 word_freq = process_buffer(bvffer)
54 output_result(word_freq)
55
56 if __name__ == "__main__":
57 import cProfile
58 import pstats
59 cProfile.run("main()", "result")
60 # 直接把分析结果打印到控制台
61 p = pstats.Stats("result")
62 p.strip_dirs().sort_stats("call").print_stats()
63 p.strip_dirs().sort_stats("cumulative").print_stats()
64 p.print_callers(0.7, "process_file")
65 p.print_callers(0.7, "process_buffer")
66 p.print_callers(0.7, "output_result")
2.执行时间最长的代码
# filename: word_freq.py
# 阅读注释,在所有pass处删除pass,添加代码
from string import punctuation
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
a =open("Gone_with_the_wind.txt","r")
except IOError:
print
return None
try: # 读文件到缓冲区
bvffer = a.read()
except:
print ("Read File Error!")
return None
a.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
bvffer=bvffer.lower()
for x in '~!@#$%^&*()_+/*-+\][':
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
return word_freq
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
def main():
dst = "A_Tale_of_Two_Cities.txt"
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
if __name__ == "__main__":
import cProfile
import pstats
cProfile.run("main()", "result")
# 直接把分析结果打印到控制台
p = pstats.Stats("result")
p.strip_dirs().sort_stats("call").print_stats()
p.strip_dirs().sort_stats("cumulative").print_stats()
p.print_callers(0.7, "process_file")
p.print_callers(0.7, "process_buffer")
p.print_callers(0.7, "output_result")
3.程序改进优化的方法以及我的改进代码:提高输出速度和代码运行的时间,缩短代码运行的复杂步骤,节省楚更多的时间。
三:程序运行命令、运行结果截图以及改进后的程序运行命令及结果截图
程序运行命令:
python word_freq.py Gone_with_the_wind.txt
运行结果截图:
改进后的程序运行命令:
from string import punctuation
改进后运行结果截图:
给出你对此次任务的总结与反思:任务的代码太多 还要自己去改进和分析 代码有点难敲 作业有点不会 需要进一步提升。

