

OO博客作业-《JML之卷》
OO第三单元小结
一.JML语言理论基础以及应用工具链情况梳理
一句话来说,JML就是用于对JAVA程序设计逻辑的预先约定的一种语言,以便正确严格高效地完成程序以及展开测试,这在不能容忍细微错误的工程领域如航空航天领域有广泛应用。
1.1 JML语言理论基础
本单元我们学习了一些语言理论基础,梳理如下:
1.requires 该子句定义了方法的前置条件
2.assignable子句,列出方法修改的类成员属性。\nothing则表示方法不改变任何成员属性,是一个pure的方法
3.ensure子句,定义了后置条件,如返回的结果或者该方法运行后的逻辑结果等等
4.\result表达式,表示方法返回的逻辑上的正确的结果
5.\old(expr),表示执行相应方法前表达式expr的取值
6.public normal_behavior表示方法的正常功能
7.public exceptional_behavior表示方法的异常功能
8.signals 定义了抛出某异常以及抛出异常的条件语句expr,当expr为true时抛出异常
9.signals_only,强调满足前置条件时候抛出相应异常
10.invariant,定义了一个方法的不变的属性
以及一些量化表达式,集合逻辑表达式等等,在JML手册中有详细介绍,在此就不一一梳理了。
主要是要理解JML对于JAVA程序设计与实现的分离的作用以及其对于整个程序的架构设计以及正确性保证上的重要性。我个人的体会是,在我们的作业中读懂JML其实该次作业就完成了一半了。
1.2 工具链简介
与规格化设计相关的工具主要有:OpenJML,JUnit,JUnitNG等等,Openjml主要帮助我们检查规格化语言JML的语法以及基本逻辑正确性,Junit以及JunitUG则是对JML规格进行测试,前者主要用于单元测试以及一定的自动化测试,后者则主要测试一些边界情况。
二.JMLUnit部署以及其使用
根据zwc大佬在讨论区发的一篇博客上的步骤部署好JMLUnit后,编写测试类:
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
public class MyPathTest {
private MyPath path1, path2, path3;
@Before
public void before() {
path1 = new MyPath(1, 2, 3, 4);
path2 = new MyPath(1, 2, 3, 4);
path3 = new MyPath(1, 2, 3, 4, 5);
}
@Test
public void testEquals() throws Exception {
Assert.assertTrue(path1.equals(path1));
Assert.assertTrue(path1.equals(path2));
Assert.assertFalse(path1.equals(path3));
Assert.assertTrue(path2.equals(path1));
Assert.assertTrue(path2.equals(path2));
Assert.assertFalse(path2.equals(path3));
Assert.assertFalse(path3.equals(path1));
Assert.assertFalse(path3.equals(path2));
Assert.assertTrue(path3.equals(path3));
}
}
运行后,结果如图,与预期结果一致:
三.作业架构设计梳理
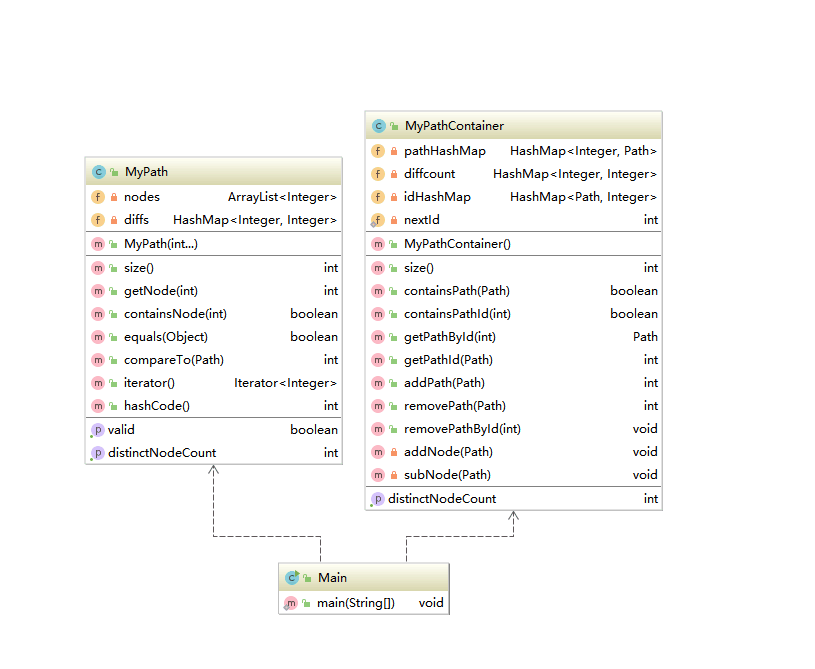
第一次:
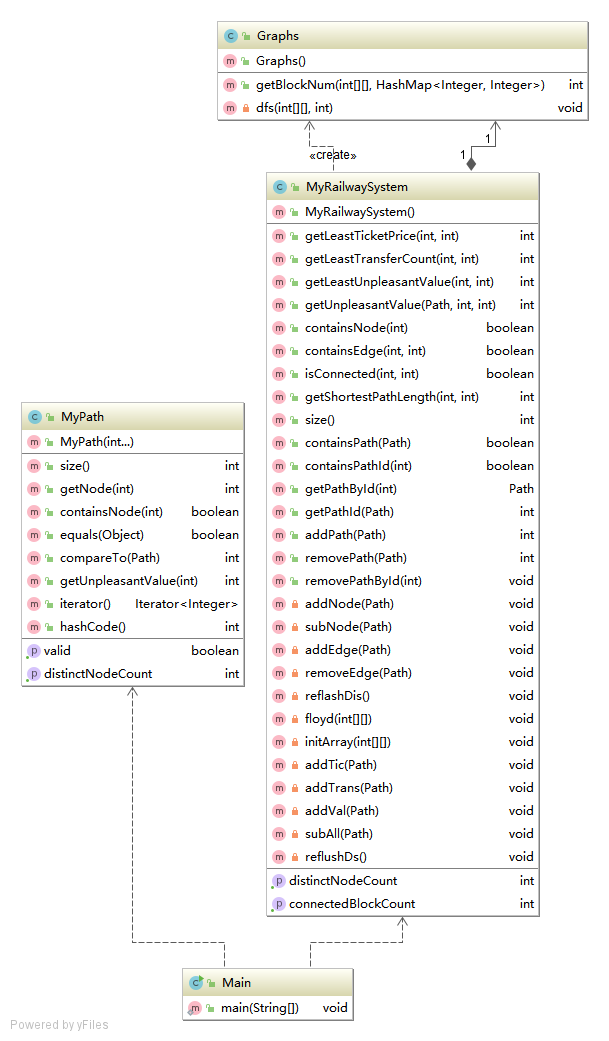
第二次

第三次
第三次作业数据结构层如图:
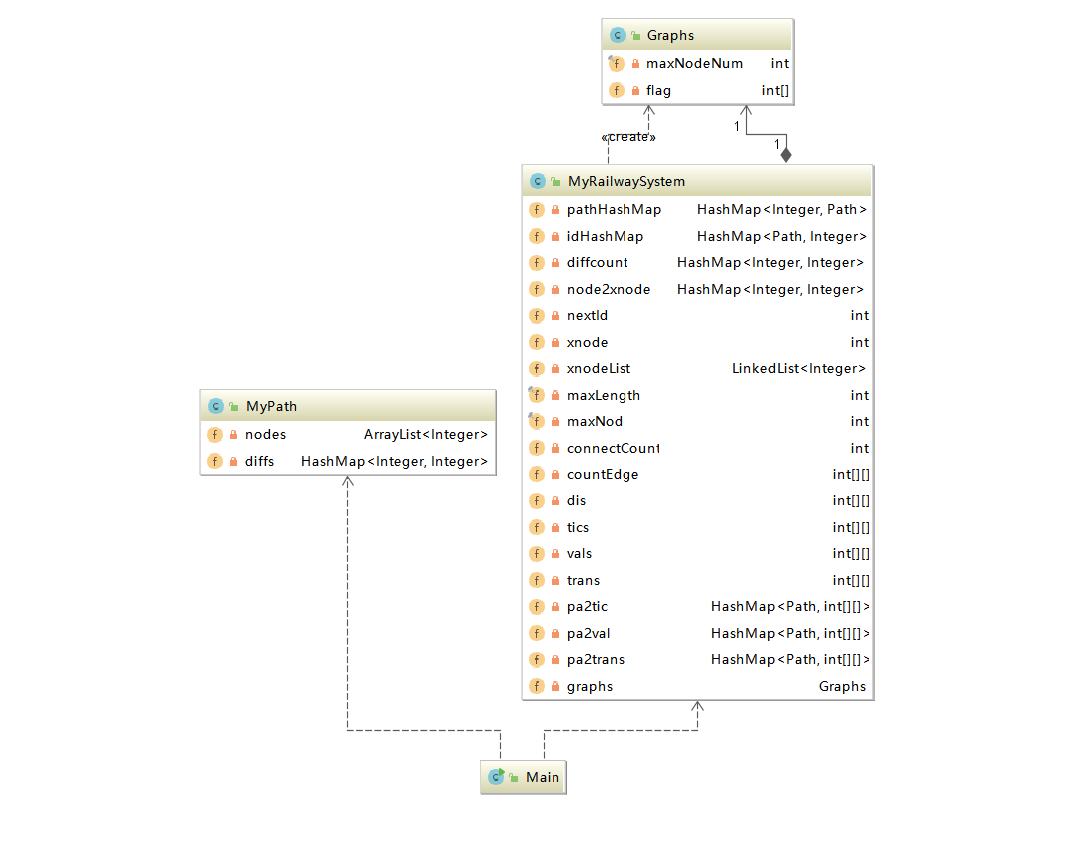
总地来说,三次作业我都运用了Floyd计算最短路以及第三次作业用dfs计算连通块。三次作业架构类似,主要还是在"MyPathContainer"上不断增加数据结构管理相关数据以及增加新的计算方法,实际上,将计算逻辑以及数据结构包装在另外的单独的类里面,我觉得会是更好的设计方式。
这三次作业关键在于数据结构的选择以及时间复杂度的控制,首先将节点编号做一个1-122的映射(Hashmap<real_Id,x_Id>),并采用节点回收机制,这样就可以进行静态数据的玩法了。实际上,无论是两点之间的最短路,还是最少换乘,最低票价亦或最低不满意度,都可以归结为最短路问题的求解,只不过后面三个需要有其他数据结构来支撑,以便构建起正确的边权。当构建好所有的图结构后,一个floyd算法,就可以解决一切。每次加路径以及去除路径的时候,计算好对应的数据,查询的时候就是O(1).
四.bug与修复情况
这次作业由于选择了比较好的数据结构以及求解相关查询的方法,所以本次我自己的作业公测与互测都没有bug。但是在完成作业的时候,仍然在本地测试的时候发现一些bug:
1.在第二次作业的时候,由于我在去边的时候,先删除点再去边,这样的逻辑错误会导致边集数组的访问会出现访问不存在的两点的边。
2.在第三次作业的时候,我采用最原始的dfs来进行连通块的查询,当时网上给出的算法是n个节点,而我定义的MAXNODE为122(大于等于120均可),这样当图中不同节点比较少的时候,我得到的答案是靠近120,当时我懵了好久,是网上写错了吗?思考下发现,由于我们已经加入的path的不同节点很可能是少于120的,所以每次从编号0-122遍历dfs的时候,要先查询该编号是否在映射表中(Hashmap<real_Id,x_Id>),如果存在并且节点没有被访问过才把答案加1,修改之后我连通块的计算就算是完成了。
3.在第三次作业的时候,我会出现查询最少票价的时候返回值是MaxLength=666666666,查看之后,是在增加路径的时候,把对票价数组的对称赋值写成了对相同节点的赋值,导致神必错误。
关于互测:
对拍器是很容易的,主要还是在于数据生成器的强弱。
三次作业我发现了也仅发现了一次别人的bug,就是最大值估计错误,当加入的每条path都不在已有path中存在,并且最大节点数为120的时候,会出现越界错误,这个bug要修起来可能不仅仅是把数组开大这么简单,要牺牲大部分性能或者甚至重构。
五.对规格撰写的心得体会
规格撰写对于像我这样的小白来说,上手难度其实不大,理解基本语法和关键语句,看着已有的例子,其实要写一份较为简单的规格描述比较容易。但是想要完整的针对一次作业,从零开始设计架构,编写规格,完成程序,我觉得还需要更多的学习。
我个人认为,由于Openjml环境比较苛刻,所以想要写出一份语法完全正确的规格描述其实很困难或者说是要花的时间远远比完成程序多。所以,规格撰写在初级阶段,关键要在于逻辑的严密性和正确性,这是保证完整规格化设计后的程序正确性的重要前提。这三次作业的体验明显好于第1、2单元,原因在于每次作业新增需求都不需要重构,只需要在已有的程序上加入一些新的用于管理数据的数据结构和相应的方法罢了,第三单元的每次作业的可拓展性都远远好于之前两个单元我完成的每次作业。可以看见,架构设计对JAVA程序可拓展性和可维护性的重要性。
最后,摆个队形,祝愿OO越来越好,可以让更多的同学和学弟学妹学到更多更多的知识,提升更多更多的能力。
