

首先是爬”中国最好的大学“这个网站,相应代码如下(应为我是06号所以我爬的是2017)
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed May 22 22:34:04 2019 4 5 @author: m1353 6 """ 7 8 import requests 9 from bs4 import BeautifulSoup 10 alluniv = [] 11 def getHTMLText(url): 12 try: 13 r = requests.get(url,timeout = 30) 14 r.raise_for_status() 15 r.encoding = 'utf-8' 16 return r.text 17 except: 18 return "error" 19 def fillunivlist(soup): 20 data=soup.find_all('tr') 21 for tr in data: 22 ltd =tr.find_all('td') 23 if len(ltd)==0: 24 continue 25 singleuniv=[] 26 for td in ltd: 27 singleuniv.append(td.string) 28 alluniv.append(singleuniv) 29 def printunivlist(num): 30 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名字","省份","总分","培养规模")) 31 for i in range(num): 32 u=alluniv[i] 33 print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],eval(u[3]),u[6])) 34 def main(num): 35 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html" 36 html=getHTMLText(url) 37 soup=BeautifulSoup(html,"html.parser") 38 fillunivlist(soup) 39 printunivlist(num) 40 main(10)
main函数中的参数是索取其中的排名信息的个数
执行效果如下
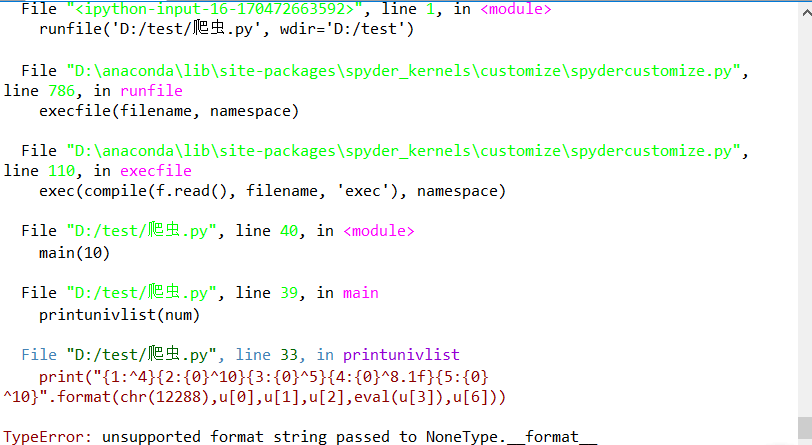
然后没有成功,但是我的代码没有错。。。因为我能爬2016,2019的截图如下
2016的如下

仅此修改了网页地址的一个数字
然后是2019的,如下图

嗯,都可以出来,所以我无辜的=3=
然后是开始爬谷歌网(我是06号)
代码如下(和上面的差不太多)
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed May 22 22:34:04 2019 4 5 @author: m1353 6 """ 7 8 import requests 9 from bs4 import BeautifulSoup 10 alluniv = [] 11 def getHTMLText(url): 12 try: 13 r = requests.get(url,timeout = 30) 14 r.raise_for_status() 15 r.encoding = 'utf-8' 16 return r.text 17 except: 18 return "error" 19 def xunhuang(url): 20 for i in range(20): 21 getHTMLText(url) 22 def fillunivlist(soup): 23 data=soup.find_all('tr') 24 for tr in data: 25 ltd =tr.find_all('td') 26 if len(ltd)==0: 27 continue 28 singleuniv=[] 29 for td in ltd: 30 singleuniv.append(td.string) 31 alluniv.append(singleuniv) 32 def printf(): 33 print("\n") 34 print("\n") 35 print("\n") 36 def main(): 37 url = "http://www.google.com" 38 html=getHTMLText(url) 39 xunhuang(url) 40 print(html) 41 soup=BeautifulSoup(html,"html.parser") 42 fillunivlist(soup) 43 print(html) 44 printf() 45 print(soup.title) 46 printf() 47 print(soup.head) 48 printf() 49 print(soup.body) 50 main()
输出的结果如下图

中间还有一大堆。。。。
省略到最后面几句

划红线为输出的title标签


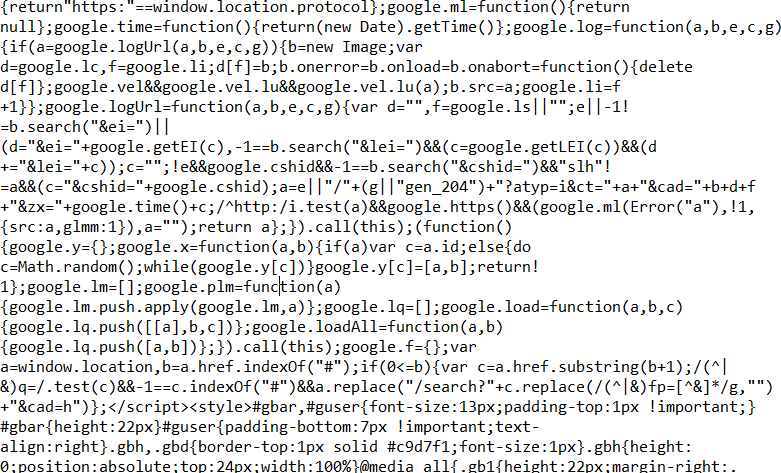

嗯,这一部分是head部分(好多=3=)





好,这里是body部分(真的好长啊)
由于之前用了一个在td里面找tr,所以将一些“<tr>,<td>”标签给去掉了,然后就变成了这副模样

