
将含两列的csv文件生成二维矩阵
gen_diea=pd.read_csv('../data/ddg_data/diea-gene.csv', header=None, names=['diease','gene'])
#生成关联矩阵
df=pd.get_dummies(gen_diea.gene).groupby(gen_diea.diease).apply(max)
print(df)
df.to_csv('diea_gene.csv')
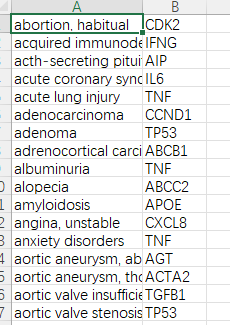
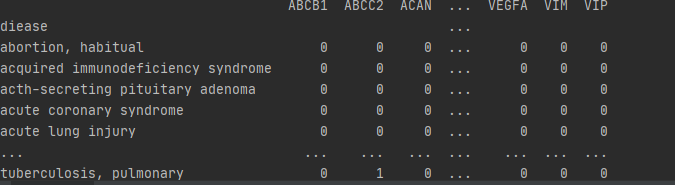
gen_diea=pd.read_csv('../data/ddg_data/diea-gene.csv', header=None, names=['diease','gene'])
#生成关联矩阵
df=pd.get_dummies(gen_diea.gene).groupby(gen_diea.diease).apply(max)
print(df)
df.to_csv('diea_gene.csv')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号