
【深度学习之YOLO8】环境部署
目录
Ultralytics YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 设计快速、准确且易于使用,使其成为各种物体检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
- Python SDK Download
- Ultralytics YOLOv8 GitHub
- PyTorch GitHub
- NVIDIA CUDA toolkit Download
- NVIDIA cuDNN Download
- Anaconda Download
除了拉取代码不需要验证,其他都需要自己check下到底是不是真安装成功了
一、确定版本
CUDA toolkit、cuDNN版本
- 查看显卡的CUDA支持的最高版本,我的是
12.2.79,后面安装的CUDA toolkit和cuDNN大版本不能超过它
[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblog.csdnim-n/7h1UWj1209abda6844c1803cc47a4fc2.png =360x3505100)( =300x300)] - 进PyTorch官网,查看支持的CUDA最高版本,我的torch是最高支持
11.8

由以上两点,得出安装的CUDA、cuDNN不能超11.8,那我后面这俩安装<=11.8
Python、PyTorch版本
torch、python各版本兼容情况表
| torch | torchvision | Python |
|---|---|---|
main / nightly | main / nightly | >=3.8, <=3.11 |
2.0 | 0.15 | >=3.8, <=3.11 |
1.13 | 0.14 | >=3.7.2, <=3.10 |
1.12 | 0.13 | >=3.7, <=3.10 |
1.11 | 0.12 | >=3.7, <=3.10 |
1.10 | 0.11 | >=3.6, <=3.9 |
1.9 | 0.10 | >=3.6, <=3.9 |
1.8 | 0.9 | >=3.6, <=3.9 |
1.7 | 0.8 | >=3.6, <=3.9 |
1.6 | 0.7 | >=3.6, <=3.8 |
1.5 | 0.6 | >=3.5, <=3.8 |
1.4 | 0.5 | ==2.7, >=3.5, <=3.8 |
1.3 | 0.4.2 / 0.4.3 | ==2.7, >=3.5, <=3.7 |
1.2 | 0.4.1 | ==2.7, >=3.5, <=3.7 |
1.1 | 0.3 | ==2.7, >=3.5, <=3.7 |
<=1.0 | 0.2 | ==2.7, >=3.5, <=3.7 |
上面有CUDA、cuDNN版本<=11.8
再在进PyTorch官网,预览一下DUDA<=11.8的有哪些
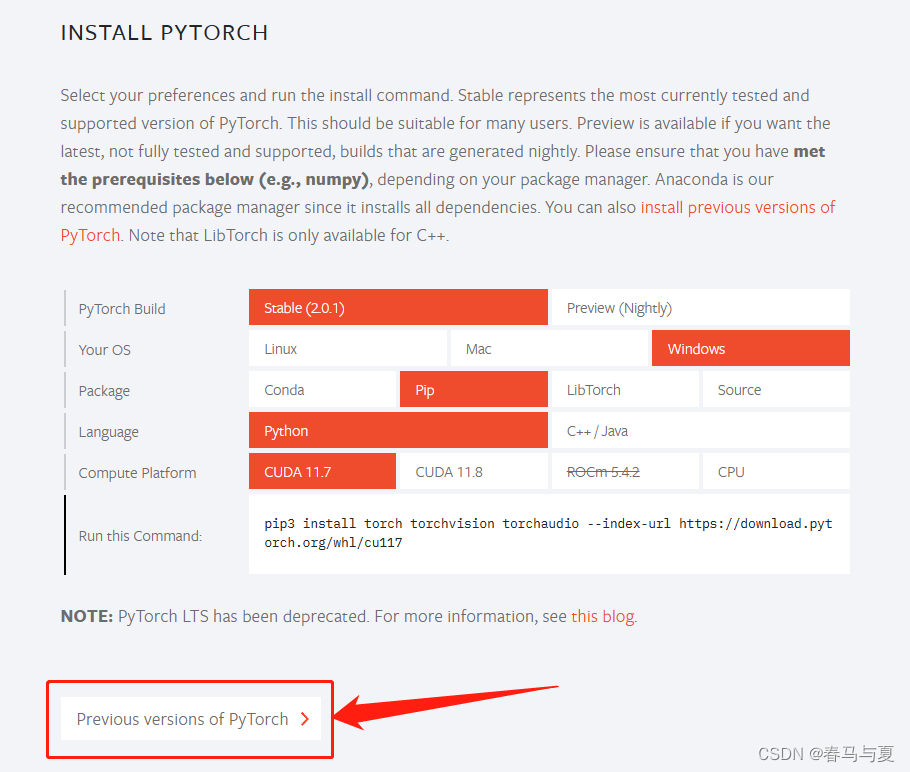

如果我用11.8的,看到PyTorch只有v2.0.0的,那么在上面 torch、python各版本兼容情况表 里可以得出:我的电脑CUDA、duDNN、PyTorch和Python互相兼容的py版本范围是3.8~3.11
所以,py版本不宜过高,每一个组件都有自己对其他组件的兼容范围,YOLO5的默认SDK版本是3.7,YOLO8的默认SDK版本是3.8
| 名 | 版本号 |
|---|---|
| Python | 3.8.0 |
| CUDA toolkit | 11.8.0 |
| cuDNN | 11.x |
| PyTorch | 2.0.0 |
| TorchAudio | 2.0.0 |
| TorchVision | 0.15.0 |
二、安装Python
下载
已经有Python的需要卸载干净,去官网找自己对应版本的安装包(要卸载哪个就找哪个版本的exe安装包),比如找
3.8.0的,下载运行点击Uninstall进行卸载
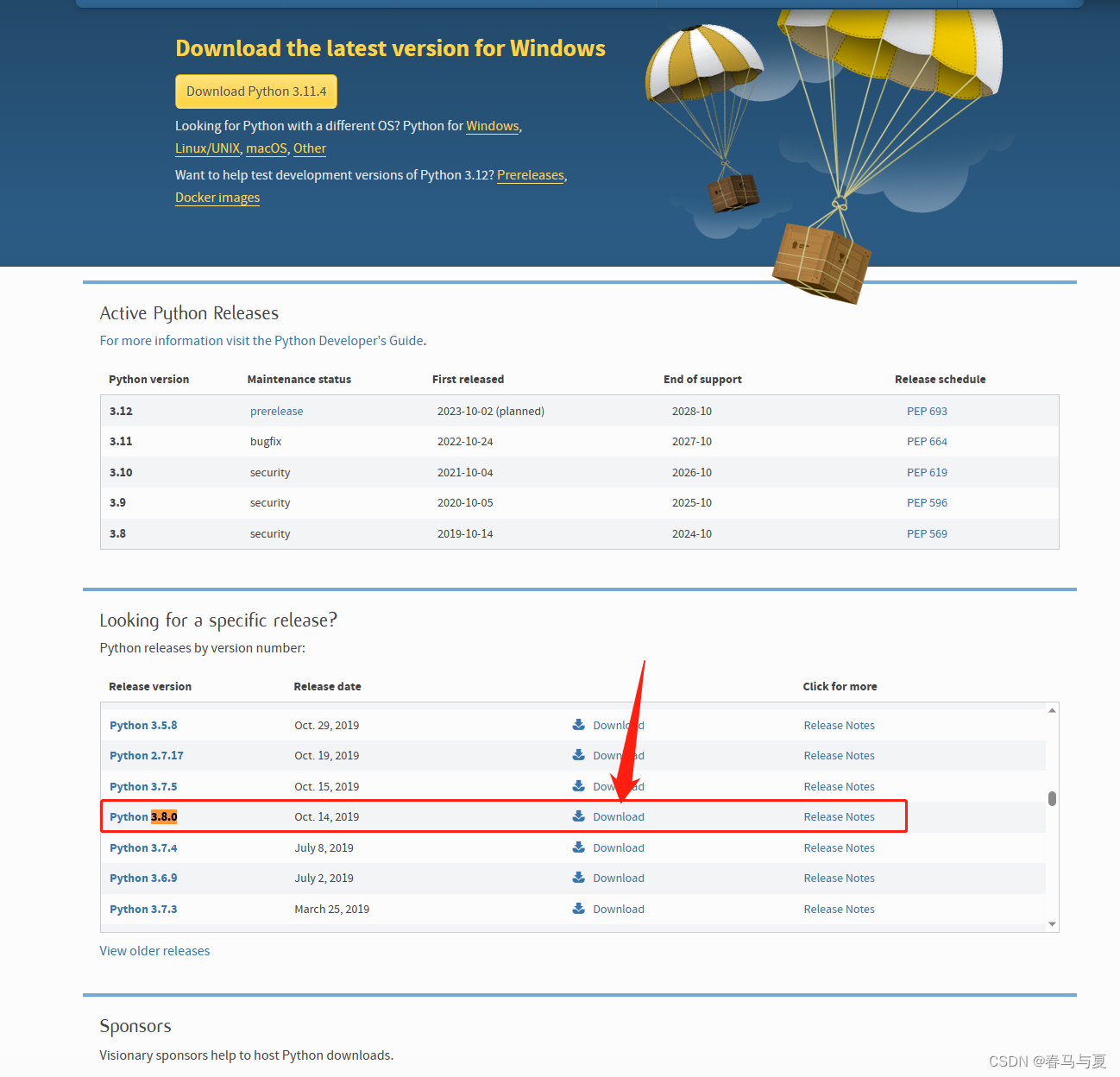


电脑无Python残留,或没有安装过Python,进官网版本列表下载自己要的版本,一路确认即可,尽量是不要安在有中文的路径下,后面的安装也是
环境变量
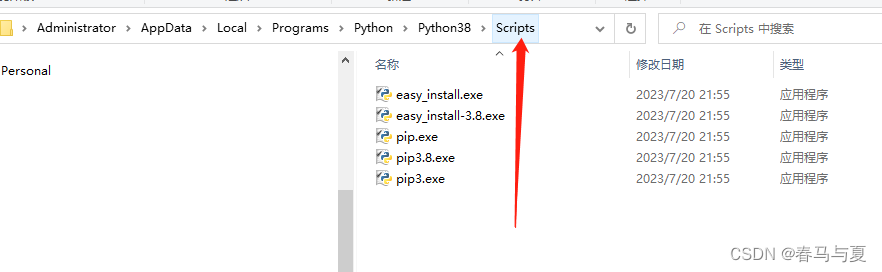
将Python安装目录和里面的Scripts文件夹路径放在Path里
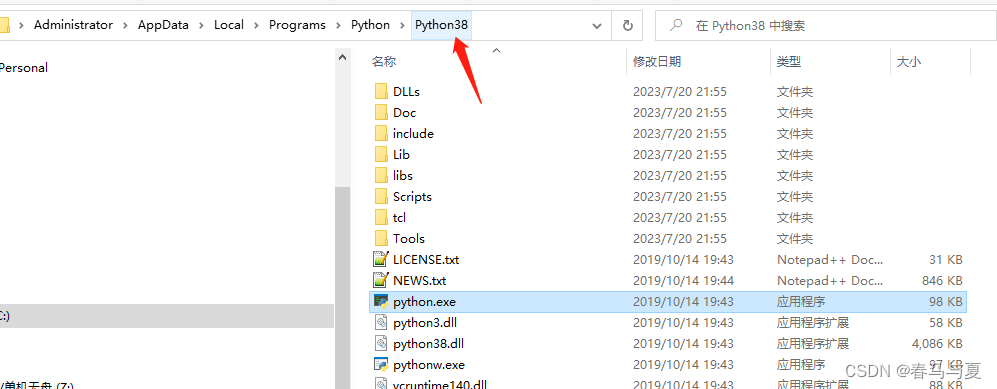
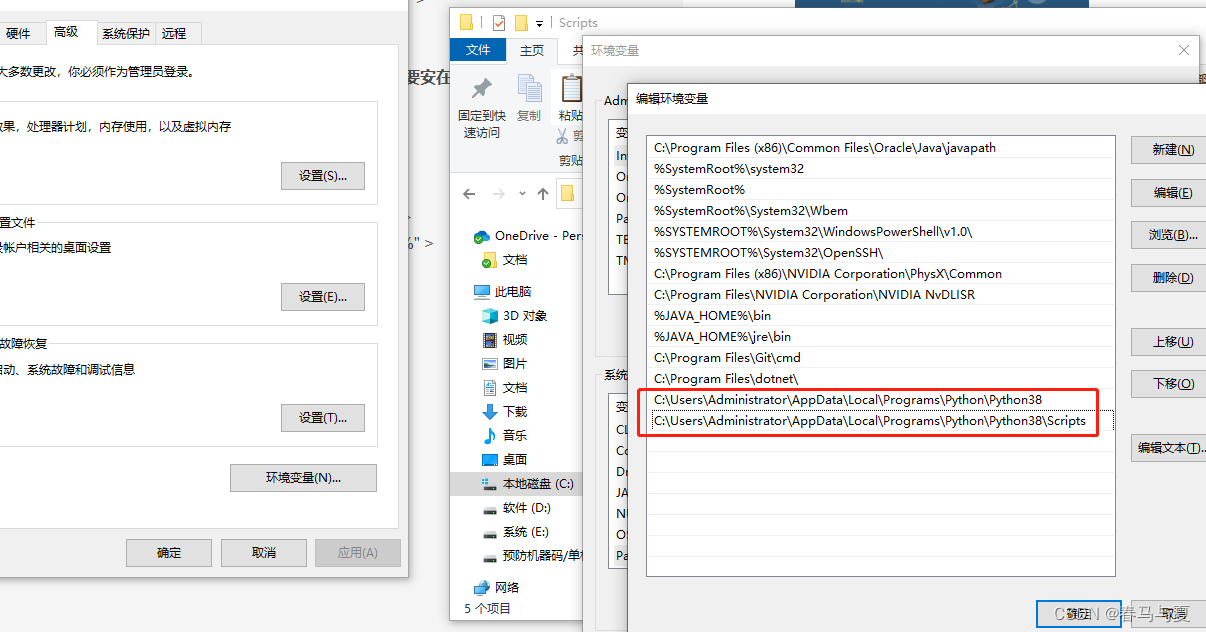
C:\Users\Administrator\AppData\Local\Programs\Python\Python38
C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Scripts
验证安装
win+r后键入cmd确认,出现版本号
python -V
或者
python --version

三、安装Anaconda
一个易于安装的包管理器、环境管理器和 Python 发行版,包含 1,500 多个开源包,并提供 免费社区支持。Anaconda与平台无关,因此无论在Windows、macOS还是Linux上都可以使用它,与它类似的有pip。
安装
进Anaconda官网,点下载,无脑下一步即可
环境变量
将以下四个路径添加进Path

验证安装
conda -V
创建conda虚拟环境
后面的操作都是基于这个虚拟环境,最好是用管理员打开终端
CommandNotFoundError: Your shell has not been properly configured to use ‘conda activate
第一次激活环境,可能有这个错误,根据提示使用conda init,重启cmd。或者使用source activate env_name使环境可用。
# 创建虚拟环境
conda create -n yolov8 python=3.8.0
# 激活虚拟环境(切换至这个环境)
conda activate yolov8
# 查看已创建的虚拟环境
conda info -e
常用命令
# 查看版本
conda --version # 或者 conda -V
# 更新conda
conda update conda
# 更新Anaconda
conda update Anaconda
# 查看环境配置
conda config --show
# 查看安装了哪些包
conda list
# 查看Anaconda仓库有没有这个想要的包
conda search package_name
# 新增镜像channel
conda config --add channels mirrors_url
# 移除镜像channel
conda config --add channels mirrors_url
# 查看配了哪些镜像channel
conda config --show channels
# 设置清华镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
# 设置bioconda
conda config --add channels bioconda
conda config --add channels conda-forge
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
# 创建虚拟环境
conda create -n env_name python=3.8
# 查看虚拟环境
conda env list #或conda info -e 或conda info --envs
# 激活虚拟环境
conda activate env_name
# 退出当前虚拟环境
conda deactivate
# 删除虚拟环境
conda remove -n env_name --all
# 安装包(在当前虚拟环境)
conda install package_name=package_version
# 更新包(在当前虚拟环境)
conda update package_name
# 删除包(在当前虚拟环境)
conda remove --name env_name package_name
# 卸载包
conda uninstall package_name
# 增量卸载包(如果有虚拟环境在用,会跳过这个小包,就是不全卸载)
conda uninstall package_name --force
# 删除没有在用的包
conda clean -p
# 清理缓存
conda clean -y -all
# 变更Python版本
conda install python=3.5 #升级到最新版conda update python
# 查看配置文件地址 (默认`C:\Users\用户名\.condarc`)
conda info #user config file那行
# conda初始化
conda init
四、安装CUDA toolkit
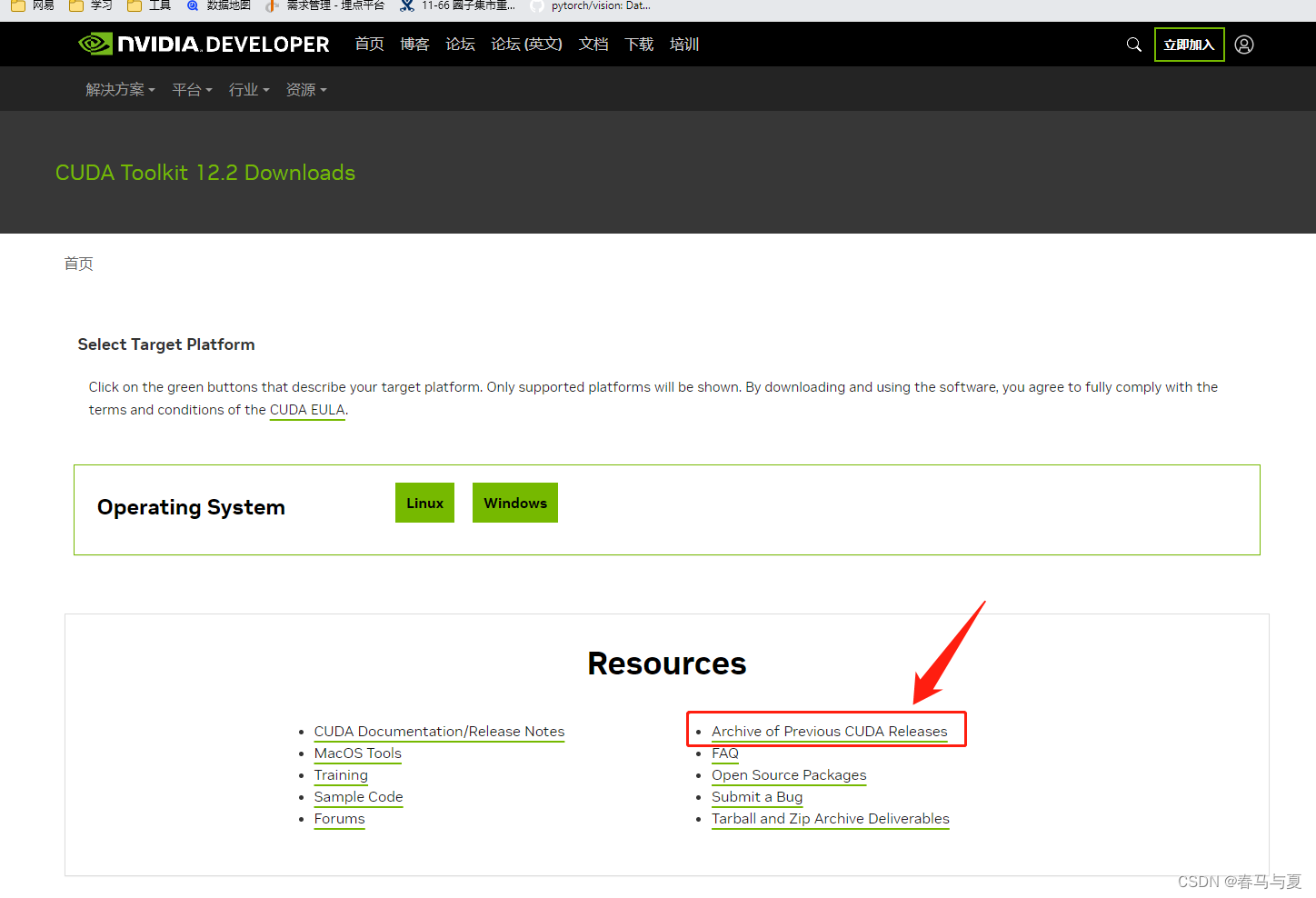
下载
官网下载,跳转翻阅之前版本,找到CUDA-11.8.0下载



环境变量
默认安装在:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
Path加入:lib\x64文件夹、include文件夹(安装默认配了bin和libnvvp)。

验证安装
cmd窗口输入:nvcc -V

或者
cmd切换CUDA安装目录,进extras/demo_suite目录,执行里面的bandwidthTest.exe,再执行deviceQuery.exe,结果显示PASS即是成功

五、配置cuDNN
通俗点讲,cuDNN就是CUDA toolkit的一个补丁,深度学习需要这个补丁才能使用API驱动GPU的CUDA
下载
进官网,需要登陆NVIDIA账号,并且注册成开发者,完成后进入下载界面

解压,全选复制,黏贴到CUDA安装目录,全部"是"即可

六、安装PyTorch(torch+torchversion+torchaudio)
一种开源深度学习框架,以出色的灵活性和易用性著称。
下载
打开cmd,进入之前创建的虚拟环境yolov8,复制torch官网conda语句,安装PyTorch
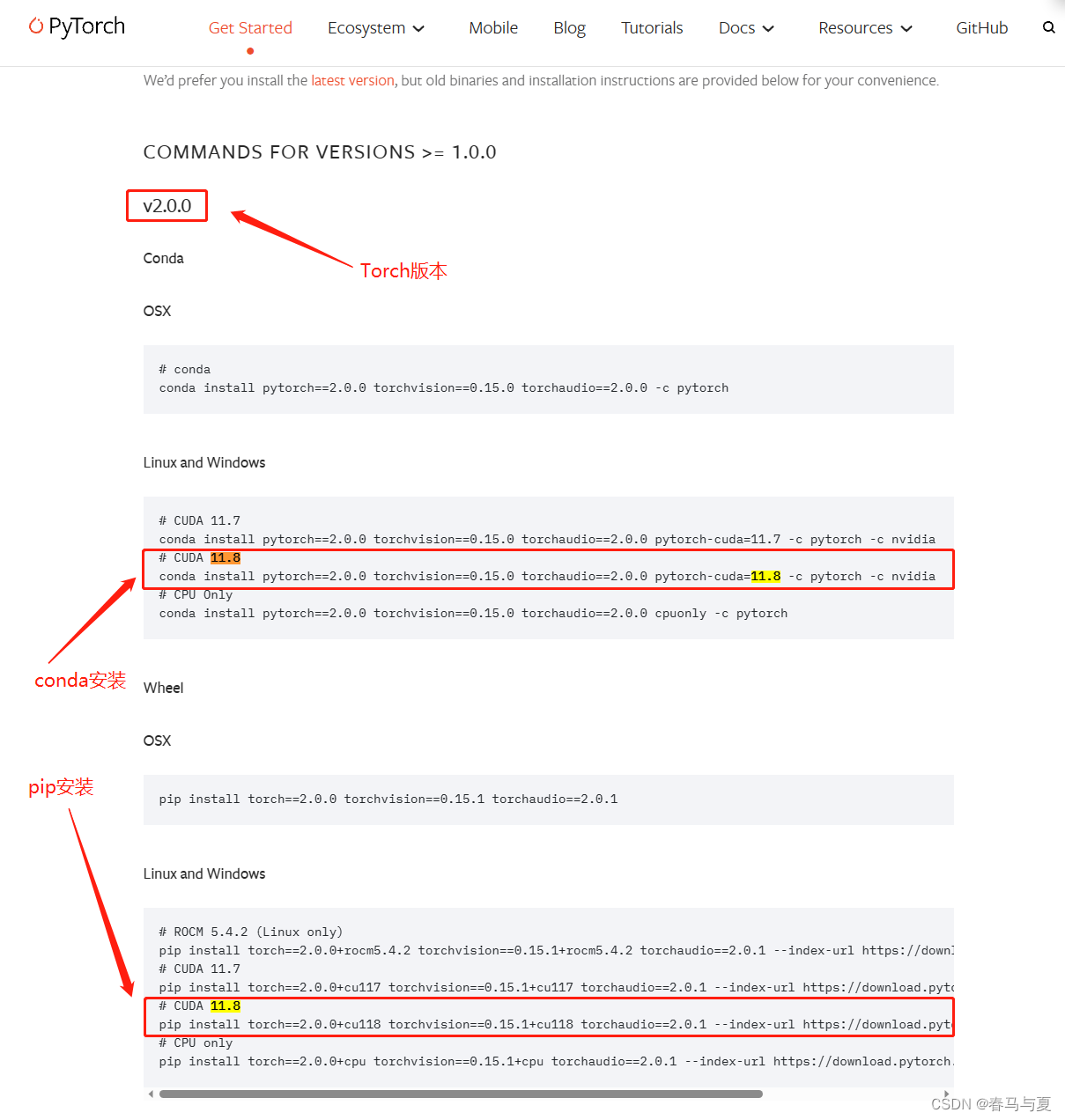 官网安装PyTorch语句在这,一定要看好自己需要哪个torch版本、cuda版本
官网安装PyTorch语句在这,一定要看好自己需要哪个torch版本、cuda版本
conda activate yolov8
# -c pytorch可以去掉,即不指定pytorch官方channel下载,国内快一点
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c nvidia
如果有CondaHTTPError: HTTP 000 CONNECTION FAILED for url ...的错误, 修改conda配置文件,把下面内容全部替换掉原来的,重启命令行,进环境再install一下
配置文件默认地址C:\Users\{用户名}\.condarc
show_channel_urls: true
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
ssl_verify: false
channels:镜像源
ssl_verify:关闭SSL安全认证
show_channel_urls:从channel安装某个包时,显示channel的url
验证torch安装
官方验证,进cmd,进python环境,输入下面三行,看打印结果
import torch
x = torch.rand(5, 3)
print(x)
# 样例输出
tensor([[0.3380, 0.3845, 0.3217],
[0.8337, 0.9050, 0.2650],
[0.2979, 0.7141, 0.9069],
[0.1449, 0.1132, 0.1375],
[0.4675, 0.3947, 0.1426]])

七、环境测试
我使用的是IDEA,也可以用PyCharm
验证cuDNN
先不新建项目,打开之前拉取下拉的yolo8 GitHub项目,配下上面新建的conda环境yolov8,查看虚拟环境放哪了可以用conda info -e


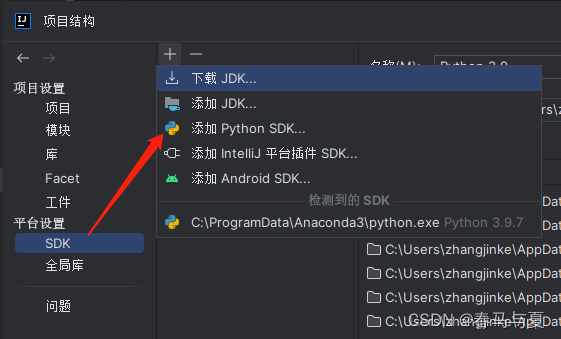
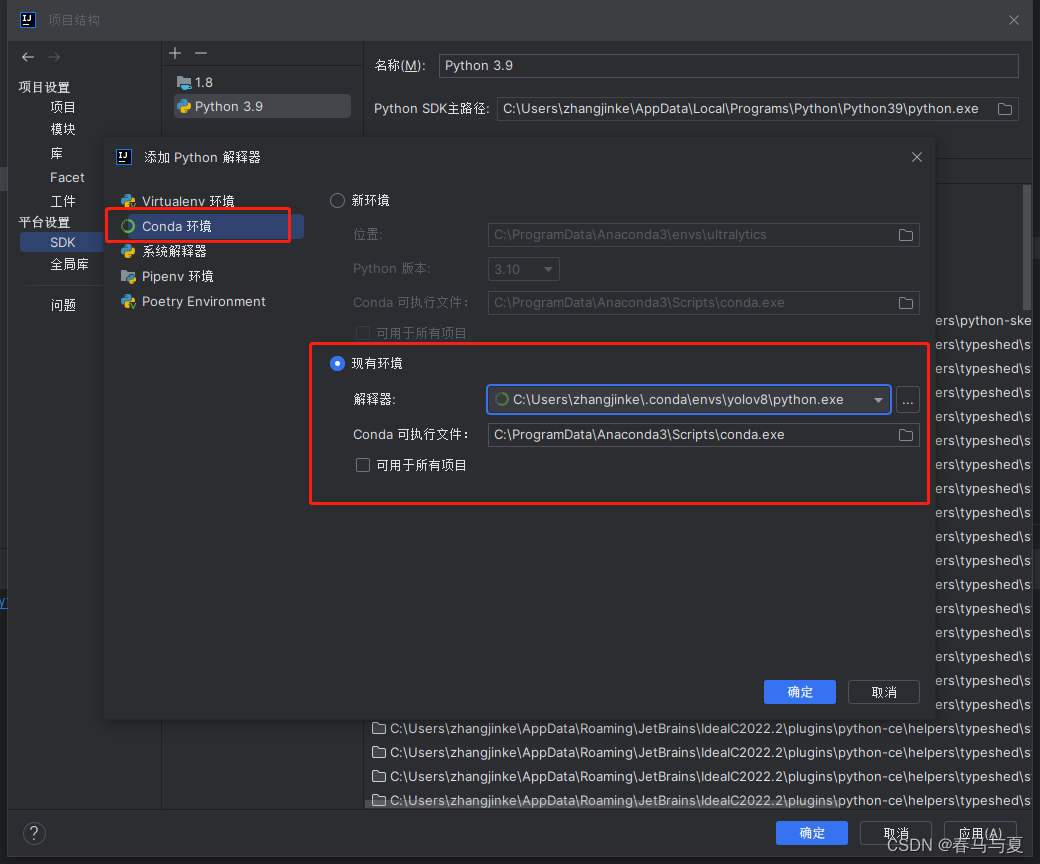
打开后新建一个自定义文件夹,new一个py文件,贴上以下代码,运行查看结果

import torch
# 查看pytorch版本
print(f'pytorch版本: {torch.version.__version__}')
# 查看显卡GPU是否可用
print(f'GPU是否可用: {torch.cuda.is_available()}')
# 查看GPU可用数
print(f'GPU可用数: {torch.cuda.device_count()}')
# 查看CUDA版本
print(f'CUDA版本: {torch.version.cuda}')
# 查看CUDA-cuDNN版本
print(f'cuDNN版本: {torch.backends.cudnn.version()}')
quit()
如果你看到GPU可用为True,那cuDNN就是安装成功了,此时环境就是GPU版本的了

验证YOLOv8
打开yolo8项目找到requirements.txt安装插件,或者使用终端在项目内pip安装pip install -r requirements.txt

这时就可能用到这个官网中文README。使用方式有两种,命令行(CLI) 和 Python代码
CLI
在项目里有个图片ultralytics/assets/bus.jpg,可以使用yolov8n.pt模型对这个图片做一个简单的推理
yolo predict model=yolov8n.pt source='可以填你图片在你电脑的绝对路径'

推理结果保存在了runs\detect\predict,我在C:\Users\zhangjinke>执行的这个命令,所以文件在C:\Users\zhangjinke\runs\detect\predict

Python Code
from ultralytics import YOLO
# 加载模型
# model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
# model.train(data="coco128.yaml", epochs=3) # 训练模型
metrics = model.val() # 在验证集上评估模型性能
results = model(source='ultralytics/assets/bus.jpg') # 对图像进行预测
results.print() # 打印结果
# success = model.export(format="onnx") # 将模型导出为 ONNX 格式
第一次运行此代码需要下载coco的标签包,等待,结果例子如下,没有报错环境就部署成功了
Speed: 0.2ms preprocess, 3.1ms inference, 0.0ms loss, 0.7ms postprocess per image
Results saved to runs\detect\val7
image 1/1 D:\GitProjects\ultralytics\ultralytics\assets\bus.jpg: 640x480 4 persons, 1 bus, 23.9ms
Speed: 2.0ms preprocess, 23.9ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 480)
Ultralytics YOLOv8.0.138 Python-3.9.13 torch-1.13.0+cu116 CPU (Intel Core(TM) i9-9900K 3.60GHz)
PyTorch: starting from runs\detect\train11\weights\best.pt with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 84, 8400) (6.2 MB)
ONNX: starting export with onnx 1.14.0 opset 16...
ONNX: export success 0.7s, saved as runs\detect\train11\weights\best.onnx (12.2 MB)
Export complete (2.2s)
Results saved to D:\GitProjects\ultralytics\runs\runs\detect\train11\weights
Predict: yolo predict task=detect model=runs\detect\train11\weights\best.onnx imgsz=640
Validate: yolo val task=detect model=runs\detect\train11\weights\best.onnx imgsz=640 data=D:\GitProjects\ultralytics\ultralytics\cfg\datasets\coco128.yaml
Visualize: https://netron.app
进程已结束,退出代码0
八、可能出现的问题
- 乱码提示需要运行
pip install --no-cache "py-cpuinfo",在这可能需要先更新pip,按照提示即可

- xxx
九、附yolo命令参数解释
task
- detect:指定任务为目标检测,即通过模型识别图像或视频中的物体,然后在图像上标注出它们的位置。
- classify:指定任务为图像分类,即通过模型将图像分为不同的类别。
- segment:指定任务为图像分割,即将图像分割为不同的区域,并为每个区域分配一个标签。
mode
- train:指定模式为训练模式,用于训练模型。
- predict:指定任务为预测,即使用训练好的模型对新的图像进行预测。
- val:指定验证模式,用于评估模型在验证集上的性能。
- export:指定任务为导出模型,即将训练好的模型导出到其他格式,如ONNX。
model
- yolov8n.pt:指定模型的文件名或路径,其中yolov8n.pt表示模型的文件名。
- yolov8n-cls.yaml:指定用于图像分类的模型配置文件的文件名或路径。
- yolov8n-seg.yaml:指定用于图像分割的模型配置文件的文件名或路径。
| Key | Value | Description |
|---|---|---|
| data | None | 数据文件路径,例如 coco128.yaml |
| imgsz | 640 | 图像尺寸,可以是一个标量或 (h, w) 的列表,例如 (640, 480) |
| batch | 16 | 每个批次的图像数(-1 表示自动批处理) |
| save_json | FALSE | 是否将结果保存为 JSON 文件 |
| save_hybrid | FALSE | 是否保存标签的混合版本(标签 + 额外的预测结果) |
| conf | 0.001 | 目标置信度阈值,用于检测 |
| iou | 0.6 | NMS(非最大抑制)的交并比阈值 |
| max_det | 300 | 每张图像的最大检测数 |
| half | TRUE | 是否使用半精度(FP16) |
| device | None | 运行模型的设备,例如 cuda device=0/1/2/3 或 device=cpu |
| dnn | FALSE | 是否使用 OpenCV DNN 进行 ONNX 推断 |
| plots | FALSE | 训练过程中是否显示图表 |
| rect | FALSE | 针对最小填充的每个批次进行矩形验证 |
| split | val | 用于验证的数据集拆分,例如 ‘val’、‘test’ 或 ‘train’ |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)