Java的Integer常量池和String常量池
1.Integer的常量池
看下面一段代码:
package cn.qlq.test; public class ArrayTest { public static void main(String[] args) { Integer i1 = new Integer(1); Integer i2 = new Integer(1); System.out.println(i1.hashCode()); System.out.println(i2.hashCode()); System.out.println(i1 == i2); System.out.println(i1.equals(i2)); System.out.println("-------------------"); Integer i3 = 1; Integer i4 = 1; System.out.println(i3.hashCode()); System.out.println(i4.hashCode()); System.out.println(i3 == i4); System.out.println(i3.equals(i4)); } }
1
1
false
true
-------------------
1
1
true
true
基本知识:我们知道,如果两个引用指向同一个对象,用==表示它们是相等的。如果两个引用指向不同的对象,用==表示它们是不相等的,即使它们的内容相同。
解释:Integer i1 = new Integer(1)的时候是在Java堆中创建一个Integer对象,i1指向堆中的对象,i1与常量池没关系,所以i1==i2为false。
Integer i3=1;的时候是从常量池中查找值为1的常量,i3指向该常量;Integer i4=1的时候会直接指向该常量,所以 i3 == i4为true。
这就是它有趣的地方了。如果你看去看 Integer.Java 类,你会发现有一个内部私有类,IntegerCache.java,它缓存了从-128到127之间的所有的整数对象。
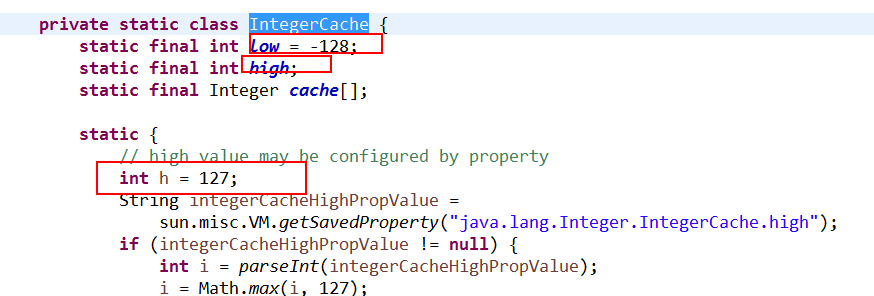
所以事情就成了,所有的小整数在内部缓存,然后当我们声明类似——
Integer bInteger=127;
它实际在内部的操作是:
Integer bInteger=Integer.valueOf(127);
现在,如果我们去看valueOf()方法,我们可以看到:
public static Integer valueOf(int i) { assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
如果值的范围在-128到127之间,它就从高速缓存返回实例。
所以…下面这两个指向同一个对象:
Integer aInteger=127;
Integer bInteger=127;
我们可以得到true。
现在你可能会问,为什么这里需要缓存?
合乎逻辑的理由是,在此范围内的“小”整数使用率比大整数要高,因此,使用相同的底层对象是有价值的,可以减少潜在的内存占用。
然而,通过反射API你会误用此功能。
现在对代码进行反编译和反汇编查看:
package zd.dms.test; public class ArrayTest { public static void main(String[] args) { Integer i1 = 25; Integer i2 = new Integer(26); } }
反编译:
package zd.dms.test; public class ArrayTest { public static void main(String[] paramArrayOfString) { Integer localInteger1 = Integer.valueOf(25); Integer localInteger2 = new Integer(26); } }
反汇编:
C:\Users\Administrator\Desktop>javap -c -v ArrayTest.class Classfile /C:/Users/Administrator/Desktop/ArrayTest.class Last modified 2018-9-3; size 384 bytes MD5 checksum 6535da703ea8fa15da765de7bb03300b Compiled from "ArrayTest.java" public class zd.dms.test.ArrayTest SourceFile: "ArrayTest.java" minor version: 0 major version: 51 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #6.#15 // java/lang/Object."<init>":()V #2 = Methodref #3.#16 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer; #3 = Class #17 // java/lang/Integer #4 = Methodref #3.#18 // java/lang/Integer."<init>":(I)V #5 = Class #19 // zd/dms/test/ArrayTest #6 = Class #20 // java/lang/Object #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 main #12 = Utf8 ([Ljava/lang/String;)V #13 = Utf8 SourceFile #14 = Utf8 ArrayTest.java #15 = NameAndType #7:#8 // "<init>":()V #16 = NameAndType #21:#22 // valueOf:(I)Ljava/lang/Integer; #17 = Utf8 java/lang/Integer #18 = NameAndType #7:#23 // "<init>":(I)V #19 = Utf8 zd/dms/test/ArrayTest #20 = Utf8 java/lang/Object #21 = Utf8 valueOf #22 = Utf8 (I)Ljava/lang/Integer; #23 = Utf8 (I)V { public zd.dms.test.ArrayTest(); flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 3: 0 public static void main(java.lang.String[]); flags: ACC_PUBLIC, ACC_STATIC Code: stack=3, locals=3, args_size=1 0: bipush 25 2: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; 5: astore_1 6: new #3 // class java/lang/Integer 9: dup 10: bipush 26 12: invokespecial #4 // Method java/lang/Integer."<init>":(I)V 15: astore_2 16: return LineNumberTable: line 6: 0 line 7: 6 line 8: 16 }
bipush 25 将25推至栈顶
invokestatic 调用Integer的静态方法valueOf(int)方法
astore_1 将栈顶引用型数值存入第二个本地变量
new 调用new Integer(int)
dup 复制栈顶数值(数值不能是long或double类型的)并将复制值压入栈顶
bipush 26 将26推至栈顶
invokespecial 调用Integer的初始化方法(init)
astore_2 将栈顶引用型数值存入第三个本地变量
return 返回,类型是void
补充:
aload_0 //将this引用推送至栈顶,即压入栈。
总结:Integer i = value;如果i是在-128到127之间,不会去堆中创建对象,而是直接返回IntegerCache中的值;如果值不在上面范围内则会从堆中创建对象。= 走的是valueOf()方法,valueOf(int)会走缓存。
Integer i2 = new Integer(xxxx);不管参数的value是多少都会从堆中创建对象,与IntegerCache没关系。
2.String常量池问题:
package cn.qlq.test; public class ArrayTest { public static void main(String[] args) { String s1 = new String("1"); String s2 = new String("1"); System.out.println(s1.hashCode());// 49 System.out.println(s2.hashCode());// 49 System.out.println(s1 == s2);// false System.out.println(s1.equals(s2));// true System.out.println("-------------------"); String s3 = "1"; String s4 = "1"; System.out.println(s3 == s4);// true System.out.println(s3.equals(s4));// true System.out.println(s3.hashCode());// 49 System.out.println(s4.hashCode());// 49 } }
String的hashCode不是返回地址,是对其值进行遍历运算。与地址没关系,只对值计算,所以所有的hashCode一样。
String s1 = new String("1"); 是在堆中创建一个String对象,并检查常量池中是否有字面量为"1"的常量,没有的话在常量区创建"1"并将堆中的对象指向该常量,有的话堆中的对象直接指向"1";
String s2 = new String("1"); 又在堆中创建一个String对象,并将s2指向该对象,其字面量"1"在前面已经创建,所以不会再创建常量区中创建字符串;
String s3 = "1"; 检查常量池中有没有字面量为"1"的字符串,如果没有则创建并将s3指向该常量;有的话直接指向该该常量;
String s4 = "1" 的时候常量池已经有1,所以不会再创建对象,也就是s3与s4指向同一个对象。
所以我们可以用下面图解解释,String s = new String("xxx")在检查常量池的时候会涉及到堆中创建对象;String s = "x"直接检查常量池,不会涉及堆。
如下图解:

一道经典的面试题:new String("abc")创建几个对象?
简单的回答是一个或者两个,如果是常量区有值为"abc"的值,则只在堆中创建一个对象;如果常量区没有则会在常量区创建"abc",此处的常量区是方法区的运行时常量池(也称为动态常量区)。
我们需要明白只要是new都会在堆中创建对象。直接String s = "xxx"不会涉及堆,只在常量区检查是否有该常量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号