

python基础 14.字符串
字符串
在python中字符串是基本数据类型,是一个不可变的字符序列
字符串的驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
驻留机制的几种情况(交互模式)
字符串的长度为0或1时
符合标识符的字符串
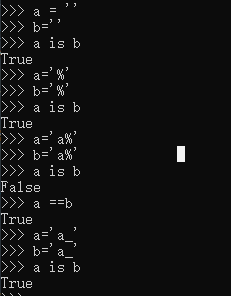
字符串只在编译时进行驻留,而非运行时
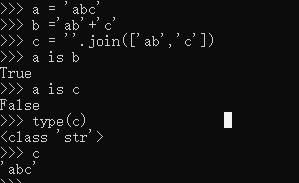
如上图,a、b的值是在程序运行前产生的,而c是在程序运行中通过join方法产生的
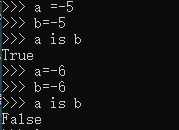
[-5,256]之间的整数数字
sys中的intern方法强制2个字符串指向同一个对象
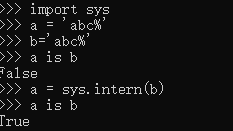
#注:intern函数只能用在str类型,不能用在int等类型
PyCharm对字符串进行了优化处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # # ----------字符串----------a = 'abc'b = "abc"print(a, id(a))print(a, id(b))a = ''b = ''print(a is b)a = '%'b = '%'print(a is b)a = 'a%'b = 'a%'print(a is b)print(a == b)a = 'a_'b = 'a_'print(a is b) |
驻留机制的优缺点
当需要值相同的字符串是,可以直接从字符串池中拿出来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的
在需要进行字符串拼接时建议使用str类型的join方法,而非+,因为join()方法事先计算出所有字符串中的长度,然后在拷贝,只new一次对象,比+效率高
字符串的常用操作
字符串查询操作
|
功能
|
方法名称
|
作用
|
|
查询方法
|
index()
|
查找子串substr第一次出现的位置,如果查找的子串不存在时,抛出ValueError
|
|
rindex()
|
查找子串substr最后一次出现的位置,如果查找的子串不存在时,抛出ValueError
|
|
|
find()
|
查找子串substr第一次出现的位置,如果查找的子串不存在时,返回-1
|
|
|
rfind()
|
查找子串substr最后一次出现的位置,如果查找的子串不存在时,返回-1
|
1 2 3 4 5 6 7 8 9 10 11 12 | # 字符串查询操作s = 'abcabca'print(s.index('c'))print(s.rindex('c'))print(s.find('c'))print(s.rfind('c'))# print(s.index('cb'))# Traceback (most recent call last):# File "D:\PycharmProjects\pystu\demo.py", line 788, in <module># print(s.index('cb'))# ValueError: substring not foundprint(s.find('cb')) # -1 |
字符串大小写转换操作
|
功能
|
方法名称
|
作用
|
|
大小写转换
|
upper()
|
把字符串中所有字符都转成大写字符
|
|
lower()
|
把字符串中所有字符都转成大写字符
|
|
|
swapcase()
|
把字符串中所有大写字符都转成小写字符,所有小写字符转成大写字符
|
|
|
capitalize()
|
把第一个字符转成大写,其余字符转换成小写
|
|
|
title()
|
把每个单词的首字符转成大写,其余为小写
|
1 2 3 4 5 6 7 8 | # 字符串大小写转换操作a = 'abc ABC'print(a, id(a))print(a.upper(), id(a.upper())) # 转换之后会产生一个新的字符串对象print(a.lower())print(a.swapcase())print(a.capitalize())print(a.title()) |
字符串内容对齐操作
|
功能
|
方法名称
|
作用
|
|
字符串对齐
|
center()
|
居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串
|
|
ljust()
|
左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串
|
|
|
rjust()
|
右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串
|
|
|
zfill()
|
右对齐,左边用0填充,该方法只接受一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身
|
1 2 3 4 5 6 7 8 9 | # 字符串内容对齐操作a = 'python'print(a.center(20, '*'))print(a.ljust(20, '*'))print(a.rjust(0, '*'))print(a.rjust(20, '*'))print(a.rjust(20))print(a.zfill(10))print('-111'.zfill(6)) |
字符串劈分操作
|
功能
|
方法名称
|
作用
|
|
字符串的劈分
|
split()
|
从字符串的左边开始劈分,默认劈分字符时空格字符串,返回的值都是一个列表
|
|
以通过参数sep指定劈分字符串式的劈分符
|
||
|
通过参数maxsplit指定劈分字符串的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分
|
||
|
rsplit()
|
从字符串的右边开始劈分,默认劈分字符时空格字符串,返回的值都是一个列表
|
|
|
以通过参数sep指定劈分字符串式的劈分符
|
||
|
通过参数maxsplit指定劈分字符串的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分
|
1 2 3 4 5 6 7 8 9 10 11 12 | # 字符串分割操作s = 'hello, my name is XXX'a = s.split() # 默认分割符是空格b = s.rsplit(maxsplit=1) # maxsplit是最大分割数,即最多分n次c = s.split('m') #d = s.split('z') # 字符串中没有分割符,不分割# d = s.split('')# Traceback (most recent call last):# File "D:\PycharmProjects\pystu\demo.py", line 821, in <module># d = s.split('')# ValueError: empty separatorprint(a, b, c, d) |
字符串判断的相关方法
|
功能
|
方法名称
|
作用
|
|
判断字符串的方法
|
isidentifier()
|
判断指定的字符串是不是合法的标识符
|
|
isspace()
|
判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符)
|
|
|
isalpha()
|
判断指定的字符串是否全部由字母组成
|
|
|
isdecimal()
|
判断指定的字符串是否全部由十进制的数字组成
|
|
|
isnumeric()
|
判断指定的字符串是否全部由数字组成
|
|
|
isalnum()
|
判断指定的字符串是否全部由字母和数字组成
|
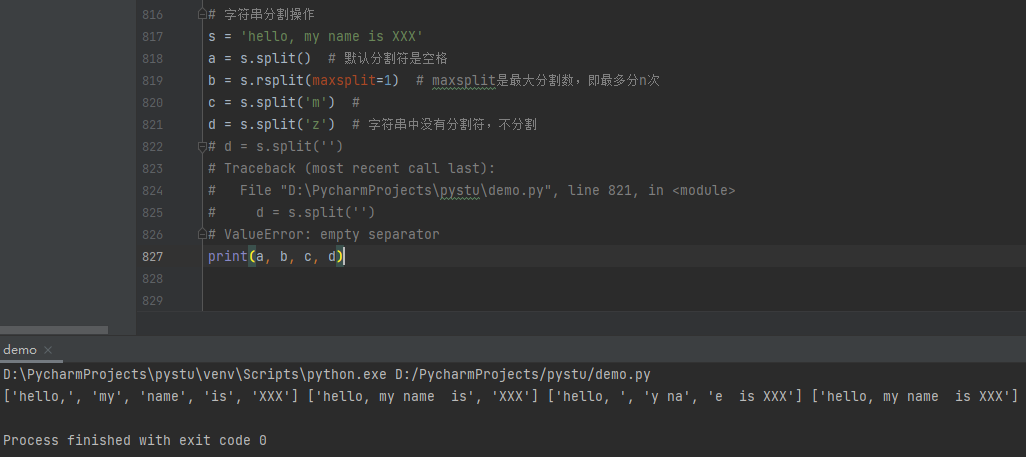
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 判断字符串操作的方法a = 'hello,my mane is XXX'print('1.', a.isidentifier())print('2.', '\''.isidentifier())print('3.', 'a'.isidentifier())print('4.', ' \t\n '.isspace())print('5.', 'a'.isspace())print('6.', 'abc'.isalpha())print('7.', 'a1'.isalpha())print('8.', '张三'.isalpha())print('9.', 'a1'.isdecimal())print('10.', '1234'.isdecimal())print('11.', '123456'.isnumeric())print('12.', '1.234'.isnumeric())print('13.', 'a1_'.isalnum())print('14.', 'a1'.isalnum()) |
字符串的替换与合并
|
功能
|
方法名称
|
作用
|
|
字符串替换
|
replace()
|
第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数
|
|
字符串合并
|
join()
|
将列表或元组中的字符串合并成一个字符串
|
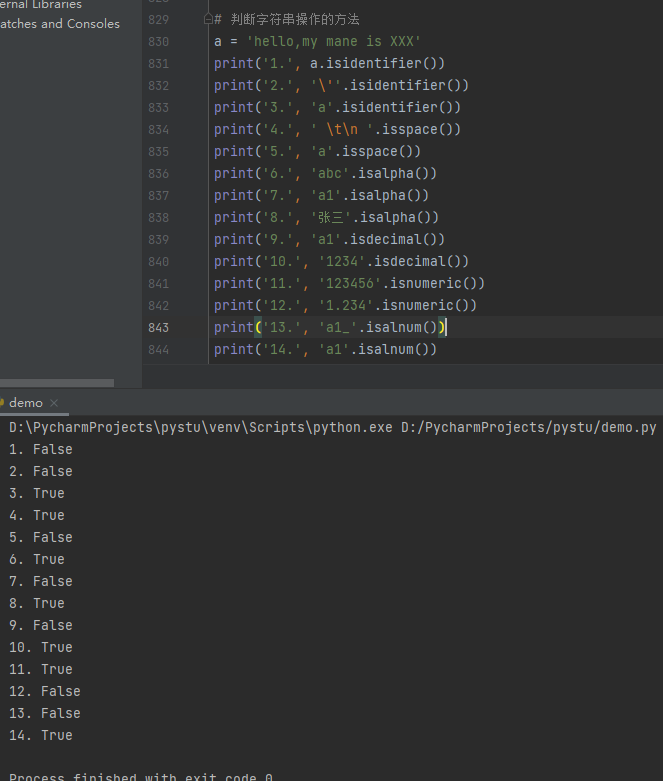
1 2 3 4 5 6 7 8 9 10 | # 字符串的替换与合并a = 'hello,my name is XXX XXX'print(a.replace('XXX', 'a', 1))b = ['a', 'bc', ' '] # 列表或字符串的内容只能是str类型的,否则会报错c = '-'d = ('a', 'b', 'c')print(c.join(b))print(c.join(d))print('!'.join('python')) |
字符串的比较
运算符:>、>=、<、<=、==、!=
比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,知道两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
比较原理:两个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的原始值,与内置函数ord对应的是内置函数chr,调用内置函数chr时指定原始值可以得到其对应的字符
==和is的区别
==比较的是值是否相等,值相等则True;is比较的是存储空间id是否相等,相等才为True
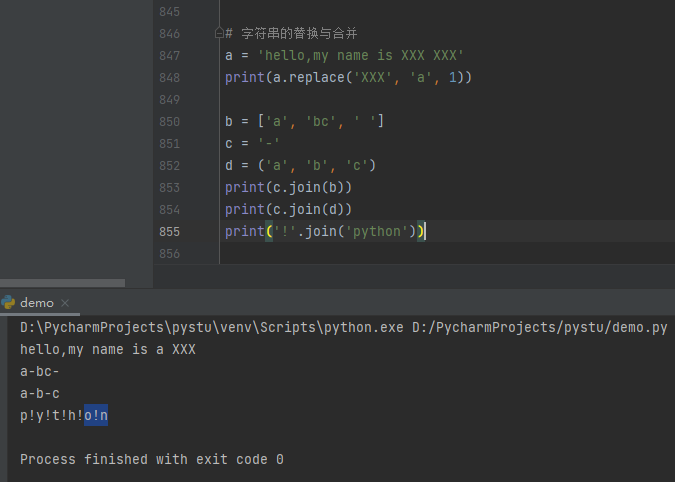
1 2 3 4 5 6 7 8 9 | # 字符串的比较print('app' >= 'app')print('apple' > 'banana')print(ord('a'), ord('b'))print(chr(97), chr(121))a = 'python'b = "python"print(a == b)print(a is b) |
字符串的切片操作
字符串是不可变类型
不具备增、删、改等操作
切片操作将产生新的对象
1 2 3 4 5 6 7 | # 字符串切片操作a = 'hello,my name is XXX'print(a, id(a))print(a[:5], id(a[:5])) # 没有指定起始位置情况下,从0开始切print(a[6:]) # 没有指定结束位置时,切到字符串的最后一个元素print(a[6:16:3])print(a[-1:-15:-1]) |
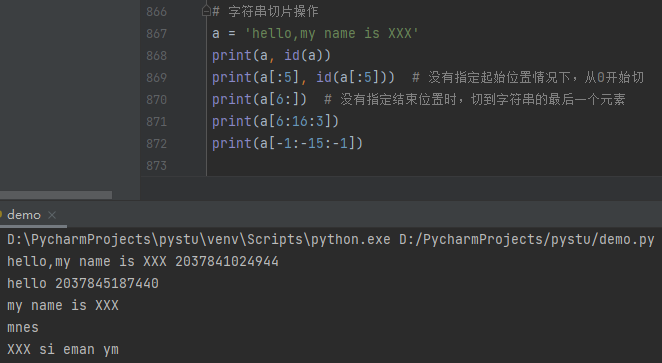
格式化字符串
为什么需要格式化字符串
在python中我们会遇到一个问题,问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
格式化字符串的两种方法
%作占位符
%s:字符串;
%i或%d:整数;
%f:浮点数
{}作占位符
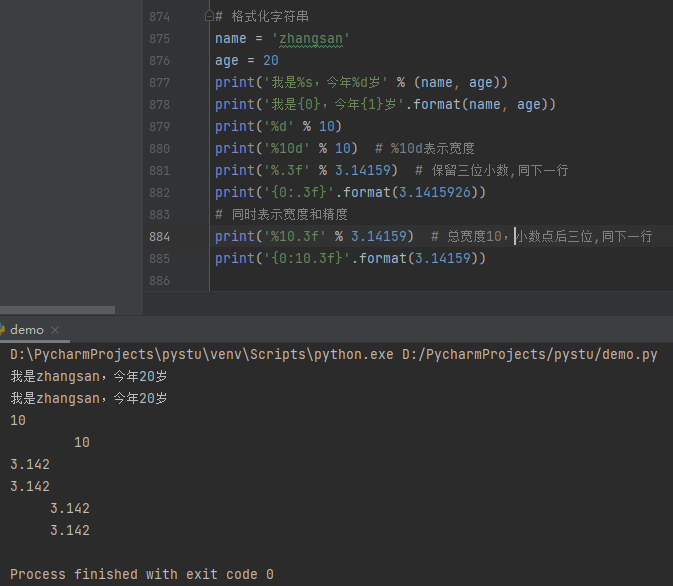
1 2 3 4 5 6 7 8 9 10 11 12 | # 格式化字符串name = 'zhangsan'age = 20print('我是%s,今年%d岁' % (name, age))print('我是{0},今年{1}岁'.format(name, age))print('%d' % 10)print('%10d' % 10) # %10d表示宽度print('%.3f' % 3.14159) # 保留三位小数,同下一行print('{0:.3f}'.format(3.1415926))# 同时表示宽度和精度print('%10.3f' % 3.14159) # 总宽度10,小数点后三位,同下一行print('{0:10.3f}'.format(3.14159)) |
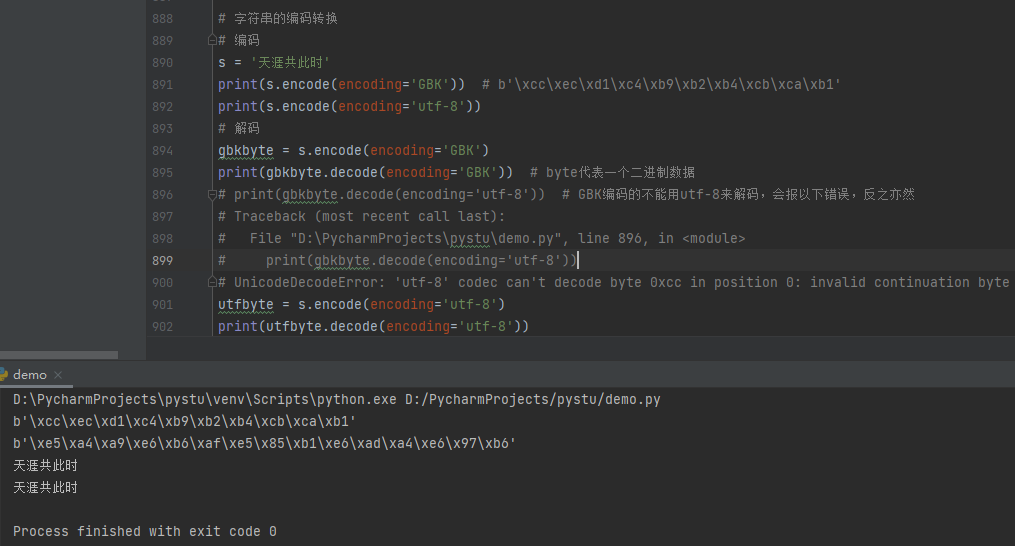
字符串的编码转换
为什么需要字符串的编码转换
字符串在网络中进行传输需要用字节传输,先转换为字节类型传输,再转换成字符串进行演示
编码和解码的方式
编码:将字符串转换为二进制数据
解码:将byte类型的数据转换成字符串类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 字符串的编码转换# 编码s = '天涯共此时'print(s.encode(encoding='GBK')) # b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1'print(s.encode(encoding='utf-8'))# 解码gbkbyte = s.encode(encoding='GBK')print(gbkbyte.decode(encoding='GBK')) # byte代表一个二进制数据# print(gbkbyte.decode(encoding='utf-8')) # GBK编码的不能用utf-8来解码,会报以下错误,反之亦然# Traceback (most recent call last):# File "D:\PycharmProjects\pystu\demo.py", line 896, in <module># print(gbkbyte.decode(encoding='utf-8'))# UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 0: invalid continuation byteutfbyte = s.encode(encoding='utf-8')print(utfbyte.decode(encoding='utf-8')) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报