

jmespath表达式提取器
jmespath表达式提取器
jmespath简介
JMESPath是JSON的查询语言,可以从JSON文档中提取和转换元素,类似于jsonpath
功能详解
基本取值
根据key取值
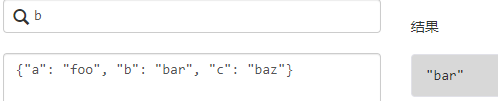
List根据下标取值
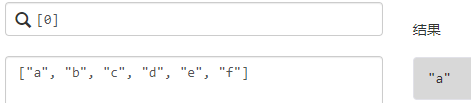
Dict嵌套根据List一层一层取值

切片
与python切片一致,切片形式为[开始:结束:步长 ]




预测
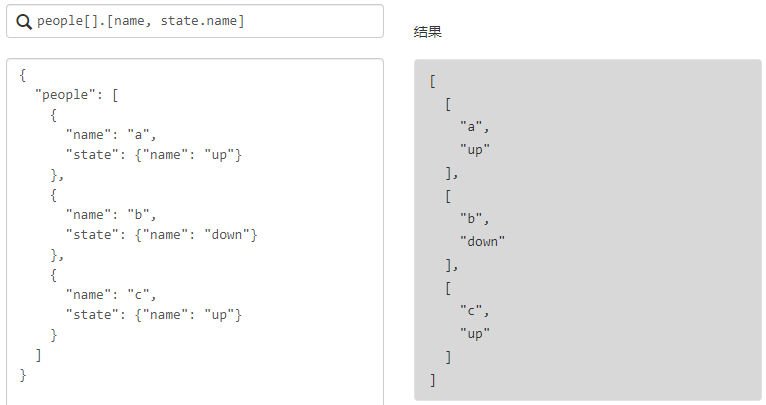
列表与切片投影


对象投影
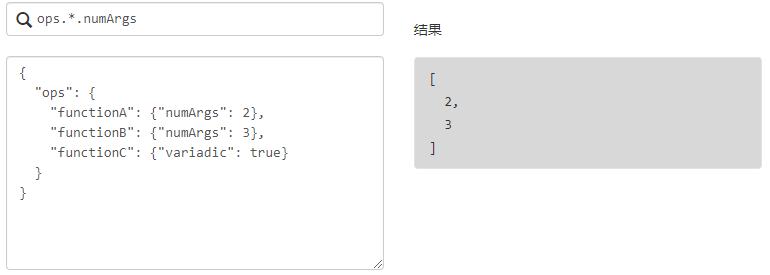
展平投影
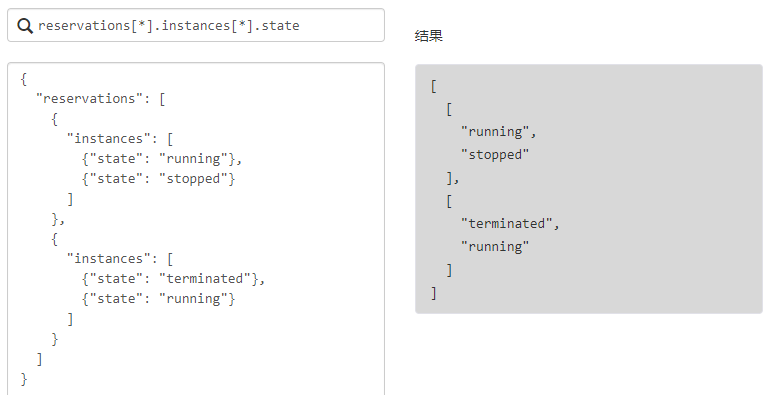
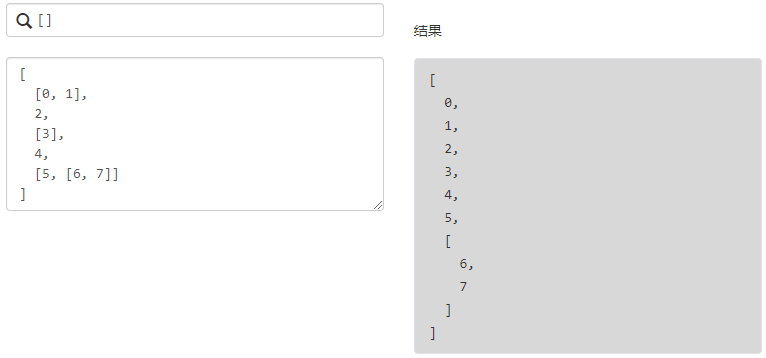
过滤器投影

管道表达式
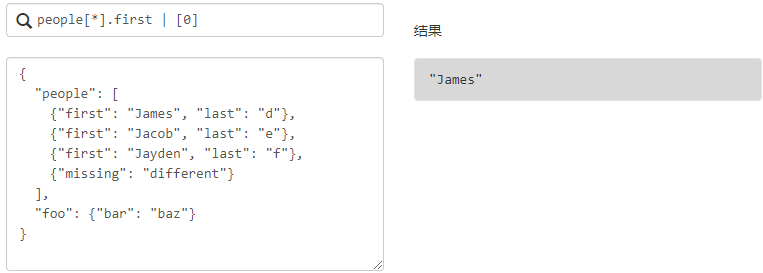
多选

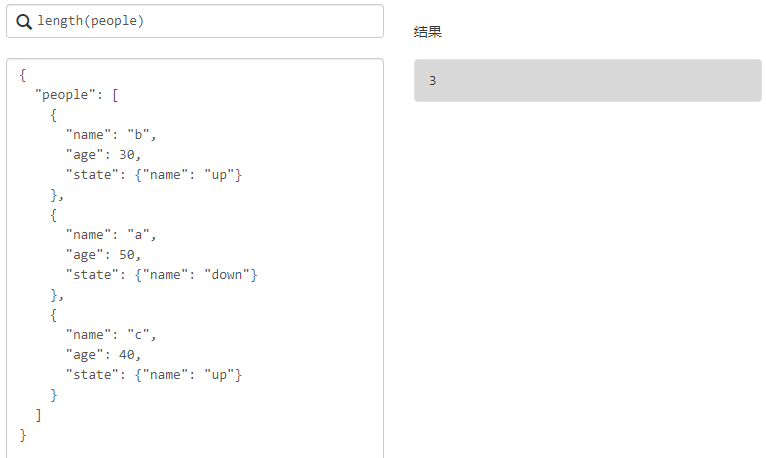
功能
示例代码

body = {
"code": 0,
"msg": "成功success!",
"data": [
{
"age": 20,
"create_time": "2021-01-15",
"id": 1,
"mail": "aaa@163.com",
"name": "abcdefg",
"sex": "M"
},
{
"age": 21,
"id": 2,
"mail": "aaa@163.com",
"name": "abcdef",
"sex": "W"
},
{
"age": 22,
"create_time": "2021-01-17",
"id": 3,
"mail": "abc@163.com",
"name": "acde",
"sex": "W"
},
{
"age": 23,
"create_time": "2021-01-18",
"id": 4,
"name": "abcd",
"sex": "W"
}
]
}
body1 = {
"data": [
{
"mail": [
{"one": "aaa@163.com"},
{"one": "bbb@163.com"}
]
},
{
"mail": [
{"one": "abc@163.com"},
{"one": "ccc@163.com"}
]
},
{
"mail1": [
"abc@163.com",
"abcd@163.com",
"abcde@163.com",
"abcdef@163.com",
"abce@163.com"
]
}
]
}
import jmespath
# 基本取值
res = jmespath.search("code", body)
# 基本取值,取data中第二个的age
res = jmespath.search("data[1].age", body)
# 切片取值,取data中最后三条数据
res = jmespath.search("data[:3:-1]", body)
# 列表与切片投影,取data中所有数据的age
res = jmespath.search("data[*].age", body)
# 列表与切片投影,取data中前三天数据的name
res = jmespath.search("data[:3].name", body)
# 展平投影,取body1中data中的所有mail值
res = jmespath.search("data[*].mail[*].one", body1)
# 展平投影,取data中的所有值
res = jmespath.search("data[]", body)
# 过滤器投影,取出data中create_time为'2019-09-21'的name值
res = jmespath.search("data[?create_time=='2021-01-17'].name", body)
# 管道式表达,取所有的名字,再拿出第一个
res = jmespath.search("data[*].name|[0]", body)
# 管道式表达,取所有的名字,再拿出第一个
res = jmespath.search("data.name[?contains(@,'abc') == true]", body)
# 多选取值,取data内数据的所有的name和sex数据
res = jmespath.search("data[].[name,sex]", body)
# 多选取值,取data内数据的所有的name和sex数据,并带上列名
res = jmespath.search("data[].{Name:name,Sex:sex}", body)
# 功能计算,计算data的长度
res = jmespath.search("length(data)", body)
# 功能取值,取data中id值最大的数据
res = jmespath.search("max_by(data, &id)", body)
# 功能取值,取body1的data中mail1带有hai的数据
res = jmespath.search("data[].mail1[?contains(@, 'aa') == `true`]", body1)
print(res)
分类:
HttpRunner3


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报