
Xpath使用总结1
http://testing.etao.com/node/141
selenium xpath的element打死都找不到
一个自动化的case fail了,追踪下来,发现是一个xpath的locator怎么都找不到。
如下: URL: http://search.taobao.com/search?q=%B0%FC&style=list&bucket_id=1 java.lang.AssertionError: ge, 你真的没在啊, locator: //div[@id='list-content']/ul[@class='list-view hlisting sell lazy-list-view']/li[@class='list-item']/div[@class='photo']/a
但是使用firebug来查看的时候,这个元素确实是存在的,xpath,我几乎是一个一个字符的对比。没啥问题啊,为啥就是selenium找不到呢?
一筹莫展中...
中间sleep,手工查看,没有眉目...
对着那块区域发呆,百无聊赖,傻傻的鼠标hover来hover去,猛然发现,鼠标hover上去的时候,它的class从"photo"变成了"photo hover"了,猛然醒悟了... —— 原来是最近上线了love & hate功能,植入了一段动态js,鼠标悬停的时候,要出来一个hate的按钮,因此,它的样式class就变成“photo hover”,而脚本里面写的是"photo",因此没有match上,因此,selenium它忠实的,不停的,冷冰冰说“xxx not found”.
运行成功之后,有拨云见日之感.
问题2:http://www.2cto.com/kf/201207/142777.html
问题场景:
一般情况下不太用到Xpath去寻找元素,除非id、name、link都不可用的时候
网上有专门的Xpath语法
解决办法:
只列一下我用到的地方
button = driver.find_element_by_xpath("//input[@value='还款']")
tiqian = driver.find_element_by_xpath("//input[@name='repayRadio'][@value='1']")
guidebut = driver.find_element_by_xpath("//a[contains(@href,'regmethod=2')]")
detaillink = driver.find_element_by_xpath("//a[contains(@href, 'BorrowDetailInfoAction')][contains(@href, 'borrowId=%s')]" % i_borrow_id)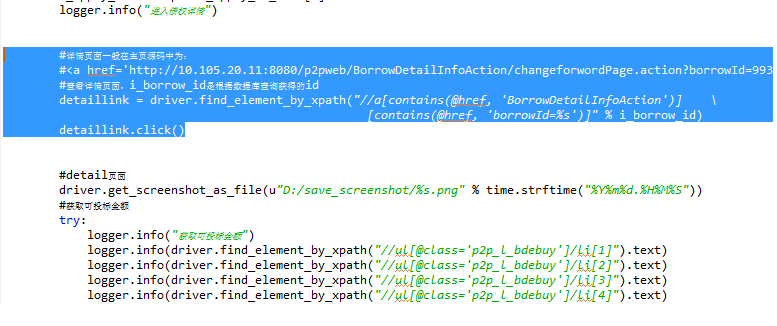
加速IE浏览器自动化执行效率:Selenium自动化中DOM,XPATH,CSS定位Web页面对象的优劣性分析
技术背景 在Web应用中,用户通过键盘在输入框中输入值和鼠标点击按钮,链接等。比如在用户名输入框和密码输入框输入正确的用户名和密码,然后点击登录按钮进行登录。在Selenium自动化中,Selenium提供多种API来对HTML元素进行操作,对于每个HTML元素,需要一个可以标识它的标识符,在Selenium中称之为定位器,Selenium支持多种不同类型的定位器,有标识符,Id,Name, DOM Locator,XPath Locator, 以及CSS Locator等。本文主要讨论DOM, XPATH,以及CSS定位器在不同的浏览器中的使用的优缺点以及注意事项。
问题与挑战 针对一个使用Selenium RC的Web自动化项目,在项目初期在Firefox上采用了比较灵活,简洁的XPath定位器来对应用中的对象进行操作。但在项目开展到1/3时,增加了对IE浏览器支持的需求。在使用现有基于XPath的脚本运行后,发现脚本运行时间呈现几十上百倍地增加,在Firefox上执行花费1分钟的脚本在IE上会花费10~20分钟,甚至更长的时间。该问题就导致了在IE上直接运行之前已完成脚本变得不可行。要了解到Firefox支持原生的Xpath解析功能,而IE不支持原生的Xpath解析,而是基于一个外部的javascript library(Google's library)来进行Xpath解析。由于需求是要求脚本能够同时支持Firefox和IE浏览器,所以需要寻求另外一种方式来使得在不同浏览器上调用Selenium API所执行时间相当。
解决方案 在Selenium RC 0.9.2中,用以解析XPath的javascript库在IE上执行的时间增加了脚本执行时间,而且在越复杂的页面中,在IE上调用API所占用的时间越长。于是决定换用其它类型的定位器,由于该被测Web应用中大多数HTML元素未指定有ID和Name属性,所以在这里首先采用比较灵活的Dom定位器进行测试。
使用Dom定位器来对HTML元素定位,该Locator表达式需要以“dom=” 或者是“document.”开头的形式,Selenium会执行这段javascript片断来最终地取得我们需要访问的HTML元素,由此在Dom定位器中,可以使用Web页面中的DOM对象来获取文档内的所有HTML元素。 需要注意一点的是,Selenium执行这段javascript片断的时候,是采用整段javascript脚本执行的值,也即是在这段javascript片断中最后一个表达式的值。
使用Dom定位器后,在IE上脚本执行的时间比使用Xpath的时候短很多,基本上跟在Firefox上面所花费的时候基本相当。
请参照以下的一个性能对照表:

依照以上表格,不难发现,使用XPath定位器,能使得定位器比较简单,而对于比较复杂的对象(无IE和Name的动态对象)在使用Dom定位器则非常的复杂。由于XPath在IE下的效率极其低下,也只能使用Dom定位器来支持IE浏览器。
在Selenium RC1.0.1版本发布后,Selenium增加了一个新的Xpath的javascript库:Cybozu Labs' faster library。

由以上表格可见,在IE下使用了Cybozu Lab的XPath library后,执行效率有了很大提升,基本上可以与使用Dom定位器相当。通过比较,在新的项目中使用Selenium来进行Web自动化开发,使用XPath定位器,可以使得定位器本生比较简洁,而且也得到较高执行效率。
在Web开发中,有较多的人使用CSS来优化Web页面效果。而Selenium也支持CSS定位器,在IE和Firefox浏览器下,使用CSS定位器时,执行的效率与XPath基本相当,而且CSS定位器同样与XPath比较简洁。所以对CSS比较熟悉的开发人员也可以使用CSS定位器来进行SeleniumWeb自动化开发。
终上所述,在新的Web自动化项目中推荐使用XPATH和CSS定位器,请参考下面的对照表格。

环境设置描述 在需要运行Web浏览器的主机上运行Selenium RC服务,记主机1。 Web自动化程序可以运行在主机1上,也可以运行在任何一台可与主机1进行网络通信的其它主机上,
使用工具简介 Selenium RC服务程序,需要使用JDK/JRE来运行Selenium RC服务。 支持HTTP请求的程序语言,Perl, Ruby, Python, Java, C#等等。 支持所有Javascript-based浏览器。
虽然最新的IE9仍没支持XPath,IE上运行XPath慢,但JavaScript-XPath已经被纳入Selenium。在Java中使用:
XPath原用作确定XML文档中树节点信息,详见参考XPath 1.0和XPath 2.0。使用见文How to parse web pages using XPath。
Firefox有两个插件可以有效定位元素的XPath,一个是鼎鼎大名的Firebug,以下是定位方法:
1.右键选中该元素,点击“查看元素”(Inspect element);
2.Firebug中HTML标签显示该元素前端代码被选,在此标签内右键选择“复制XPath”(Copy XPath)。
这个XPath来自于DOM树经过了修正,实际使用时需要对照页面实际HTML代码校正。此外Firebug命令行控制台提供了$x(xpath)功能,可用于验证该XPath的返回值。
另外一个就是XPath Checker,这个使用就非常简单:右键选中该元素,点击“View XPath”即可。
|
作者:Agoly 出处:https://www.cnblogs.com/qmfsun/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号