使用Navicat创建存储过程(顺带插入百万级数据量)
一、建表
DROP TABLE IF EXISTS `test_user`; CREATE TABLE `test_user` ( `id` bigint(20) PRIMARY key not null AUTO_INCREMENT, `username` varchar(11) DEFAULT NULL, `gender` varchar(2) DEFAULT NULL, `password` varchar(100) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
二、建立函数


将SQL放在下图位置处
while num <= 1000000 do insert into test_user(username,gender,password) values(num,'保密',PASSWORD(num)); set num=num+1;
end while;
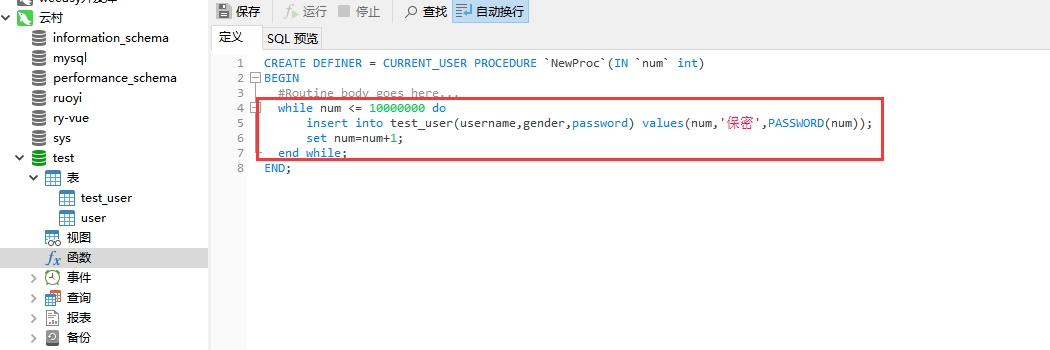
保存SQL,运行。
输入参数1,即从1开始插入一百万条数据。
耗时:27.996s


本文中使用的存储引擎为MyISAM。因为它不支持事务,所以插入数据才会如此之快。
若选择INNODB,插入一百万条数据则需要耗时:1297.971s。
附带数据(可自行测试):

参考:https://blog.csdn.net/qq_33556185/article/details/52192551



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)