
010、【byhy】 常见语法—— 起始 ^、结尾 $ 位置 和 单行、多行模式
一、 常见语法—— 起始、结尾位置 和 单行、多行模式
^ 表示匹配文本的 开头 位置。
正则表达式可以设定 单行模式 和 多行模式
如果是 单行模式 ,表示匹配 整个文本 的开头位置。
如果是 多行模式 ,表示匹配 文本每行 的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
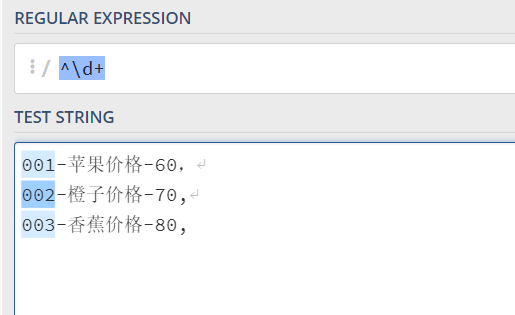
001-苹果价格-60, 002-橙子价格-70, 003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式 ^\d+
上面的正则表达式,使用在Python程序里面,如下所示
import re content = '''001-苹果价格-60 002-橙子价格-70 003-香蕉价格-80''' # re.M 表示多行模式,不加的话默认是单行模式 p = re.compile(r'^\d+', re.M) for one in p.findall(content): print(one) print('=====单行模式======') content = '''001-苹果价格-60 002-橙子价格-70 003-香蕉价格-80''' # 不加的话默认是单行模式 p1 = re.compile(r'^\d+') for one in p1.findall(content): print(one)
执行结果如下:
001
002
003
=====单行模式======
001
Process finished with exit code 0
因为单行模式下,^ 只会匹配整个文本的开头位置。
$ 表示匹配文本的 结尾 位置。
如果是 单行模式 ,表示匹配 整个文本 的结尾位置。
如果是 多行模式 ,表示匹配 文本每行 的结尾位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
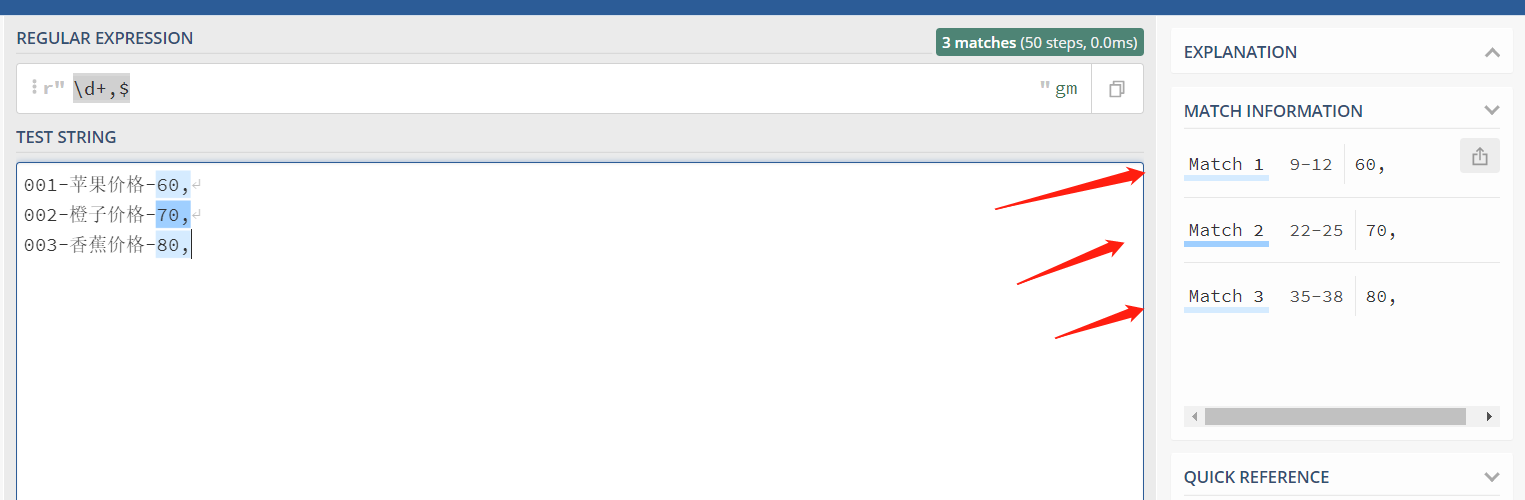
如果我们要提取所有的水果编号,用这样的正则表达式: \d+,$
对应代码
import re content = '''001-苹果价格-60, 002-橙子价格-70, 003-香蕉价格-80, ''' p = re.compile(r'\d+,$', re.MULTILINE) for one in p.findall(content): print(one)
注意,compile 的第二个参数 re.MULTILINE ,指明了使用多行模式,
运行结果如下:
60, 70, 80, Process finished with exit code 0
如果,去掉 compile 的第二个参数 re.MULTILINE:
import re content = '''001-苹果价格-60, 002-橙子价格-70, 003-香蕉价格-80, ''' print('=======多行模式=========') p = re.compile(r'\d+,$', re.MULTILINE) for one in p.findall(content): print(one) print('=======单行模式=========') p1 = re.compile(r'\d+,$') for one in p1.findall(content): print(one)
运行结果如下:
=======多行模式========= 60, 70, 80, =======单行模式========= 80, Process finished with exit code 0

