机器学习技法(林轩田)学习笔记:Lecture 3 & Lecture 4
Lecture 3:Kernel Support Vector Machine
Kernel Trick
回顾Lecture 2中SVM的拉格朗日对偶问题:
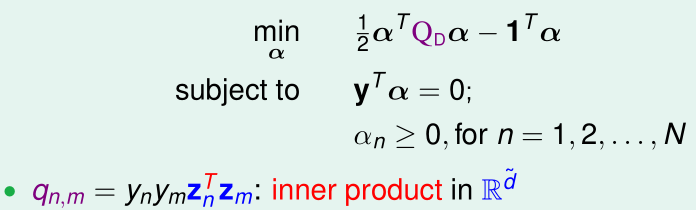
对偶问题中,有n个变量需要求解,n个不等式约束条件和1个等式约束条件
整个问题只有在计算\(q_{n,m}\)时与\(\tilde d\)有联系:计算\(z_n,z_m\)的内积的时间复杂度是\(O(\tilde d)\)的,另外,在求解该对偶问题前,\(z_i\)都需要通过特征变换\(z_i=\Phi(x_i)\)来得到
为了彻底摆脱对\(\tilde d\)的联系,就要用到核技巧(kernel trick)了
首先看一个例子:特征变换\(\Phi(x)\)把原始特征\(x\)映射到二阶的\(z\)

(为了方便表示,把诸如x1x2和x2x1这样的两项都拆开写了)
\(x\)是d维的,\(z=\Phi_2(x)\)是\(d^2+1\)维的,直接计算两个\(z_1,z_2\)的内积,时间复杂度是\(O(d^2)\)
我们把\(\Phi_2(x)^T\Phi_2(x')\)展开:
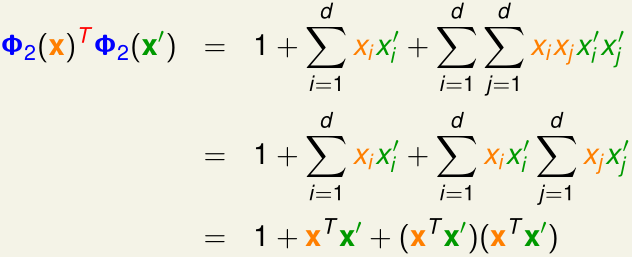
如果我们跳过计算\(\Phi_2(x),\Phi_2(x')\),以及\(\Phi_2(x)^T\Phi_2(x')\),而是直接计算最后的\(x^Tx'\),时间复杂度就降到了\(O(d)\)
我们定义特征变换\(\Phi_2\)对应的核函数
使用简单的核函数代替内积,就可以让这一过程的时间复杂度与\(\tilde d\)无关了

类似地,我们把b和\(g(x)\)中的w表示成\(\sum_{n=1}^N\alpha_ny_nz_n\),然后用核函数代替其中\(z_n,z_s\)的内积,如上图。这样就能让计算内积的过程与\(\Phi,z,\tilde d\)无关了

使用核技巧后,之前的SVM算法流程如上图,其中:
- (1)中获得每个\(q_{n,m},p\)的时间复杂度就变成了$O(n^2)\cdot $(计算核函数K的时间复杂度)
- (2)是一个n个变量、n+1个约束条件的特殊二次规划问题
- (3)和(4)的时间复杂度都是O(支持向量个数)·(计算核函数K的时间复杂度)
Polynomial Kernel
一般的Q阶多项式核函数形式如下:

其中,\(\zeta,\gamma\)是参数
加入多项式核函数的SVM被称为多项式核SVM
线性核是多项式核的特殊情形,即Q=1,\(\zeta=0,\gamma=1\),此时就相当于是原始特征\(x,x'\)的内积:
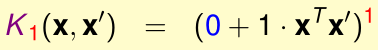
在实践中,我们应该尽量先尝试比较简单的假设函数,所以要优先尝试用线性核函数
Gaussian Kernel
我们来看这个特殊的核函数:
首先看x为标量时的情况:

我们可以把这个核函数看作是对两个\(\Phi(x),\Phi(x')\)的内积,特征变换\(\Phi(x)\)将标量x映射为无限维的向量
高斯核SVM的假设函数为:
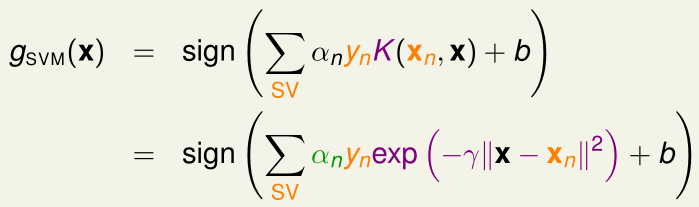
其中,\(\sum_{SV}\alpha_n\gamma_n\exp(\cdots)\)可以视为是若干个以\(x_n\)(\(\alpha_n>0\)的支持向量)为中心、方差相同的高斯分布的线性组合
总结:带核函数的SVM的大间隔保证了泛化能力(\(E_{in}\approx E_{out}\));而核函数则让原始特征映射到高维(甚至无限维)空间中,使得决策边界变得复杂,\(E_{in}\)很小

选取合适的高斯核参数\(\gamma\)十分重要,\(\gamma\)越大,每个高斯分布就越"尖",如上图所示,\(\gamma\)太大会引起过拟合
Comparison of Kernels
本节课最后比较了各种核函数的优缺点
线性核
优点:
- 简单,在实践中应该首先尝试简单的线性核函数
- 运算速度快
- 最后可以很容易得到有实际意义的\(w\)
缺点:
- 过于简单
多项式核
优点:
- 可以表示出比线性核更复杂的边界
- 通过阶数Q的大小,可以控制决策边界的复杂程度
缺点:
- Q太大时,\(|\zeta+\gamma x^Tx'|<1\)时K趋于0,\(|\zeta+\gamma x^Tx'|>1\)时K趋于正无穷
- 参数更多,有三个参数\(\zeta,\gamma,Q\),不方便选取
高斯核
优点:
- 把原始特征映射到无限维向量,可以表示出比线性核、多项式核更复杂的边界
- K始终在\([0,1]\)内,这一点比多项式核好很多
- 只有一个参数\(\gamma\)
缺点:
- 无法得到\(w\)
- 比线性核更慢
- \(\gamma\)太大时容易过拟合
另外补充一点,核函数可以视为对两个向量的相似度的度量
K是有效的核函数的充要条件是,对于任意n个向量\(x_1,\cdots,x_n\),矩阵\(K\)(其中\(k_{ij}=K(x_i,x_j)\))是半正定的
Lecture 4:Soft-Margin Support Vector Machine
Motivation and Primal Problem
之前介绍的SVM是hard-margin的,即不允许任何训练样本被错误分类,这样的SVM只适用于训练集可分的情况。
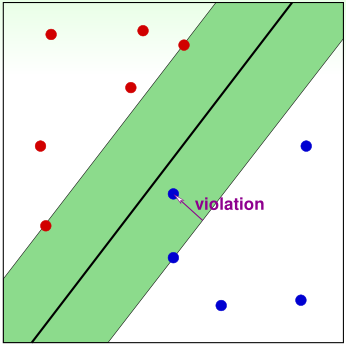
soft-margin的motivation是允许少量的训练样本被错误分类。我们用松弛变量\(\xi_n\)表示第n个样本被错误分类的程度(上图中紫色的violation),soft-margin SVM的优化目标为:
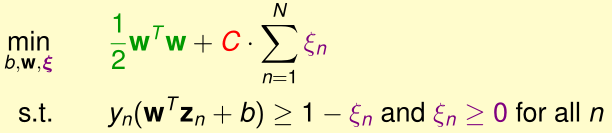
其中:
- \(\xi_n=0\)表示样本点没有越过margin(\(y_n(w^tz_n+b)\geq 1\))
- \(\xi_n>0\)时,\(\xi_n\)越大,表明越过margin的violation越大
- \(C\)是惩罚因子,用于平衡边界最大化与violation的程度,C越大,表明越希望所有训练样本的violation越小
该问题有\(\tilde d+n+1\)个变量(\(w_i,\xi_n,b\)),2n个不等式约束条件
Dual Problem
对应于这个优化目标的拉格朗日函数是:
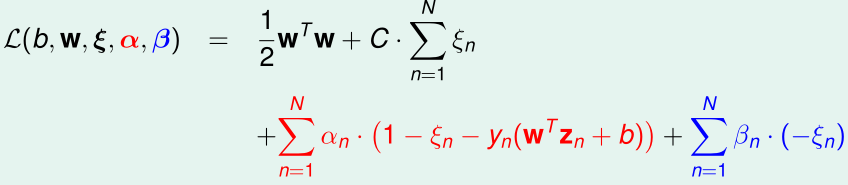
其中,\(\alpha_n,\beta_n\)是拉格朗日乘子
拉格朗日原始问题为:
拉格朗日对偶问题为:
为了让内层的min(...)取最小值,令\(\frac{\partial \mathcal L}{\partial \xi_n}=0\),得:
从而有\(\beta_n=C-\alpha_n\geq 0\),又\(\alpha_n\geq 0\),那么约束条件可以概括为\(0\leq \alpha_n \leq C\ \ \cdots\cdots (2)\)
回顾拉格朗日对偶问题:
将(1)式、约束条件(2)代入可得
为了让内层min(...)取最小值,我们令(...)对w,b求导:
从而可得\(w=\sum_{n=1}^N\alpha_ny_nz_n\),代入(3)
对偶问题可以表示为:
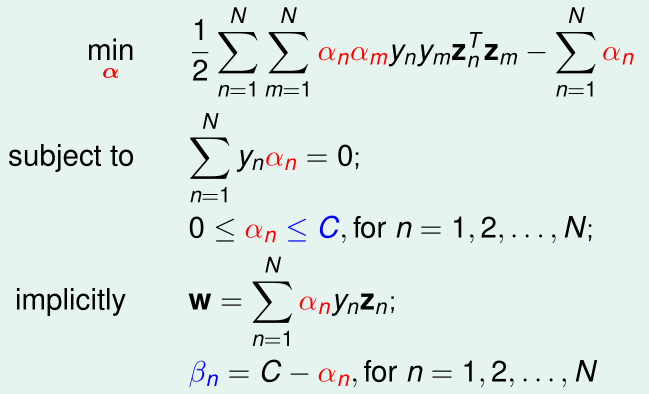
可以发现,soft-margin的对偶问题与hard-margin的对偶问题相比,就是约束条件里\(\alpha_n\)多了上界C
Messages behind Soft-Margin SVM
我们也可以对soft-margin SVM加入核函数,和hard-margin SVM的情形类似,就是把\(z_n,z_m\)的内积替换成\(K(x_n,x_m)\)

现在只剩下问题:b怎么求?
在soft-margin SVM对偶问题与原始问题最优解等价的KKT条件里的互补松弛条件,可得:
将(1)代入可得:
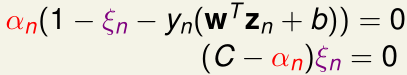
- 当\(\alpha_s>0\)时,第一个互补松弛条件表明\(1-\xi_s-y_s(w^Tz_s+b)=0\),\(b=y_s-y_s\xi_s-w^Tz_s\),我们称样本点s是支持向量(SV)
- 当\(\alpha_s<C\)时,第二个互补松弛条件表明\(\xi_s=0\),即样本点s在margin的边缘或外侧,我们称样本点s是自由的(free)
因此我们可以将所有样本点按\(\alpha_n\)的取值分类:
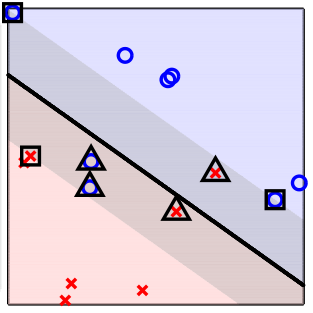
- \(\alpha_n=0\),表明样本点不是支持向量,不在margin内
- \(0<\alpha_n<C\),表明样本点是自由支持向量(图中方形),在margin边缘,可以用自由支持向量推出b的值
- \(\alpha_n=C\),表明样本点是支持向量,但越过了对应的margin边缘(图中三角形),其\(\xi_n\)表明越过对应margin边缘的程度(violation)
Model Selection
高斯核的soft-margin SVM有两个参数\(\gamma,C\),选取参数的过程就是模型选择问题,需要用交叉验证,而\(E_{CV}(\gamma,C)\)不是光滑的函数,只能枚举一系列的离散的\(\gamma,C\),从中选取\(E_{CV}\)最小的
如果我们采用Leave-One-Out cross validation选取参数的话,有一个有趣的性质:对于某个参数为\(\gamma,C\)的SVM而言,其\(E_{loocv}\leq\) (用整个训练集训练该SVM,得到的支持向量个数)/(训练样本总数N)
证明:
假设现在用\((x_n,y_n)\)作验证样本,其他N-1个样本用于训练
-
(1)若用整个训练集训练出的\(\alpha_n=0\),表明\((x_n,y_n)\)不是支持向量,因此去掉它以后训练的SVM和不去掉它训练出的SVM是一样的,而且因为\((x_n,y_n)\)不是支持向量,它是分类正确的点,所以\((x_n,y_n)\)作验证样本时验证误差为0
-
(2)若用整个训练集训练出的\(\alpha_n>0\),则用\((x_n,y_n)\)作验证样本时验证误差<=1
综上可得\(E_{loocv}\leq \frac{SV}{N}\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号