

Python只读取文本中文字符

#coding=utf-8 import re with open('aaa.txt','r',encoding="utf-8") as f: #data = f.read().decode('gbk').encode('utf-8') data = f.read() print(data) #str = re.sub(r'(\\u\d+)',"",data) #data = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", data) #data = re.sub('[\W_+]', "", data) data = re.sub('[\u4E00-\u9FA5]',"", data) print(data)
#过滤掉除了中文以外的字符
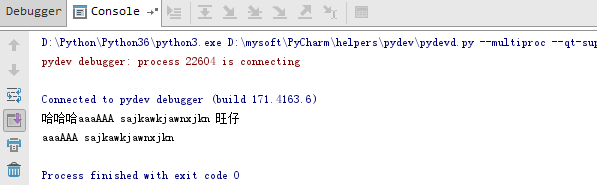
import re """ python 3.5版本 正则匹配中文,固定形式:\u4E00-\u9FA5 """ text = "aqweded***中国***xsa***日本***韩国" regStr = ".*?([\u4E00-\u9FA5]+).*?" aa = re.findall(regStr, text) if aa: print(aa)
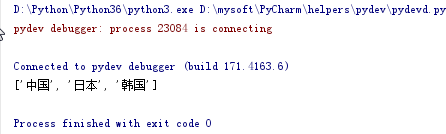
#提取字符串里的中文,返回数组
#coding=utf-8 import re with open('aaa.txt','r',encoding="utf-8") as f: #data = f.read().decode('gbk').encode('utf-8') data = f.read() print(data) data = re.sub("[A-Za-z0-9\!\%\[\]\,\。\ ]", "", data) #data = re.sub('[\u4E00-\u9FA5]',"", data) print(data)

# -*- coding: utf-8 -*- import re #过滤掉除了中文以外的字符 str = "hello,world!!%[545]你好234世界。。。" str = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", str) print(str) #提取字符串里的中文,返回数组 pattern="[\u4e00-\u9fa5]+" regex = re.compile(pattern) results = regex.findall("adf中文adf发京东方") print(results)
|
作者:Agoly 出处:https://www.cnblogs.com/qmfsun/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架