Java集合详解
注意:
集合和数组中存放的都是对象的引用。
看到array,就要想到角标。
看到link,就要想到first,last。可以保证存入的有序性。
看到hash,就要想到hashCode,equals.
看到tree,可以按顺序进行排列,就要想到两个接口。Comparable(集合中元素实现这个接口,元素自身具备可比性),Comparator(比较器,传入容器构造方法中,容器具备可比性)。基于红黑树实现。
0. 数组简介
数组的长度是固定的,可以通过扩容扩大数组的长度,比如:

package loader; import java.util.Arrays; public class Client { public static void main(String[] args) { Object[] objects = new Object[2]; System.out.println(objects.length); objects[0] = 1; objects[1] = 2; System.out.println(Arrays.toString(objects)); // 如果不扩容直接存入第三个值报数组越界(扩容方法一) objects = Arrays.copyOf(objects, 3); objects[2] = 3; System.out.println(Arrays.toString(objects)); // System.arraycopy(原数组名,起始下标,新数组名,起始下标,复制长度);(扩容方法二) Object[] objects2 = new Object[4]; System.arraycopy(objects, 0, objects2, 0, 3); objects2[3] = 4; System.out.println(Arrays.toString(objects2)); } }
结果:
2
[1, 2]
[1, 2, 3]
[1, 2, 3, 4]
解释: (数组扩容的两种方法在org.apache.commons.lang.ArrayUtils广泛使用)
(1) 扩容方法一System.arraycopy解释
System.arraycopy(objects, 0, objects2, 0, 3); 是一个native方法,是将objects数组从下标0开始复制到objects2数组的下标0开始,复制3个数据(相当于全部复制objects)
/* * @param src the source array. * @param srcPos starting position in the source array. * @param dest the destination array. * @param destPos starting position in the destination data. * @param length the number of array elements to be copied. * @exception IndexOutOfBoundsException if copying would cause * access of data outside array bounds. * @exception ArrayStoreException if an element in the <code>src</code> * array could not be stored into the <code>dest</code> array * because of a type mismatch. * @exception NullPointerException if either <code>src</code> or * <code>dest</code> is <code>null</code>. */ public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
(2) Arrays.copyOf (objects, 3)是相当于复制原来objects数组到一个新数组中,新数组的长度为3。查看源码内部也是调用System.arrayCopy, 如下:
public static <T> T[] copyOf(T[] original, int newLength) { return (T[]) copyOf(original, newLength, original.getClass()); } public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { @SuppressWarnings("unchecked") T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }
补充:class.getComponentType 获取的是数组的原始数据类型,然后通过反射的Array工具类可以创建1个数组对象
class.getComponentType 源码如下:
/** * Returns the {@code Class} representing the component type of an * array. If this class does not represent an array class this method * returns null. * * @return the {@code Class} representing the component type of this * class if this class is an array * @see java.lang.reflect.Array * @since JDK1.1 */ public native Class<?> getComponentType();
Array工具类的所有方法如下: (可以改变或获取数据对应下标的值)===结合apache的Arrayutils可以满足对数组的基本操作
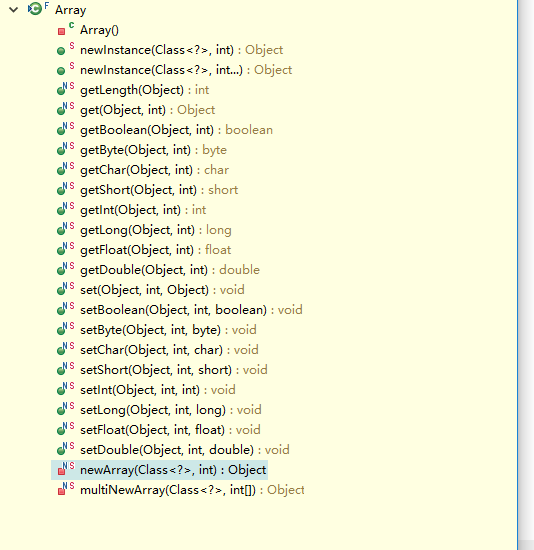
例如:
package loader; import java.lang.reflect.Array; public class Constants { public static void main(String[] args) { String[] strings = { "1", "2" }; System.out.println(strings.getClass().getComponentType()); String[] newInstance = (String[]) Array.newInstance(strings.getClass().getComponentType(), 3); System.out.println(newInstance); System.out.println(newInstance.length); } }
结果:
class java.lang.String
[Ljava.lang.String;@15db9742
3
非数组对象调用getComponentType的返回值是null,直接获取到数组的class不能调用newInstance创建对象,没有构造方法(init是调用初始化方法)。
public static void main(String[] args) throws InstantiationException, IllegalAccessException { // 非数组对象获取不到原始数据类型 System.out.println(Object.class.getComponentType()); String[] strings = { "1", "2" }; String[] newInstance = strings.getClass().newInstance(); }
结果:报错如下
Exception in thread "main" java.lang.InstantiationException: [Ljava.lang.String;
at java.lang.Class.newInstance(Class.java:427)
at loader.Constants.main(Constants.java:10)
Caused by: java.lang.NoSuchMethodException: [Ljava.lang.String;.<init>()
at java.lang.Class.getConstructor0(Class.java:3082)
at java.lang.Class.newInstance(Class.java:412)
... 1 more
null
基于上面的理解创建的扩容工具类:
package loader; import java.lang.reflect.Array; import java.util.Arrays; public class Client { public static void main(String[] args) throws InstantiationException, IllegalAccessException { Object[] objects = new Object[2]; objects[0] = 1; objects[1] = 2; objects = expandCapacity(objects, 4); System.out.println(Arrays.toString(objects)); objects = expandCapacity(objects, 1); System.out.println(Arrays.toString(objects)); } private static <U> U[] expandCapacity(U[] objects, int newLength) { Class<?> componentType = objects.getClass().getComponentType(); U[] newInstance = (U[]) Array.newInstance(componentType, newLength); System.arraycopy(objects, 0, newInstance, 0, Math.min(objects.length, newLength)); return newInstance; } }
结果:
[1, 2, null, null]
[1]
1.集合简介
1.1. 什么是集合
存储对象的容器,面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,存储对象,集合是存储对象最常用的一种方式。
集合的出现就是为了持有对象。集合中可以存储任意类型的对象, 而且长度可变。在程序中有可能无法预先知道需要多少个对象, 那么用数组来装对象的话, 长度不好定义, 而集合解决了这样的问题。
1.2. 集合和数组的区别
数组和集合类都是容器
数组长度是固定的,集合长度是可变的。数组中可以存储基本数据类型,集合只能存储对象。数组中存储数据类型是单一的,集合中可以存储任意类型的对象。
集合类的特点
用于存储对象,长度是可变的,可以存储不同类型的对象。
1.2.1. 数组的缺点
存储类型单一的数据容器,操作复杂(数组一旦声明好不可变)CRUD
1.3 集合的分类
集合做什么
1:将对象添加到集合
2:从集合中删除对象
3: 从集合中查找一个对象
4:从集合中修改一个对象就是增删改查
注意:集合和数组中存放的都是对象的引用而非对象本身
Java工程师对不同的容器进行了定义,虽然容器不同,但是还是有一些共性可以抽取最后抽取了一个顶层接口,那么就形成了一个集合框架。如何学习呢?当然是从顶层学起,顶层里边具有最共性,最基本的行为。具体的使用,就要选择具体的容器了。为什么? 因为不断向上抽取的东西有可能是不能创建对象的.抽象的可能性很大,并且子类对象的方法更多一些. 所以是看顶层,创建底层。那么集合的顶层是什么呢 叫做Collection
集合框架体系
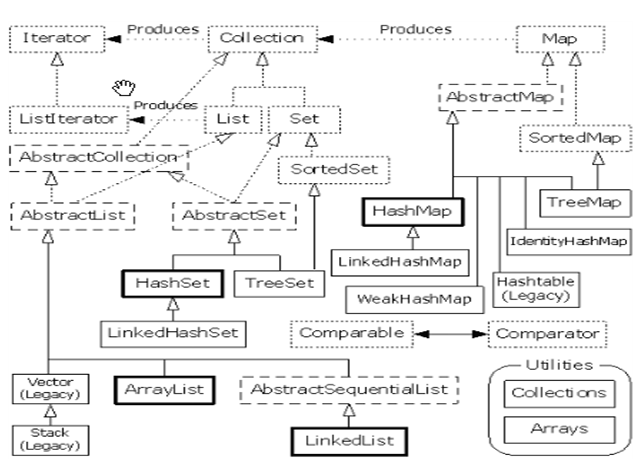
|
---|Collection: 单列集合 ---|List: 有存储顺序, 可重复 ---|ArrayList: 数组实现, 查找快, 增删慢 由于是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢。数组是可以直接按索引查找, 所以查找时较快。初始大小是10,增长为原来的1.5倍 ---|LinkedList: 双向链表实现, 增删快, 查找慢 由于链表实现, 增加时只要让前一个元素记住自己就可以, 删除时让前一个元素记住后一个元素, 后一个元素记住前一个元素. 这样的增删效率较高但查询时需要一个一个的遍历, 所以效率较低。 ---|Vector: 和ArrayList原理相同, 但线程安全, 效率略低 和ArrayList实现方式相同, 但考虑了线程安全问题, 所以效率略低。初始大小是10,增长为原来的2倍。 ---|Set: 无存储顺序, 不可重复。内部都是维护了一个map用于存储数据,我们add进去的内容都是作为map的key,value是一个定值Object。 ---|HashSet--内部维护一个map,我们存放的信息放在key,value就是一个固定的Object。HashMap的key不可以重复(阅读源码的put方法,key重复会替换value值),所以其set不可以重复(允许存null,且放在第一个位置)。当为HashSet的时候map实际类型为HashMap,当为LinkedHashSet的时候map为LinkedHashMap。 ---|TreeSet--内部通过TreeMap实现,由于TreeMap的key可以排序,因此Set可以做到有序。TreeMap不允许key为null,所以不能存null,null会直接报空指针异常。 ---|LinkedHashSet--继承hashSet,且增加了自己的方法。将父类HashSet中的map初始化为LinkedHashMap保存存入的顺序,其保证顺序的机制见LinkedHashMap的有序机制。允许值为null。 ---| Map: 键值对 ---|HashMap 线程非安全,初始化16个数组大小。成倍增长。允许一个key为null,多个value为null(key为null的时候存在数组的第一个位置table[0])。(HashMap的key不可以重复,阅读源码的put方法,key重复会替换value值) ---|TreeMap------可以按照key进行排序,前提是key元素实现Comparable接口或者给Treemap传入一个实现Comparator的比较器。红黑树实现。不允许key为null,允许value为null(因为key要进行compare比较)。 ---|HashTable---线程安全,初始化11个数组大小,增长时2*old+1。key和value都不能是null。 ---|LinkedHashMap 保存了记录的插入顺序,继承hashmap,实现Map接口。允许一个key为null,多个value为null。-----原理是其内部类 Entry维护了一个header和before记录顺序,没有重写put方法,重写了addEntry()方法,因为HashMap的put方法中调用addEntry方法()。 |
为什么出现这么多集合容器,因为每一个容器对数据的存储方式不同,这种存储方式称之为数据结构(data structure)
注意
集合和数组中存放的都是对象的引用。
看到array,就要想到角标。
看到link,就要想到first,last。
看到hash,就要想到hashCode,equals.
看到tree,就要想到两个接口。Comparable,Comparator。
1.4 什么时候该使用什么样的集合
|
Collection |
我们需要保存若干个对象的时候使用集合。 |
|
List
|
如果我们需要保留存储顺序, 并且保留重复元素, 使用List. 如果查询较多, 那么使用ArrayList--基于数组实现 如果存取较多, 那么使用LinkedList--基于双向链表实现 如果需要线程安全, 那么使用Vector--基于数组实现,只是线程安全 |
|
Set
|
如果我们不需要保留存储顺序, 并且需要去掉重复元素, 使用Set. 如果我们需要将元素排序, 那么使用TreeSet--内部基于SortedMap实现 如果我们不需要排序, 使用HashSet, HashSet比--内部基于HashMap实现 TreeSet效率高. 如果我们需要保留存储顺序, 又要过滤重复元素, 那么使用LinkedHashSet--内部基于HashMap实现 |
2. 集合类(Collection)
1. Collection接口有两个子接口:
List(链表|线性表)
Set(集)
特点:
Collection中描述的是集合共有的功能(CRUD)
List可存放重复元素,元素存取是有序的
Set不可以存放重复元素,元素存取是无序的
|
java.util.Collection ---| Collection 描述所有接口的共性 ----| List接口 可以有重复元素的集合 ----| Set 接口 不可以有重复元素的集合 |
2. 学习集合对象
学习Collection中的共性方法,多个容器在不断向上抽取就出现了该体系。发现Collection接口中具有所有容器都具备的共性方法。查阅API时,就可以直接看该接口中的方法。并创建其子类对象对集合进行基本应用。当要使用集合对象中特有的方法,在查看子类具体内容。
查看api 文档Collection在在java.util 中(注意是大写Collection)
注意在现阶段遇到的 E T 之类的类型,需要暂时理解为object 因为涉及到了泛型.
3:创建集合对象,使用Collection中的List的具体实现类ArrayList
1:Collection coll=new Arraylist();
2.1 Collection接口的共性方法
增加:
1:add() 将指定对象存储到容器中
add 方法的参数类型是Object 便于接收任意对象
2:addAll() 将指定集合中的元素添加到调用该方法和集合中
删除:
3:remove() 将指定的对象从集合中删除
4:removeAll() 将指定集合中的元素删除
修改
5:clear() 清空集合中的所有元素
判断
6:isEmpty() 判断集合是否为空
7:contains() 判断集合何中是否包含指定对象
8:containsAll() 判断集合中是否包含指定集合
使用equals()判断两个对象是否相等
获取: 9:int size() 返回集合容器的大小
转成数组10: toArray() 集合转换数组
2.1.1. 增加:
public static void main(String[] args) { Collection list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); System.out.println(list); // [计算机网络, 现代操作系统, java编程思想] // 增加2 将list容器元素添加到list2容器中 Collection list2 = new ArrayList(); list2.add("java核心技术"); list2.addAll(list); list2.add("java语言程序设计"); System.out.println(list2); // [java核心技术, 计算机网络, 现代操作系统, java编程思想, java语言程序设计] }
2.1.2 删除:
// 删除1 remove boolean remove = list2.remove("java核心技术"); System.out.println(remove); // true System.out.println(list2); // // 删除2 removeAll() 将list中的元素删除 boolean removeAll = list2.removeAll(list); System.out.println(removeAll);// true System.out.println(list2);// [java语言程序设计]
2.1.3 修改
public static void main(String[] args) { Collection list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 修改 clear() 清空集合中的所有元素 list.clear(); System.out.println(list); //[] }
2.1.4 判断
public static void main(String[] args) { Collection list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); boolean empty = list.isEmpty(); System.out.println(empty);// false boolean contains = list.contains("java编程思想"); System.out.println(contains);// true Collection list2 = new ArrayList(); list2.add("水许传"); boolean containsAll = list.containsAll(list2); System.out.println(containsAll);// false }
2.1.5 获取集合大小
public static void main(String[] args) { Collection list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 获取 集合容器的大小 int size = list.size(); System.out.println(size); }
2.2 List 详解
---| Iterable 接口
Iterator iterator()
----| Collection 接口
------| List 接口 元素可以重复,允许在指定位置插入元素,并通过索引来访问元素
2.1.1 List集合特有方法
1:增加 void add(int index, E element) 指定位置添加元素 boolean addAll(int index, Collection c) 指定位置添加集合 2:删除 E remove(int index) 删除指定位置元素 3:修改 E set(int index, E element) 返回的是需要替换的集合中的元素 4:查找: E get(int index) 注意: IndexOutOfBoundsException int indexOf(Object o) // 找不到返回-1 lastIndexOf(Object o) 5:求子集合 List<E> subList(int fromIndex, int toIndex) // 不包含toIndex
- 增加
public static void main(String[] args) { List list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // add,在0角标位置添加一本书 list.add(0, "舒克和贝塔"); System.out.println(list); // 在list2集合的1角标位置添加list集合元素 List list2 = new ArrayList(); list2.add("史记"); list2.add("资治通鉴"); list2.add("全球通史"); boolean addAll = list2.addAll(1, list); System.out.println(addAll); //true System.out.println(list2); }
- 删除
public static void main(String[] args) { List list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 删除0角标元素 Object remove = list.remove(0); System.out.println(remove); }
- 修改
public static void main(String[] args) { List list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 修改2角标位置的书,返回的原来2角标位置的书 Object set = list.set(2, "边城"); System.out.println(set); //java编程思想 System.out.println(list); }
- 查找
public static void main(String[] args) { List list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); list.add("java编程思想"); System.out.println(list); // 查找: E get(int index) 注意角标越界 Object set = list.get(list.size() - 1); System.out.println(set); // java语言程序设计 System.out.println(list); // list.get(list.size()); //IndexOutOfBoundsException // indexOf(Object o) 返回第一次出现的指定元素的角标 int indexOf = list.indexOf("java编程思想"); System.out.println(indexOf); // 2 // 没有找到,返回-1 int indexOf2 = list.indexOf("三国志"); System.out.println(indexOf2); // -1 // lastIndexOf 返回最后出现的指定元素的角标 int lastIndexOf = list.lastIndexOf("java编程思想"); System.out.println(lastIndexOf); // 5 }
---------------------S 重写equals和hashcode的Person方法-------------------------------
1:如果不重写,调用Object类的equals方法,判断内存地址,为false
1:如果是Person类对象,并且姓名和年龄相同就返回true
2:如果不重写,调用父类hashCode方法
1:如果equals方法相同,那么hashCode也要相同,需要重写hashCode方法
3:重写toString方法
1:不重写,直接调用Object类的toString方法,打印该对象的内存地址
package CollectionTest; public class Person { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public int hashCode() { // TODO Auto-generated method stub return this.name.hashCode()+age; } @Override public boolean equals(Object obj) { if (!(obj instanceof Person)) { return false; } Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } protected Person(String name, int age) { super(); this.name = name; this.age = age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } }
---------------------E 重写equals和hashcode的Person方法-------------------------------
2.2.2 ArrayList的用法
--| Iterable
----| Collection
------| List
---------| ArrayList 底层采用数组实现,默认10。每次增长50%, 查询快,增删慢。
---------| LinkedList 双向链表实现。查询慢,增删快
ArrayList:实现原理:
数组实现, 查找快, 增删慢
数组为什么是查询快?因为数组的内存空间地址是连续的.
ArrayList底层维护了一个Object[] 用于存储对象,默认数组的长度是10。可以通过 new ArrayList(20)显式的指定用于存储对象的数组的长度。
当默认的或者指定的容量不够存储对象的时候,容量自动增长为原来的容量的1.5倍。
由于ArrayList是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢。数组是可以直接按索引查找, 所以查找时较快
可以考虑,假设向数组的0角标未知添加元素,那么原来的角标位置的元素需要整体往后移,并且数组可能还要增容,一旦增容,就需要要将老数组的内容拷贝到新数组中.所以数组的增删的效率是很低的.
public static void main(String[] args) { ArrayList arr = new ArrayList(); Person p1 = new Person("jack", 20); Person p2 = new Person("rose", 18); Person p3 = new Person("rose", 18); arr.add(p1); arr.add(p2); arr.add(p3); System.out.println(arr); // [Person [name=jack, age=20], Person [name=rose, age=18], Person [name=rose, age=18]] ArrayList arr2 = new ArrayList(); for (int i = 0; i < arr.size(); i++) { Object obj = arr.get(i); Person p = (Person) obj; if (!(arr2.contains(p))) { arr2.add(p); } } System.out.println(arr2); // [Person [name=jack, age=20], Person [name=rose, age=18]] }
2.2.3 LinkedList的用法
--| Iterable ----| Collection ------| List ---------| ArrayList 底层采用数组实现,默认10。每次增长50% 查询快,增删慢。 ---------| LinkedList 底层采用双向链表实现,增删快,查询慢。
LinkedList:链表实现, 增删快, 查找慢
由于LinkedList:在内存中的地址不连续,需要让上一个元素记住下一个元素.所以每个元素中保存的有下一个元素的位置.虽然也有角标,但是查找的时候,需要从头往下找,显然是没有数组查找快的.但是,链表在插入新元素的时候,只需要让前一个元素记住新元素,让新元素记住下一个元素就可以了.所以插入很快.
由于链表实现, 增加时只要让前一个元素记住自己就可以, 删除时让前一个元素记住后一个元素, 后一个元素记住前一个元素. 这样的增删效率较高。
但查询时需要一个一个的遍历, 所以效率较低。
特有方法
1:方法介绍 addFirst(E e) addLast(E e) getFirst() getLast() removeFirst() removeLast() 如果集合中没有元素,获取或者删除元 素抛:NoSuchElementException 2:数据结构 1:栈 (1.6) 先进后出 push() pop() 2:队列(双端队列1.5) 先进先出 offer() poll() 3:返回逆序的迭代器对象 descendingIterator() 返回逆序的迭代器对象
基本方法:
package CollectionTest; import java.util.LinkedList; @SuppressWarnings("all") public class LinkedListTest { public static void main(String[] args) { LinkedList list = new LinkedList(); list.add("西游记"); list.add("三国演义"); list.add("石头记"); list.add("水浒传"); list.add("全球通史"); // 往头顶添加 list.addFirst("史记"); // 往最后添加 list.addLast("呐喊"); // list.addFirst(null); // list.addLast(null); System.out.println(list); // 获取指定位置处的元素。 String str = (String) list.get(0); // 返回此列表的第一个元素。 String str2 = (String) list.getFirst(); System.out.println(str.equals(str2)); // 获取指定位置处的元素。 String str3 = (String) list.get(list.size() - 1); // 返回此列表的最后一个元素。 String str4 = (String) list.getLast(); System.out.println(str3.equals(str4)); // 获取但不移除此列表的头(第一个元素)。 Object element = list.element(); System.out.println(element); int size = list.size(); System.out.println(size); } }
结果:
[史记, 西游记, 三国演义, 石头记, 水浒传, 全球通史, 呐喊]
true
true
史记
7
- 迭代器遍历list集合:(正序迭代)
@Test public void test1(){ LinkedList list = new LinkedList(); list.add("西游记"); list.add("三国演义"); list.add("石头记"); list.add("水浒传"); list.add("全球通史"); Iterator it = list.iterator(); while (it.hasNext()) { String next = (String) it.next(); System.out.println(next); } }
- 迭代器遍历list集合:(逆序迭代)
/** * 逆袭迭代集合 */ @Test public void test2(){ LinkedList list = new LinkedList(); list.add("aa"); list.add("bb"); list.add("cc"); Iterator dit = list.descendingIterator(); while (dit.hasNext()) { System.out.println(dit.next()); } }
- LinkedList作为栈的使用
/** * 模拟作为栈结构(后进先出) */ @Test public void test3(){ LinkedList list = new LinkedList(); // 压栈,先进后出 list.push("西游记"); list.push("三国演义"); list.push("石头记"); list.push("水浒传"); System.out.println(list); // 弹栈(获取到元素并且删除元素) String str1 = (String) list.pop(); System.out.println(str1); String str2 = (String) list.pop(); System.out.println(str2); String str3 = (String) list.pop(); System.out.println(str3); String str4 = (String) list.pop(); System.out.println(str4); System.out.println(list.size());// 0 System.out.println(list); //[] }
[水浒传, 石头记, 三国演义, 西游记]
水浒传
石头记
三国演义
西游记
0
[]
- LinkedList作为队列使用 (先进先出)
/** * 作为队列的使用(先进先出) */ @Test public void test4() { LinkedList list = new LinkedList(); // 队列,先进先出 list.offer("西游记"); list.offer("三国演义"); list.offer("石头记"); list.offer("水浒传"); System.out.println(list); // 出队列 System.out.println(list.poll()); System.out.println(list.poll()); System.out.println(list.poll()); System.out.println(list.poll()); System.out.println(list.size()); System.out.println(list.peek()); // 获取队列的头元素,但是不删除 System.out.println(list.peekFirst()); // 获取队列的头元素,但是不删除 System.out.println(list.peekLast()); // 获取队列的最后一个元素但是不删除 }
[西游记, 三国演义, 石头记, 水浒传]
西游记
三国演义
石头记
水浒传
0
null
null
null
ArrayList 和 LinkedList的存储查找的优缺点:
1、ArrayList 是采用动态数组来存储元素的,它允许直接用下标号来直接查找对应的元素。但是,但是插入元素要涉及数组元素移动及内存的操作。总结:查找速度快,插入操作慢。
2、LinkedList 是采用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快
问题:有一批数据要存储,要求存储这批数据不能出现重复数据,ArrayList、LinkedList都没法满足需求。解决办法:使用 set集合。
2.3.4 Vector的使用
Vector: 描述的是一个线程安全的ArrayList。
ArrayList: 单线程效率高
Vector : 多线程安全的,所以效率低
特有的方法:
void addElement(E obj) 在集合末尾添加元素 E elementAt( int index) 返回指定角标的元素 Enumeration elements() 返回集合中的所有元素,封装到Enumeration对象中 Enumeration 接口: boolean hasMoreElements() 测试此枚举是否包含更多的元素。 E nextElement() 如果此枚举对象至少还有一个可提供的元素,则返回此枚举的下一个元素。
public static void main(String[] args) { Vector v = new Vector(); v.addElement("aaa"); v.addElement("bbb"); v.addElement("ccc"); System.out.println( v ); System.out.println( v.elementAt(2) ); // ccc // 遍历Vector遍历 Enumeration ens = v.elements(); while ( ens.hasMoreElements() ) { System.out.println( ens.nextElement() ); } Iterator iterator = v.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } }
2.3迭代器
为了方便的处理集合中的元素,Java中出现了一个对象,该对象提供了一些方法专门处理集合中的元素.例如删除和获取集合中的元素.该对象就叫做迭代器(Iterator).
对 Collection 进行迭代的类,称其为迭代器。还是面向对象的思想,专业对象做专业的事情,迭代器就是专门取出集合元素的对象。但是该对象比较特殊,不能直接创建对象(通过new),该对象是以内部类的形式存在于每个集合类的内部。
如何获取迭代器?Collection接口中定义了获取集合类迭代器的方法(iterator()),所以所有的Collection体系集合都可以获取自身的迭代器。
正是由于每一个容器都有取出元素的功能。这些功能定义都一样,只不过实现的具体方式不同(因为每一个容器的数据结构不一样)所以对共性的取出功能进行了抽取,从而出现了Iterator接口。而每一个容器都在其内部对该接口进行了内部类的实现。也就是将取出方式的细节进行封装。
2.3.1 Iterable
Jdk1.5之后添加的新接口, Collection的父接口. 实现了Iterable的类就是可迭代的.并且支持增强for循环。该接口只有一个方法即获取迭代器的方法iterator()可以获取每个容器自身的迭代器Iterator。(Collection)集合容器都需要获取迭代器(Iterator)于是在5.0后又进行了抽取将获取容器迭代器的iterator()方法放入到了Iterable接口中。Collection接口进程了Iterable,所以Collection体系都具备获取自身迭代器的方法,只不过每个子类集合都进行了重写(因为数据结构不同)
2.3.2 Iterator
Iterator iterator() 返回该集合的迭代器对象
该类主要用于遍历集合对象,该类描述了遍历集合的常见方法 1:java.lang. Itreable ---| Itreable 接口 实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 可以有重复元素的集合 ---| Set接口 不可以有重复元素的集合
public interface Iterable<T>
Itreable 该接口仅有一个方法,用于返回集合迭代器对象。
1: Iterator<T> iterator() 返回集合的迭代器对象
Iterator接口定义的方法
Itreator 该接口是集合的迭代器接口类,定义了常见的迭代方法 1:boolean hasNext() 判断集合中是否有元素,如果有元素可以迭代,就返回true。 2: E next() 返回迭代的下一个元素,注意: 如果没有下一个元素时,调用next元素会抛出NoSuchElementException 3: void remove() 从迭代器指向的集合中移除迭代器返回的最后一个元素(可选操作)。
例如:Vector内部迭代器实现类源码分析:
/** * An optimized version of AbstractList.Itr */ private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; public boolean hasNext() { // Racy but within spec, since modifications are checked // within or after synchronization in next/previous return cursor != elementCount; } public E next() { synchronized (Vector.this) { checkForComodification(); int i = cursor; if (i >= elementCount) throw new NoSuchElementException(); cursor = i + 1; return elementData(lastRet = i); } } public void remove() { if (lastRet == -1) throw new IllegalStateException(); synchronized (Vector.this) { checkForComodification(); Vector.this.remove(lastRet); expectedModCount = modCount; } cursor = lastRet; lastRet = -1; } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
解释:cursor默认为0。返回元素之后,cursor加一,同时将未加一的cursor赋值给lastRet。删除的时候也是根据上次返回的删除,所以调用删除之前必须先执行next()方法。cursor始终比lastRet大一, cursor 代表当前游标,可以理解为下一个元素的下标,lastRet 代表上次返回的元素的下标。
比如第一次访问next()之后: cursor为1,lastRet为0,返回下标为lastRet的元素(返回第一个元素)。调用remove()方法的时候删除下标为lastRet的元素,删除第一个元素。
next():将cursor赋值给lastRet,将cursor加一,返回元素的时候返回下标为lastRet的元素。
补充:关于迭代器删除
java.util.Iterator#remove 删除方法如下:
default void remove() { throw new UnsupportedOperationException("remove"); }
也就是默认删除会报错,需要实现类类选择性重写该方法。今天我就遇到一个迭代器没有 重写这个方法直接报错。
以Vector 内部迭代器删除代码为例。 我们知道调用next 方法之后会根据cursor 拿到元素,然后cursor 加一,cursor 指向下一个元素; 并且将lastRet 记录为当前去除的元素的下标。删除remove 方法会根据lastRet 删掉元素,删除完之后cursor 向上移动,也就是cursor 减1,然后清空lastRet。
2.3.3迭代器遍历:
1. while循环
public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); Iterator it = list.iterator(); while (it.hasNext()) { String next = (String) it.next(); System.out.println(next); } }
2. for循环
public class Demo2 { public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); for (Iterator it = list.iterator(); it.hasNext();) { //迭代器的next方法返回值类型是Object,所以要记得类型转换。 String next = (String) it.next(); System.out.println(next); } } }
需要取出所有元素时,可以通过循环,java 建议使用for 循环。因为可以对内存进行一下优化。
3:使用迭代器清空集合
public class Demo1 { public static void main(String[] args) { Collection coll = new ArrayList(); coll.add("aaa"); coll.add("bbb"); coll.add("ccc"); coll.add("ddd"); System.out.println(coll); Iterator it = coll.iterator(); while (it.hasNext()) { it.next(); it.remove(); } System.out.println(coll); } }
细节一:
如果迭代器的指针已经指向了集合的末尾,那么如果再调用next()会返回NoSuchElementException异常
细节二:
如果调用remove之前没有调用next是不合法的,会抛出IllegalStateException
4:迭代器原理
查看ArrayList源码
private class Itr implements Iterator<E> { int cursor = 0; int lastRet = -1; int expectedModCount = modCount; public boolean hasNext() { return cursor != size(); } public E next() { checkForComodification(); try { E next = get(cursor); lastRet = cursor++; return next; } catch (IndexOutOfBoundsException e) { checkForComodification(); throw new NoSuchElementException(); } } public void remove() { if (lastRet == -1) throw new IllegalStateException(); checkForComodification(); try { AbstractList.this.remove(lastRet); if (lastRet < cursor) cursor--; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException e) { throw new ConcurrentModificationException(); } } }
5. 注意在对集合进行迭代过程中,不允许出现迭代器以外的对元素的操作,因为这样会产生安全隐患,java会抛出异常并发修改异常(ConcurrentModificationException),普通迭代器只支持在迭代过程中的删除动作。
注意: ConcurrentModificationException: 当一个集合在循环中即使用引用变量操作集合又使用迭代器操作集合对象, 会抛出该异常。
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class Demo1 { public static void main(String[] args) { Collection coll = new ArrayList(); coll.add("aaa"); coll.add("bbb"); coll.add("ccc"); coll.add("ddd"); System.out.println(coll); Iterator it = coll.iterator(); while (it.hasNext()) { it.next(); it.remove(); coll.add("abc"); // 出现了迭代器以外的对元素的操作 } System.out.println(coll); } }
如果是List集合,想要在迭代中操作元素可以使用List集合的特有迭代器ListIterator,该迭代器支持在迭代过程中,添加元素和修改元素。
2.3.4 List特有的迭代器ListIterator
public interface ListIterator extends Iterator
ListIterator<E> listIterator()
---| Iterator hasNext() next() remove() ------| ListIterator Iterator子接口 List专属的迭代器 add(E e) 将指定的元素插入列表(可选操作)。该元素直接插入到 next 返回的下一个元素的前面(如果有) void set(E o) 用指定元素替换 next 或 previous 返回的最后一个元素 hasPrevious() 逆向遍历列表,列表迭代器有多个元素,则返回 true。 previous() 返回列表中的前一个元素。
Iterator在迭代时,只能对元素进行获取(next())和删除(remove())的操作。
对于 Iterator 的子接口ListIterator 在迭代list 集合时,还可以对元素进行添加
(add(obj)),修改set(obj)的操作。
import java.util.ArrayList; import java.util.ListIterator; public class Demo2 { public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 获取List专属的迭代器 ListIterator lit = list.listIterator(); while (lit.hasNext()) { String next = (String) lit.next(); System.out.println(next); } } }
倒序遍历
import java.util.ArrayList; import java.util.ListIterator; public class Demo2 { public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); // 获取List专属的迭代器 ListIterator lit = list.listIterator(); while (lit.hasNext()) { String next = (String) lit.next(); System.out.println(next); } System.out.println("***************"); while (lit.hasPrevious()) { String next = (String) lit.previous(); System.out.println(next); } } }
Set方法:用指定元素替换 next或 previous返回的最后一个元素
import java.util.ArrayList; import java.util.ListIterator; public class Demo2 { public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); ListIterator lit = list.listIterator(); lit.next(); // 计算机网络 lit.next(); // 现代操作系统 System.out.println(lit.next()); // java编程思想 //用指定元素替换 next 或 previous 返回的最后一个元素 lit.set("平凡的世界");// 将java编程思想替换为平凡的世界 System.out.println(list); } }
add方法将指定的元素插入列表,该元素直接插入到 next 返回的元素的后
public class Demo2 { public static void main(String[] args) { ArrayList list = new ArrayList(); // 增加:add() 将指定对象存储到容器中 list.add("计算机网络"); list.add("现代操作系统"); list.add("java编程思想"); list.add("java核心技术"); list.add("java语言程序设计"); System.out.println(list); ListIterator lit = list.listIterator(); lit.next(); // 计算机网络 lit.next(); // 现代操作系统 System.out.println(lit.next()); // java编程思想 // 将指定的元素插入列表,该元素直接插入到 next 返回的元素的后 lit.add("平凡的世界");// 在java编程思想后添加平凡的世界 System.out.println(list); } }
2.4 Set用法
Set:注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素。原理是内部基于Map实现,我们的元素添加在map的key上,value是一个固定的Object。
以HashSet为例分析不能重复的原理:
(1)HashSet初始化的时候创建一个hashmap:
private transient HashMap<E,Object> map; private static final Object PRESENT = new Object(); public HashSet() { map = new HashMap<>(); }
(2)添加元素的时候将我们传下来的元素作为map的key保存到map中,value是一个Object常量。
public boolean add(E e) { return map.put(e, PRESENT)==null; }
(3)清空的时候调用map的clear()方法:
public void clear() { map.clear(); }
用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
对象的相等性
引用到堆上同一个对象的两个引用是相等的。如果对两个引用调用hashCode方法,会得到相同的结果,如果对象所属的类没有覆盖Object的hashCode方法的话,hashCode会返回每个对象特有的序号(java是依据对象的内存地址计算出的此序号),所以两个不同的对象的hashCode值是不可能相等的。
如果想要让两个不同的Person对象视为相等的,就必须覆盖Object继下来的hashCode方法和equals方法,因为Object hashCode方法返回的是该对象的内存地址,所以必须重写hashCode方法,才能保证两个不同的对象具有相同的hashCode,同时也需要两个不同对象比较equals方法会返回true
该集合中没有特有的方法,直接继承自Collection。
---| Itreable 接口 实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 可以有重复元素的集合 ---| ArrayList ---| LinkedList ---| Set接口 不可以有重复元素的集合
import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class Demo4 { public static void main(String[] args) { //Set 集合存和取的顺序不一致。 Set hs = new HashSet(); hs.add("世界军事"); hs.add("兵器知识"); hs.add("舰船知识"); hs.add("汉和防务"); System.out.println(hs); // [舰船知识, 世界军事, 兵器知识, 汉和防务] Iterator it = hs.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } }
2.4.1 HashSet (基于hashmap实现)
|
---| Itreable 接口实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 可以有重复元素的集合 ---| ArrayList ---| LinkedList ---| Set接口 不可以有重复元素的集合 ---| HashSet 线程不安全,存取速度快。底层是以哈希表实现的。 |
HashSet
哈希表边存放的是哈希值。HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同)是按照哈希值来存的所以取数据也是按照哈希值取得。
HashSet不存入重复元素的规则.使用hashcode和equals
由于Set集合是不能存入重复元素的集合。那么HashSet也是具备这一特性的。HashSet如何检查重复?HashSet会通过元素的hashcode()和equals方法进行判断元素师否重复。
当你试图把对象加入HashSet时,HashSet会使用对象的hashCode来判断对象加入的位置。同时也会与其他已经加入的对象的hashCode进行比较,如果没有相等的hashCode,HashSet就会假设对象没有重复出现。
简单一句话,如果对象的hashCode值是不同的,那么HashSet会认为对象是不可能相等的。
因此我们自定义类的时候需要重写hashCode,来确保对象具有相同的hashCode值。
如果元素(对象)的hashCode值相同,是不是就无法存入HashSet中了? 当然不是,会继续使用equals 进行比较.如果 equals为true 那么HashSet认为新加入的对象重复了,所以加入失败。如果equals 为false那么HashSet 认为新加入的对象没有重复.新元素可以存入.
总结:
元素的哈希值是通过元素的hashcode方法来获取的, HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。
哈希值相同equals为false的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。
hashtable
HashSet:通过hashCode值来确定元素在内存中的位置。一个hashCode位置上可以存放多个元素。
当hashcode() 值相同equals() 返回为true 时,hashset 集合认为这两个元素是相同的元素.只存储一个(重复元素无法放入)。调用原理:先判断hashcode 方法的值,如果相同才会去判断equals 如果不相同,是不会调用equals方法的。
HashSet到底是如何判断两个元素重复。
通过hashCode方法和equals方法来保证元素的唯一性,add()返回的是boolean类型
判断两个元素是否相同,先要判断元素的hashCode值是否一致,只有在该值一致的情况下,才会判断equals方法,如果存储在HashSet中的两个对象hashCode方法的值相同equals方法返回的结果是true,那么HashSet认为这两个元素是相同元素,只存储一个(重复元素无法存入)。
注意:HashSet集合在判断元素是否相同先判断hashCode方法,如果相同才会判断equals。如果不相同,是不会调用equals方法的。
HashSet 和ArrayList集合都有判断元素是否相同的方法,
boolean contains(Object o)
HashSet使用hashCode和equals方法,ArrayList使用了equals方法
import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class Demo4 { public static void main(String[] args) { // Set 集合存和取的顺序不一致。 Set hs = new HashSet(); hs.add("世界军事"); hs.add("兵器知识"); hs.add("舰船知识"); hs.add("汉和防务"); // 返回此 set 中的元素的数量 System.out.println(hs.size()); // 4 // 如果此 set 尚未包含指定元素,则返回 true boolean add = hs.add("世界军事"); // false System.out.println(add); // 返回此 set 中的元素的数量 System.out.println(hs.size());// 4 Iterator it = hs.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } }
package cn.itcast.gz.map; import java.util.HashSet; import java.util.Iterator; public class Demo4 { public static void main(String[] args) { HashSet hs = new HashSet(); hs.add(new Person("jack", 20)); hs.add(new Person("rose", 20)); hs.add(new Person("hmm", 20)); hs.add(new Person("lilei", 20)); hs.add(new Person("jack", 20)); Iterator it = hs.iterator(); while (it.hasNext()) { Object next = it.next(); System.out.println(next); } } } class Person { private String name; private int age; Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public int hashCode() { System.out.println("hashCode:" + this.name); return this.name.hashCode() + age * 37; } @Override public boolean equals(Object obj) { System.out.println(this + "---equals---" + obj); if (obj instanceof Person) { Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } else { return false; } } @Override public String toString() { return "Person@name:" + this.name + " age:" + this.age; } }
2.4.2 TreeSet(内部基于TreeMap实现,红黑树)
import java.util.TreeSet; public class Demo5 { public static void main(String[] args) { TreeSet ts = new TreeSet(); ts.add("ccc"); ts.add("aaa"); ts.add("ddd"); ts.add("bbb"); System.out.println(ts); // [aaa, bbb, ccc, ddd] } }
|
---| Itreable 接口实现该接口可以使用增强for循环 ---| Collection 描述所有集合共性的接口 ---| List接口 有序,可以重复,有角标的集合 ---| ArrayList ---| LinkedList ---| Set接口 无序,不可以重复的集合 ---| HashSet 线程不安全,存取速度快。底层是以hash表实现的。 ---| TreeSet 红-黑树的数据结构,默认对元素进行自然排序(String)。如果比较的时候两个对象返回值为0,那么元素重复。 |
红-黑树
红黑树是一种特定类型的二叉树
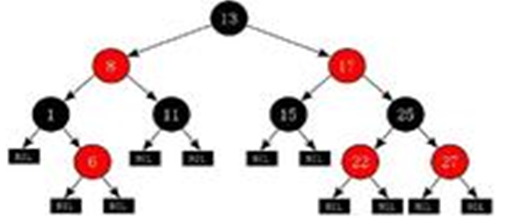
红黑树算法的规则: 左小右大。
既然TreeSet可以自然排序,那么TreeSet必定是有排序规则的。
1:让存入的元素自定义比较规则。
2:给TreeSet指定排序规则。
方式一:元素自身具备比较性
元素自身具备比较性,需要元素实现Comparable接口,重写compareTo方法,也就是让元素自身具备比较性,这种方式叫做元素的自然排序也叫做默认排序。
方式二:容器具备比较性
当元素自身不具备比较性,或者自身具备的比较性不是所需要的。那么此时可以让容器自身具备。需要定义一个类实现接口Comparator,重写compare方法,并将该接口的子类实例对象作为参数传递给TreeMap集合的构造方法。
注意:当Comparable比较方式和Comparator比较方式同时存在时,以Comparator的比较方式为主;
注意:在重写compareTo或者compare方法时,必须要明确比较的主要条件相等时要比较次要条件。(假设姓名和年龄一直的人为相同的人,如果想要对人按照年龄的大小来排序,如果年龄相同的人,需要如何处理?不能直接return 0,因为可能姓名不同(年龄相同姓名不同的人是不同的人)。此时就需要进行次要条件判断(需要判断姓名),只有姓名和年龄同时相等的才可以返回0.)
通过return 0来判断唯一性。
问题:为什么使用TreeSet存入字符串,字符串默认输出是按升序排列的?因为字符串实现了一个接口,叫做Comparable 接口.字符串重写了该接口的compareTo 方法,所以String对象具备了比较性.那么同样道理,我的自定义元素(例如Person类,Book类)想要存入TreeSet集合,就需要实现该接口,也就是要让自定义对象具备比较性.
存入TreeSet集合中的元素要具备比较性.
比较性要实现Comparable接口,重写该接口的compareTo方法
TreeSet属于Set集合,该集合的元素是不能重复的,TreeSet如何保证元素的唯一性
通过compareTo或者compare方法中的来保证元素的唯一性。
添加的元素必须要实现Comparable接口。当compareTo()函数返回值为0时,说明两个对象相等,此时该对象不会添加进来。
比较器接口
|
----| Comparable compareTo(Object o) 元素自身具备比较性 ----| Comparator compare( Object o1, Object o2 ) 给容器传入比较器 |
TreeSet集合排序的两种方式:
一,让元素自身具备比较性。
也就是元素需要实现Comparable接口,覆盖compareTo 方法。
这种方式也作为元素的自然排序,也可称为默认排序。
年龄按照搜要条件,年龄相同再比姓名。
import java.util.TreeSet; public class Demo4 { public static void main(String[] args) { TreeSet ts = new TreeSet(); ts.add(new Person("aa", 20, "男")); ts.add(new Person("bb", 18, "女")); ts.add(new Person("cc", 17, "男")); ts.add(new Person("dd", 17, "女")); ts.add(new Person("dd", 15, "女")); ts.add(new Person("dd", 15, "女")); System.out.println(ts); System.out.println(ts.size()); // 5 } } class Person implements Comparable { private String name; private int age; private String gender; public Person() { } public Person(String name, int age, String gender) { this.name = name; this.age = age; this.gender = gender; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } @Override public int hashCode() { return name.hashCode() + age * 37; } public boolean equals(Object obj) { System.err.println(this + "equals :" + obj); if (!(obj instanceof Person)) { return false; } Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } public String toString() { return "Person [name=" + name + ", age=" + age + ", gender=" + gender + "]"; } @Override public int compareTo(Object obj) { Person p = (Person) obj; System.out.println(this+" compareTo:"+p); if (this.age > p.age) { return 1; } if (this.age < p.age) { return -1; } return this.name.compareTo(p.name); } }
二,让容器自身具备比较性,自定义比较器。
需求:当元素自身不具备比较性,或者元素自身具备的比较性不是所需的。
那么这时只能让容器自身具备。
定义一个类实现Comparator 接口,覆盖compare方法。
并将该接口的子类对象作为参数传递给TreeSet集合的构造函数。
当Comparable比较方式,及Comparator比较方式同时存在,以Comparator
比较方式为主。
import java.util.Comparator; import java.util.TreeSet; public class Demo5 { public static void main(String[] args) { TreeSet ts = new TreeSet(new MyComparator()); ts.add(new Book("think in java", 100)); ts.add(new Book("java 核心技术", 75)); ts.add(new Book("现代操作系统", 50)); ts.add(new Book("java就业教程", 35)); ts.add(new Book("think in java", 100)); ts.add(new Book("ccc in java", 100)); System.out.println(ts); } } class MyComparator implements Comparator { public int compare(Object o1, Object o2) { Book b1 = (Book) o1; Book b2 = (Book) o2; System.out.println(b1+" comparator "+b2); if (b1.getPrice() > b2.getPrice()) { return 1; } if (b1.getPrice() < b2.getPrice()) { return -1; } return b1.getName().compareTo(b2.getName()); } } class Book { private String name; private double price; public Book() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public Book(String name, double price) { this.name = name; this.price = price; } @Override public String toString() { return "Book [name=" + name + ", price=" + price + "]"; } }
2.4.3 LinkedHashSet(内部基于HashMap实现)
会保存插入的顺序。
看到array,就要想到角标。
看到link,就要想到first,last。
看到hash,就要想到hashCode,equals.
看到tree,就要想到两个接口。Comparable,Comparator。
3. Map
如果程序中存储了几百万个学生,而且经常需要使用学号来搜索某个学生,那么这个需求有效的数据结构就是Map。Map是一种依照键(key)存储元素的容器,键(key)很像下标,在List中下标是整数。在Map中键(key)可以使任意类型的对象。Map中不能有重复的键(Key),每个键(key)都有一个对应的值(value)。一个键(key)和它对应的值构成map集合中的一个元素。
Map中的元素是两个对象,一个对象作为键,一个对象作为值。键不可以重复,但是值可以重复。
看顶层共性方法找子类特有对象.
Map与Collection在集合框架中属并列存在
Map存储的是键值对
Map存储元素使用put方法,Collection使用add方法
Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
Map集合中键要保证唯一性
也就是Collection是单列集合, Map 是双列集合。
总结:
Map一次存一对元素, Collection 一次存一个。Map 的键不能重复,保证唯一。
Map 一次存入一对元素,是以键值对的形式存在.键与值存在映射关系.一定要保证键的唯一性.
查看api文档:
interface Map<K,V>
K - 此映射所维护的键的类型
V - 映射值的类型
概念
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
特点
Key和Value是1对1的关系,如:门牌号:家 老公:老婆
双列集合
|
Map学习体系: ---| Map 接口 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。 ---| HashMap 采用哈希表实现,所以无序 ---| TreeMap 可以对健进行排序 |
|
---|Hashtable: 底层是哈希表数据结构,线程是同步的,不可以存入null键,null值。 效率较低,被HashMap 替代。 ---|HashMap: 底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。 要保证键的唯一性,需要覆盖hashCode方法,和equals方法。 ---| LinkedHashMap: 该子类基于哈希表又融入了链表。可以Map集合进行增删提高效率。 ---|TreeMap: 底层是二叉树数据结构。(红黑树)可以对map集合中的键进行排序。需要使用Comparable或者Comparator 进行比较排序。return 0,来判断键的唯一性。 |
常见方法
|
1、添加: 1、V put(K key, V value) (可以相同的key值,但是添加的value值会覆 盖前面的,返回值是前一个,如果没有就返回null) 2、putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关 系复制到此映射中(可选操作)。 2、删除 1、remove() 删除关联对象,指定key对象 2、clear() 清空集合对象 3、获取 1:value get(key); 可以用于判断键是否存在的情况。当指定的键不存在的时候,返 回的是null。
3、判断: 1、boolean isEmpty() 长度为0返回true否则false 2、boolean containsKey(Object key) 判断集合中是否包含指定的key 3、boolean containsValue(Object value) 判断集合中是否包含指定的value 4、长度: Int size()
|
添加:
该案例使用了HashMap,建立了学生姓名和年龄之间的映射关系。并试图添加重复的键。
|
import java.util.HashMap; import java.util.Map;
public class Demo1 { public static void main(String[] args) { // 定义一个Map的容器对象 Map<String, Integer > map1 = new HashMap<String, Integer >(); map1.put("jack", 20); map1.put("rose", 18); map1.put("lucy", 17); map1.put("java", 25); System.out.println(map1); // 添加重复的键值(值不同),会返回集合中原有(重复键)的值, System.out.println(map1.put("jack", 30)); //20
Map<String, Integer> map2 = new HashMap<String, Integer>(); map2.put("张三丰", 100); map2.put("虚竹", 20); System.out.println("map2:" + map2); // 从指定映射中将所有映射关系复制到此映射中。 map1.putAll(map2); System.out.println("map1:" + map1); // } }
|
删除:
|
// 删除: // remove() 删除关联对象,指定key对象 // clear() 清空集合对象
Map<String, Integer> map1 = new HashMap<String, Integer>(); map1.put("jack", 20); map1.put("rose", 18); map1.put("lucy", 17); map1.put("java", 25); System.out.println(map1); // 指定key,返回删除的键值对映射的值。 System.out.println("value:" + map1.remove("java")); map1.clear(); System.out.println("map1:" + map1); |
获取:
|
// 获取: // V get(Object key) 通过指定的key对象获取value对象 // int size() 获取容器的大小 Map<String, Integer> map1 = new HashMap<String, Integer>(); map1.put("jack", 20); map1.put("rose", 18); map1.put("lucy", 17); map1.put("java", 25); System.out.println(map1); // V get(Object key) 通过指定的key对象获取value对象 // int size() 获取容器的大小 System.out.println("value:" + map1.get("jack")); System.out.println("map.size:" + map1.size()); |
判断:
|
// 判断: // boolean isEmpty() 长度为0返回true否则false // boolean containsKey(Object key) 判断集合中是否包含指定的key // boolean containsValue(Object value)
Map<String, Integer> map1 = new HashMap<String, Integer>(); map1.put("jack", 20); map1.put("rose", 18); map1.put("lucy", 17); map1.put("java", 25); System.out.println(map1); System.out.println("isEmpty:" + map1.isEmpty()); System.out.println("containskey:" + map1.containsKey("jack")); System.out.println("containsvalues:" + map1.containsValue(100)); |
遍历Map的方式:
|
1、将map 集合中所有的键取出存入set集合。 Set<K> keySet() 返回所有的key对象的Set集合 再通过get方法获取键对应的值。 2、 values() ,获取所有的值. Collection<V> values()不能获取到key对象 3、 Map.Entry对象 推荐使用 重点 Set<Map.Entry<k,v>> entrySet() 将map 集合中的键值映射关系打包成一个对象 Map.Entry对象通过Map.Entry 对象的getKey, getValue获取其键和值。 |
|
|
第一种方式:使用keySet
将Map转成Set集合(keySet()),通过Set的迭代器取出Set集合中的每一个元素(Iterator)就是Map集合中的所有的键,再通过get方法获取键对应的值。
|
import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set;
public class Demo2 { public static void main(String[] args) { Map<Integer, String> map = new HashMap<Integer, String>(); map.put(1, "aaaa"); map.put(2, "bbbb"); map.put(3, "cccc"); System.out.println(map);
// // 获取方法: // 第一种方式: 使用keySet // 需要分别获取key和value,没有面向对象的思想 // Set<K> keySet() 返回所有的key对象的Set集合
Set<Integer> ks = map.keySet(); Iterator<Integer> it = ks.iterator(); while (it.hasNext()) { Integer key = it.next(); String value = map.get(key); System.out.println("key=" + key + " value=" + value); } } }
|
第二种方式: 通过values 获取所有值,不能获取到key对象
|
public static void main(String[] args) { Map<Integer, String> map = new HashMap<Integer, String>(); map.put(1, "aaaa"); map.put(2, "bbbb"); map.put(3, "cccc"); System.out.println(map); // 第二种方式: // 通过values 获取所有值,不能获取到key对象 // Collection<V> values()
Collection<String> vs = map.values(); Iterator<String> it = vs.iterator(); while (it.hasNext()) { String value = it.next(); System.out.println(" value=" + value); } } |
第三种方式: Map.Entry(重要)
public static interface Map.Entry<K,V>
通过Map中的entrySet()方法获取存放Map.Entry<K,V>对象的Set集合。
Set<Map.Entry<K,V>> entrySet()
面向对象的思想将map集合中的键和值映射关系打包为一个对象,就是Map.Entry,将该对象存入Set集合,Map.Entry是一个对象,那么该对象具备的getKey,getValue获得键和值。
|
public static void main(String[] args) { Map<Integer, String> map = new HashMap<Integer, String>(); map.put(1, "aaaa"); map.put(2, "bbbb"); map.put(3, "cccc"); System.out.println(map); // 第三种方式: Map.Entry对象 推荐使用 重点 // Set<Map.Entry<K,V>> entrySet()
// 返回的Map.Entry对象的Set集合 Map.Entry包含了key和value对象 Set<Map.Entry<Integer, String>> es = map.entrySet();
Iterator<Map.Entry<Integer, String>> it = es.iterator();
while (it.hasNext()) {
// 返回的是封装了key和value对象的Map.Entry对象 Map.Entry<Integer, String> en = it.next();
// 获取Map.Entry对象中封装的key和value对象 Integer key = en.getKey(); String value = en.getValue();
System.out.println("key=" + key + " value=" + value); } } |
1.1. HashMap
底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。要保证键的唯一性,需要覆盖hashCode方法,和equals方法。
案例:自定义对象作为Map的键。
|
package cn.itcast.gz.map;
import java.util.HashMap; import java.util.Iterator; import java.util.Map.Entry; import java.util.Set;
public class Demo3 { public static void main(String[] args) { HashMap<Person, String> hm = new HashMap<Person, String>(); hm.put(new Person("jack", 20), "1001"); hm.put(new Person("rose", 18), "1002"); hm.put(new Person("lucy", 19), "1003"); hm.put(new Person("hmm", 17), "1004"); hm.put(new Person("ll", 25), "1005"); System.out.println(hm); System.out.println(hm.put(new Person("rose", 18), "1006"));
Set<Entry<Person, String>> entrySet = hm.entrySet(); Iterator<Entry<Person, String>> it = entrySet.iterator(); while (it.hasNext()) { Entry<Person, String> next = it.next(); Person key = next.getKey(); String value = next.getValue(); System.out.println(key + " = " + value); } } }
class Person { private String name; private int age;
Person() {
}
public Person(String name, int age) {
this.name = name; this.age = age; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
@Override public int hashCode() {
return this.name.hashCode() + age * 37; }
@Override public boolean equals(Object obj) { if (obj instanceof Person) { Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } else { return false; } }
@Override public String toString() {
return "Person@name:" + this.name + " age:" + this.age; }
} }
|
1.2. TreeMap(红黑树实现---平衡二叉树)
TreeMap的排序,TreeMap可以对集合中的键进行排序。如何实现键的排序?
方式一:元素自身具备比较性
和TreeSet一样原理,需要让存储在键位置的对象实现Comparable接口,重写compareTo方法,也就是让元素自身具备比较性,这种方式叫做元素的自然排序也叫做默认排序。
方式二:容器具备比较性
当元素自身不具备比较性,或者自身具备的比较性不是所需要的。那么此时可以让容器自身具备。需要定义一个类实现接口Comparator,重写compare方法,并将该接口的子类实例对象作为参数传递给TreeMap集合的构造方法。
注意:当Comparable比较方式和Comparator比较方式同时存在时,以Comparator的比较方式为主;
注意:在重写compareTo或者compare方法时,必须要明确比较的主要条件相等时要比较次要条件。(假设姓名和年龄一直的人为相同的人,如果想要对人按照年龄的大小来排序,如果年龄相同的人,需要如何处理?不能直接return 0,以为可能姓名不同(年龄相同姓名不同的人是不同的人)。此时就需要进行次要条件判断(需要判断姓名),只有姓名和年龄同时相等的才可以返回0.)
通过return 0来判断唯一性。
|
import java.util.TreeMap;
public class Demo4 { public static void main(String[] args) { TreeMap<String, Integer> tree = new TreeMap<String, Integer>(); tree.put("张三", 19); tree.put("李四", 20); tree.put("王五", 21); tree.put("赵六", 22); tree.put("周七", 23); tree.put("张三", 24); System.out.println(tree); System.out.println("张三".compareTo("李四"));//-2094 } } |
自定义元素排序
|
package cn.itcast.gz.map;
import java.util.Comparator; import java.util.Iterator; import java.util.Map.Entry; import java.util.Set; import java.util.TreeMap;
public class Demo3 { public static void main(String[] args) { TreeMap<Person, String> hm = new TreeMap<Person, String>( new MyComparator()); hm.put(new Person("jack", 20), "1001"); hm.put(new Person("rose", 18), "1002"); hm.put(new Person("lucy", 19), "1003"); hm.put(new Person("hmm", 17), "1004"); hm.put(new Person("ll", 25), "1005"); System.out.println(hm); System.out.println(hm.put(new Person("rose", 18), "1006"));
Set<Entry<Person, String>> entrySet = hm.entrySet(); Iterator<Entry<Person, String>> it = entrySet.iterator(); while (it.hasNext()) { Entry<Person, String> next = it.next(); Person key = next.getKey(); String value = next.getValue(); System.out.println(key + " = " + value); } } }
class MyComparator implements Comparator<Person> {
@Override public int compare(Person p1, Person p2) { if (p1.getAge() > p2.getAge()) { return -1; } else if (p1.getAge() < p2.getAge()) { return 1; } return p1.getName().compareTo(p2.getName()); }
}
class Person implements Comparable<Person> { private String name; private int age;
Person() {
}
public Person(String name, int age) {
this.name = name; this.age = age; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
@Override public int hashCode() {
return this.name.hashCode() + age * 37; }
@Override public boolean equals(Object obj) { if (obj instanceof Person) { Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } else { return false; } }
@Override public String toString() {
return "Person@name:" + this.name + " age:" + this.age; }
@Override public int compareTo(Person p) {
if (this.age > p.age) { return 1; } else if (this.age < p.age) { return -1; } return this.name.compareTo(p.name); }
} |
注意:
Set的元素不可重复,Map的键不可重复,如果存入重复元素如何处理
Set元素重复元素不能存入add方法返回false
Map的重复健将覆盖旧键,将旧值返回。
4. Collections与Arrays
集合框架中的工具类:特点:该工具类中的方法都是静态的。
Collections:常见方法: 1, 对list进行二分查找: 前提该集合一定要有序。 int binarySearch(list,key); //必须根据元素自然顺序对列表进行升级排序 //要求list 集合中的元素都是Comparable 的子类。 int binarySearch(list,key,Comparator); 2,对list集合进行排序。 sort(list); //对list进行排序,其实使用的事list容器中的对象的compareTo方法 sort(list,comaprator); //按照指定比较器进行排序 3,对集合取最大值或者最小值。 max(Collection) max(Collection,comparator) min(Collection) min(Collection,comparator) 4,对list集合进行反转。 reverse(list); 5,对比较方式进行强行逆转。 Comparator reverseOrder(); Comparator reverseOrder(Comparator); 6,对list集合中的元素进行位置的置换。 swap(list,x,y); 7,对list集合进行元素的替换。如果被替换的元素不存在,那么原集合不变。 replaceAll(list,old,new); 8,可以将不同步的集合变成同步的集合。 Set synchronizedSet(Set<T> s) Map synchronizedMap(Map<K,V> m) List synchronizedList(List<T> list) 9. 如果想要将集合变数组: 可以使用Collection 中的toArray 方法。注意:是Collection不是Collections工具类 传入指定的类型数组即可,该数组的长度最好为集合的size。
Arrays:用于对数组操作的工具类
1,二分查找,数组需要有序 binarySearch(int[]) binarySearch(double[]) 2,数组排序 sort(int[]) sort(char[])…… 1, 将数组变成字符串。 toString(int[]) 2, 复制数组。 copyOf(); 3, 复制部分数组。 copyOfRange(): 4, 比较两个数组是否相同。 equals(int[],int[]); 5, 将数组变成集合。 List asList(T[]); 这样可以通过集合的操作来操作数组中元素, 但是不可以使用增删方法,add,remove。因为数组长度是固定的,会出现 UnsupportOperationExcetion。 可以使用的方法:contains,indexOf。。。 如果数组中存入的基本数据类型,那么asList会将数组实体作为集合中的元素。 如果数组中的存入的引用数据类型,那么asList会将数组中的元素作为集合中 的元素。
import java.util.ArrayList; import java.util.Collections; import java.util.Arrays; import java.util.List; class Demo1 { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<Integer>(); list.add(4); list.add(3); list.add(1); list.add(2); list.add(3); // 排序 Collections.sort(list); // 折半查找的前提是排序好的元素 System.out.println( Collections.binarySearch( list , 8 ) ); // 找不到返回-插入点-1 // 反序集合输出 Collections.reverse( list ); System.out.println( list ); // 求最值 System.out.println( Collections.max( list ) ); // 4 // fill() 使用指定的元素替换指定集合中的所有元素 // Collections.fill( list, 5 ); System.out.println( list ); // 将数组转换为集合 Integer is[] = new Integer[]{6,7,8}; List<Integer> list2 = Arrays.asList(is); list.addAll( list2 ); System.out.println( list ); // 将List转换为数组 Object [] ins = list.toArray(); System.out.println( Arrays.toString( ins ) ); } }
5.关于数组与各种集合之间的相互转换
1.List转换为Array
List<String> list = new ArrayList<String>(); list.add("China"); list.add("Switzerland"); list.add("Italy"); list.add("France"); String [] countries = list.toArray(new String[list.size()]);
2.Array转换为List
String[] countries = {"China", "Switzerland", "Italy", "France"};
List list = Arrays.asList(countries);
3.Map转换为List
List<Value> list = new ArrayList<Value>(map.values());
4.Array转换为Set
String [] countries = {"India", "Switzerland", "Italy"};
Set<String> set = new HashSet<String>(Arrays.asList(countries));
System.out.println(set);
5.Map转换为Set
Map<Integer, String> sourceMap = createMap(); Set<String> targetSet = new HashSet<>(sourceMap.values());
6.List转为Set
List<String> datas = getHibernateTemplate().find(hql); Set result = new HashSet<String>(datas);
补充:
1. modCount到底是干什么的呢(我们经常在修改的时候遇见ConcurrentModificationException的原因)
在ArrayList,LinkedList,HashMap等等的内部实现增,删,改中我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢?
大家发现一个公共特点没有,所有使用modCount属性的全是线程不安全的,这是为什么呢?说明这个玩意肯定和线程安全有关系喽,那有什么关系呢
modCount到底是干什么的呢
在ArrayList,LinkedList,HashMap等等的内部实现增,删,改中我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢?
大家发现一个公共特点没有,所有使用modCount属性的全是线程不安全的,这是为什么呢?说明这个玩意肯定和线程安全有关系喽,那有什么关系呢
private abstract class HashIterator<E> implements Iterator<E> { Entry<K,V> next; // next entry to return int expectedModCount; // For fast-fail int index; // current slot Entry<K,V> current; // current entry HashIterator() { expectedModCount = modCount; if (size > 0) { // advance to first entry Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } } public final boolean hasNext() { return next != null; } final Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); Entry<K,V> e = next; if (e == null) throw new NoSuchElementException(); if ((next = e.next) == null) { Entry[] t = table; while (index < t.length && (next = t[index++]) == null) ; } current = e; return e; } public void remove() { if (current == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); Object k = current.key; current = null; HashMap.this.removeEntryForKey(k); expectedModCount = modCount; } }
由以上代码可以看出,在一个迭代器初始的时候会赋予它调用这个迭代器的对象的mCount,如果在迭代器遍历的过程中,一旦发现这个对象的mcount和迭代器中存储的mcount不一样那就抛异常
好的,下面是这个的完整解释
Fail-Fast 机制
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map:注意到 modCount 声明为 volatile,保证线程之间修改的可见性。
2.关于map中key修改的问题:
想要将map中的key直接全部加上"prefix-",例如:{1=1}变为{prefix-1=1}
1.使用迭代器遍历keySet进行先添加元素后删除元素,报错
package cn.qlq.test.test; import java.util.HashMap; import java.util.Map; import java.util.Set; /** * @Author: qlq * @Description * @Date: 21:12 2018/9/30 */ public class ForTest { private static final String prefix = "prefix-"; public static void main(String[] args) throws InterruptedException { // 原来的Map HashMap<String, Object> oriMap = new HashMap<String, Object>(); oriMap.put("key1", "111"); oriMap.put("key2", "222"); // 2替换map中的key disposeMap(oriMap); System.out.println(oriMap); } /** * 直接处理报错(java.util.ConcurrentModificationException) * * @param oriMap */ private static void disposeMap(HashMap<String, Object> oriMap) { Set<String> strings = oriMap.keySet(); for(String key:strings){ Object o = oriMap.get(key); oriMap.put(prefix+key,o); oriMap.remove(key); } } }
编译后代码:
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by Fernflower decompiler) // package cn.qlq.test.test; import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class ForTest { private static final String prefix = "prefix-"; public ForTest() { } public static void main(String[] args) throws InterruptedException { HashMap<String, Object> oriMap = new HashMap(); oriMap.put("key1", "111"); oriMap.put("key2", "222"); disposeMap(oriMap); System.out.println(oriMap); } private static void disposeMap(HashMap<String, Object> oriMap) { Set<String> strings = oriMap.keySet(); Iterator i$ = strings.iterator(); while(i$.hasNext()) { String key = (String)i$.next(); Object o = oriMap.get(key); oriMap.put("prefix-" + key, o); oriMap.remove(key); } } }
报错:
Exception in thread "main" java.util.ConcurrentModificationException at java.util.HashMap$HashIterator.nextEntry(HashMap.java:922) at java.util.HashMap$KeyIterator.next(HashMap.java:956) at cn.qlq.test.test.ForTest.disposeMap(ForTest.java:32) at cn.qlq.test.test.ForTest.main(ForTest.java:21)
原理:其实第一次是遍历的时候可以删除元素与增加元素,但是第二次就会报错。(也就是map只有一个元素的时候是可以采用这种方法操作)
执行nextEntry()方法的时候会验证 modCount 是否等于 expectedModCount,expectedModCount是一个定值(大小等于map元素个数),当modCount!=expectedModCount的时候会抛出异常,每次对元素进行put操作和remove操作之后modCount +1 ,所以上面一轮遍历之后modCount = 4,而expectedModCount=2所以抛出异常。


2.解决办法:通过借助一个临时map实现此功能(好多功能都可以借助临时变量实现)---此处需要注意引用传递与new Object之后形参与实参分别指向不同的对象
package cn.qlq.test.test; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import java.util.Set; /** * @Author: qlq * @Description * @Date: 21:12 2018/9/30 */ public class ForTest { private static final String prefix = "prefix-"; public static void main(String[] args) throws InterruptedException { // 原来的Map Map<String, Object> oriMap = new HashMap<String, Object>(); oriMap.put("key1", "111"); oriMap.put("key2", "222"); // 2替换map中的key oriMap = disposeMap2(oriMap); System.out.println(oriMap); } /** * 重新创建一个map进行修改(有效,浪费资源) * * @param oriMap */ private static Map disposeMap2(Map<String, Object> oriMap) { Map result = new HashMap(); Set<String> keys = oriMap.keySet(); for (String key : keys) { Object value = oriMap.get(key); result.put("prefix-" + key, value); } return result; } }
结果:
{prefix-key1=111, prefix-key2=222}
此处有点浪费内存,没有找到更好的办法。。。。。。。
3.关于集合中根据Map的某个key合并map的问题:
需求是我们希望根据集合map的某个key相同的进行合并,比如:
[{key2=222, key1=value00}, {key1=value00, key22=key22}, {key02=value02, key1=value01}] 合并为:
[{key2=222, key1=value00, key22=key22}, {key02=value02, key1=value01}]
代码如下:(思路:遍历需要合并的map,内部遍历合并后的map,如果指定key的value相同就将外层map合并到内层,并且进行下层循环,如果内层没找到就将map添加到合并后的map集合中)
package cn.qlq.test; import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; /** * * @author Administrator * */ @SuppressWarnings("all") public class Test2 { public static void main(String[] args) throws InterruptedException { // 原来的Map Map<String, Object> map1 = new HashMap<String, Object>(); map1.put("key1", "value00"); map1.put("key2", "222"); Map<String, Object> map2 = new HashMap<String, Object>(); map2.put("key1", "value00"); map2.put("key22", "key22"); Map<String, Object> map3 = new HashMap<String, Object>(); map3.put("key1", "value01"); map3.put("key02", "value02"); List<Map<String, Object>> list = new ArrayList(); list.add(map1); list.add(map2); list.add(map3); System.out.println(list); list = disposeLise(list); System.out.println(list); } /** * 根据某个字段合并map的算法 * * @param list * @return */ private static List<Map<String, Object>> disposeLise(List<Map<String, Object>> list) { List<Map<String, Object>> result = new ArrayList<>(); outer: for (int i = 0; i < list.size(); i++) { Map map = list.get(i); String str = (String) map.get("key1"); if (result.size() == 0) { Map map2 = new HashMap(); map2.put("key1", str); result.add(map); } inner: for (int j = 0; j < result.size(); j++) { Map<String, Object> map2 = result.get(j); if (str.equals(map2.get("key1"))) { map2.putAll(map); continue outer; } } result.add(map); } return result; } }
4.关于为什么LinkedHashmap是有序的?
其实每个Entry内部维护了一个before和一个after,因此变为有序的。
但是第一个元素和最后一个元素是如何确定的?
先看下面HashMap和LinkedHashMap的结构:
代码:
package cn.xm.exam.test; import java.util.HashMap; import java.util.LinkedHashMap; public class test { public static void main(String[] args) { HashMap map1 = new HashMap<>(); map1.put("张三", 22); map1.put("lisi", 22); map1.put("赵六", 22); map1.put("aldf", 22); System.out.println(map1.keySet()); LinkedHashMap map2 = new LinkedHashMap<>(); map2.put("张三", 22); map2.put("lisi", 22); map2.put("赵六", 22); map2.put("aldf", 22); System.out.println(map2.keySet()); } }
结果:
[aldf, 赵六, 张三, lisi]
[张三, lisi, 赵六, aldf]
Debug查看两个map结构:
map1是普通的hashmap,没什么特殊之处。
aldf和赵六的hash值相等,但是先添加的赵六,最后用aldf占用赵六的bucket,并且赵六自身作为aldf的next元素。满足数组+链表
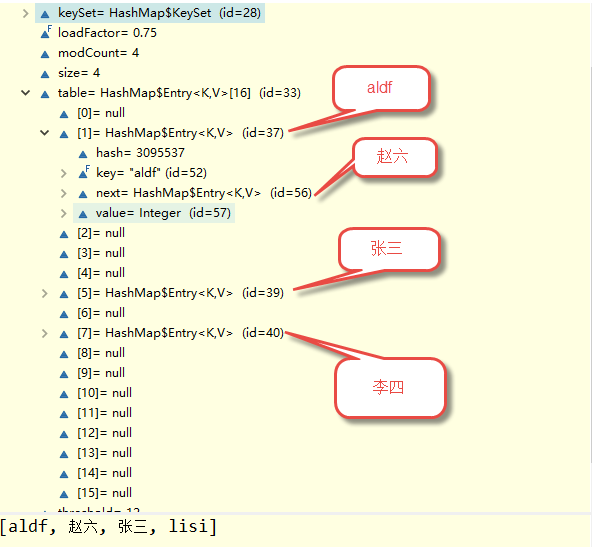
Map2与上面的结构一样,只是内部多维护了一个before和after,所以变为有序的。(JDK7查看的结构)
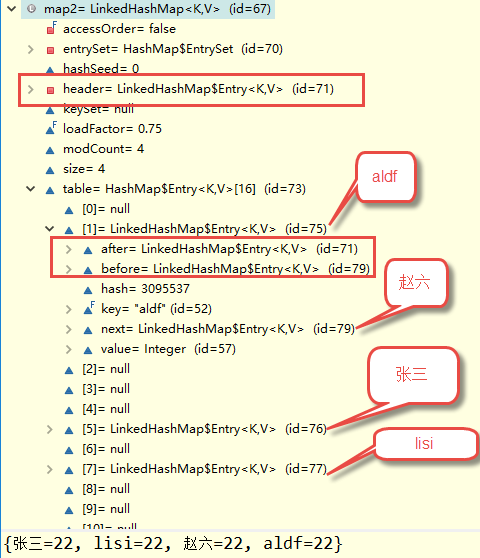
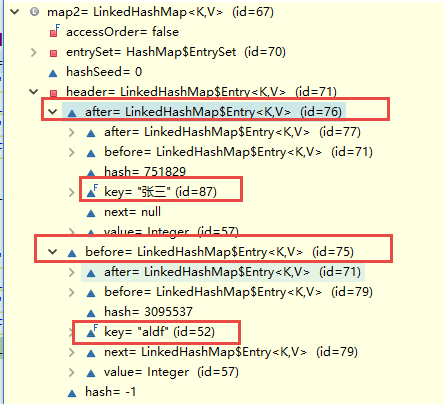
JDK7header元素的after和before分别维护了第一个元素和最后一个元素:
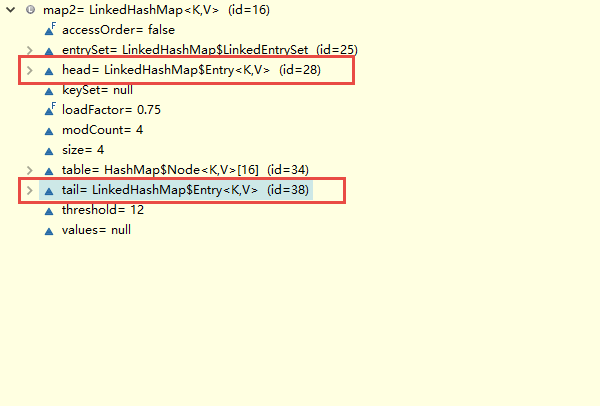
JDK8再次查看LinedHashMap的结构:(其内部有一个head和一个tail,分别记录头元素和尾元素)
补充:高度注意 Map 类集合 K/V 能不能存储 null 值的情况 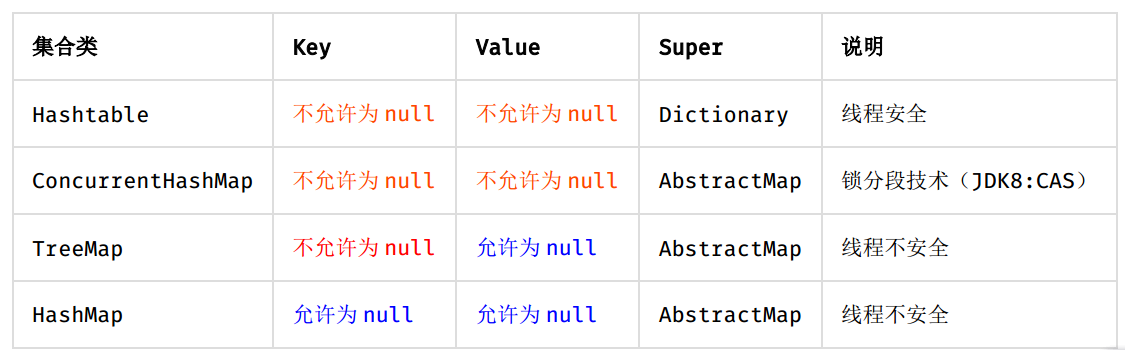
LinkedHashMap继承HashMap,因此两者一样。
补充:基于TreeMap和TreeSet中的元素或者比较器返回0的时候导致元素丢失:
今天遇到一个TreeSet中传入的比较器返回0的情况导致元素丢失,如下:
public class User implements Comparable<User> { private int age; private String username; public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } @Override public int compareTo(User o) { if (o.getAge() < this.age) { return -1; } if (o.getAge() > this.age) { return 1; } return 0; } public User(int age, String username) { super(); this.age = age; this.username = username; } @Override public String toString() { return "User [age=" + age + ", username=" + username + "]"; } }
上面按年龄逆序排序,如果年龄相等返回0不排序。
将User作为TreeMap的key查看,如下
import java.util.Map; import java.util.TreeMap; public class Client { public static void main(String[] args) { Map<Object, Object> map = new TreeMap<>(); User user1 = new User(26, "26"); User user2 = new User(25, "25"); User user3 = new User(27, "27"); User user4 = new User(26, "262"); map.put(user1, 1); map.put(user2, 2); map.put(user3, 3); map.put(user4, 4); System.out.println(map); } }
结果:
{User [age=27, username=27]=3, User [age=26, username=26]=4, User [age=25, username=25]=2}
可以看到虽然存进去4个值,但是两个age为26的值只存了一个,而且是第一个存进去的26,value被替换为第二个26的4.
查看TreeMap的put(K,V)源码:
public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }
可以看到当比较的值返回0的时候是将值进行替换 t.setValue(value)。所以当集合是TreeMap的时候(TreeSet内部也是维护TreeMap)如果比较器返回的是0会替换值,也就造成值丢失。
补充:也可以创建不可变的集合与hash结构
import com.google.common.collect.ImmutableList; import org.apache.commons.collections4.ListUtils; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List; public class PlainTest { public static void main(String[] args) { List<String> fruitsList = new ArrayList<String>(Arrays.asList("Apple", "Orange")); List<String> fruitsUnmodifiableList = Collections.unmodifiableList(fruitsList); System.out.println(fruitsUnmodifiableList.getClass()); fruitsUnmodifiableList.add("Pear"); // apach common工具类 List<String> strings = ListUtils.unmodifiableList(fruitsList); // guava 工具类 ImmutableList<String> strings1 = ImmutableList.copyOf(fruitsList); } }
这里是集合的元素不可以更新,其做法也是返回了一个内部类,内部类重写了相关的更改元素的方法为直接抛异常,如下:
public static <T> List<T> unmodifiableList(List<? extends T> list) { return (list instanceof RandomAccess ? new UnmodifiableRandomAccessList<>(list) : new UnmodifiableList<>(list)); }
java.util.Collections.UnmodifiableList源码如下:
static class UnmodifiableList<E> extends UnmodifiableCollection<E> implements List<E> { private static final long serialVersionUID = -283967356065247728L; final List<? extends E> list; UnmodifiableList(List<? extends E> list) { super(list); this.list = list; } public boolean equals(Object o) {return o == this || list.equals(o);} public int hashCode() {return list.hashCode();} public E get(int index) {return list.get(index);} public E set(int index, E element) { throw new UnsupportedOperationException(); } public void add(int index, E element) { throw new UnsupportedOperationException(); } public E remove(int index) { throw new UnsupportedOperationException(); } public int indexOf(Object o) {return list.indexOf(o);} public int lastIndexOf(Object o) {return list.lastIndexOf(o);} public boolean addAll(int index, Collection<? extends E> c) { throw new UnsupportedOperationException(); } @Override public void replaceAll(UnaryOperator<E> operator) { throw new UnsupportedOperationException(); } @Override public void sort(Comparator<? super E> c) { throw new UnsupportedOperationException(); } public ListIterator<E> listIterator() {return listIterator(0);} public ListIterator<E> listIterator(final int index) { return new ListIterator<E>() { private final ListIterator<? extends E> i = list.listIterator(index); public boolean hasNext() {return i.hasNext();} public E next() {return i.next();} public boolean hasPrevious() {return i.hasPrevious();} public E previous() {return i.previous();} public int nextIndex() {return i.nextIndex();} public int previousIndex() {return i.previousIndex();} public void remove() { throw new UnsupportedOperationException(); } public void set(E e) { throw new UnsupportedOperationException(); } public void add(E e) { throw new UnsupportedOperationException(); } @Override public void forEachRemaining(Consumer<? super E> action) { i.forEachRemaining(action); } }; } public List<E> subList(int fromIndex, int toIndex) { return new UnmodifiableList<>(list.subList(fromIndex, toIndex)); } /** * UnmodifiableRandomAccessList instances are serialized as * UnmodifiableList instances to allow them to be deserialized * in pre-1.4 JREs (which do not have UnmodifiableRandomAccessList). * This method inverts the transformation. As a beneficial * side-effect, it also grafts the RandomAccess marker onto * UnmodifiableList instances that were serialized in pre-1.4 JREs. * * Note: Unfortunately, UnmodifiableRandomAccessList instances * serialized in 1.4.1 and deserialized in 1.4 will become * UnmodifiableList instances, as this method was missing in 1.4. */ private Object readResolve() { return (list instanceof RandomAccess ? new UnmodifiableRandomAccessList<>(list) : this); } }
最后:
关于数据结构可以查看如下网站:
http://www.cs.armstrong.edu/liang/animation/index.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix