【Mysql优化】索引优化策略
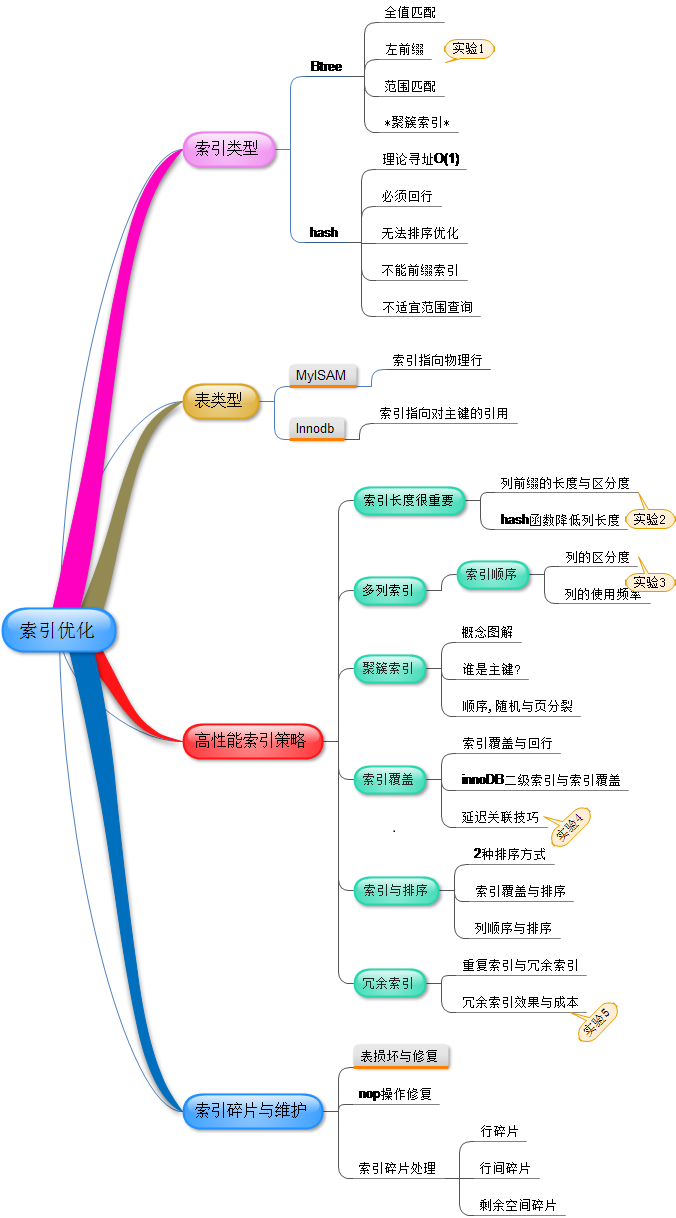
1:索引类型
1.1 B-tree索引
注: 名叫btree索引,大的方面看,都用的平衡树,但具体的实现上, 各引擎稍有不同,
比如,严格的说,NDB引擎,使用的是T-tree
Myisam,innodb中,默认用B-tree索引
但抽象一下---B-tree系统,可理解为”排好序的快速查找结构”. (排好序特别有利于范围查询)
1.2 hash索引
在memory表里,默认是hash索引, hash的理论查询时间复杂度为O(1)
解释:任意给定一行数据一次性就能在数据库中找到。
疑问: 既然hash的查找如此高效,为什么不都用hash索引?
答:

1:hash函数计算后的结果,是随机的,如果是在磁盘上放置数据, 以主键为id为例, 那么随着id的增长, id对应的行,在磁盘上随机放置. 2: 无法对范围查询进行优化. 3: 无法利用前缀索引. 比如 在btree中, field列的值“hellopworld”,并加索引 查询 xx=helloword,自然可以利用索引, xx=hello,也可以利用索引. (左前缀索引) 因为hash(‘helloword’),和hash(‘hello’),两者的关系仍为随机 4: 排序也无法优化. 5: 必须回行.就是说 通过索引拿到数据位置,必须回到表中取数据
2: btree索引的常见误区
2.1 在where条件常用的列上都加上索引
例: where cat_id=3 and price>100 ; //查询第3个栏目,100元以上的商品
误: cat_id上,和, price上都加上索引.
错: 只能用上cat_id或Price索引,因为是独立的索引,同时只能用上1个.
2.2 在多列上建立索引后,查询哪个列,索引都将发挥作用
误: 多列索引上,索引发挥作用,需要满足左前缀要求.,既然是索引,必须是准确定位的时候索引才能使用,如果是范围查询的话查出来一大片,所以后面的索引不能发挥作用。
也就是按索引建立的顺序判断,如果前一个索引能准确的定位到一个点才能发生作用,否则后面的索引不会发生作用。
以 index(a,b,c) 为例:
|
语句 |
索引是否发挥作用 |
|
Where a=3 |
是,只使用了a列 |
|
Where a=3 and b=5 |
是,使用了a,b列 |
|
Where a=3 and b=5 and c=4 |
是,使用了abc |
|
Where b=3 / where c=4 |
否 |
|
Where a=3 and c=4 |
a列能发挥索引,c不能 |
|
Where a=3 and b>10 and c=7 |
A能利用,b能利用, C不能利用 |
|
同上,where a=3 and b like ‘xxxx%’ and c=7 |
A能用,B能用,C不能用 |
可以理解为下图:
索引是按照索引定义的顺序来进行使用,也就是右边的索引使用的前提是左边的索引查询必须使用等号(能唯一确定一个值),如果是>,<或者like 'xxx'的话找到的是一个区间,所以后面的索引无法使用。

为便于理解, 假设ABC各10米长的木板, 河面宽30米.
全值索引则木板长10米(使用=则木板长十米)
Like,左前缀及范围查询, 则木板长6米(使用范围查询相当于将模板截断)

自己拼接一下,能否过河对岸,就知道索引能否利用上.
如上例中, where a=3 and b>10, and c=7,
A 板长10米,A列索引发挥作用
A板正常接B板, B板索引发挥作用
B板短了,接不到C板, C列的索引不发挥作用.
思考题:假设某个表有一个联合索引(c1,c2,c3,c4)一下——只能使用该联合索引的c1,c2,c3部分
A where c1=x and c2=x and c4>x and c3=x c1,c2,c3,c4都用上了(mysql会在不影响语义的情况下将语句优化可以理解为where c1=x and c2=x and c3=x and c4>x)
B where c1=x and c2=x and c4=x order by c3
C where c1=x and c4= x group by c3,c2
D where c1=x and c5=x order by c2,c3
E where c1=x and c2=x and c5=? order by c2,c3
多列索引测试解决上面问题:
CREATE TABLE t5 ( c1 CHAR(1) NOT NULL DEFAULT 'a', c2 CHAR(1) NOT NULL DEFAULT 'b', c3 CHAR(1) NOT NULL DEFAULT 'c', c4 CHAR(1) NOT NULL DEFAULT 'd', c5 CHAR(1) NOT NULL DEFAULT 'e', INDEX c1234(c1,c2,c3,c4) );
3行数据:
mysql> select * from t5; +----+----+----+----+----+ | c1 | c2 | c3 | c4 | c5 | +----+----+----+----+----+ | A | B | C | D | E | | a | A | C | D | E | | b | b | c | d | e | +----+----+----+----+----+ 3 rows in set (0.00 sec)
A选项验证:(4列索引都用上)
mysql> explain select * from t5 where c1='a' and c2='b' and c4>'D' and c3='c' \ G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: range possible_keys: c1234 key: c1234 key_len: 12 ref: NULL rows: 1 filtered: 100.00 Extra: Using index condition 1 row in set, 1 warning (0.00 sec)
B选项验证:(c1 c2使用索引,c3在c2确定的情况下本身是有序的,所以使用了c3索引进行排序,总的是c1,c2使用了索引。)
mysql> explain select * from t5 where c1='a' and c2='b' and c4='d' order by c3 \ G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 6 ref: const,const rows: 1 filtered: 33.33 Extra: Using index condition 1 row in set, 1 warning (0.00 sec)
将B选项改成按c5排序:(Extra: Using index condition; Using filesort(#表示文件排序, 表明取出来数据之后又在磁盘上进行了排序,上面是利用了c3索引(因为c3就是有序的))
mysql> explain select * from t5 where c1='a' and c2='b' and c4='d' order by c5 \ G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 6 ref: const,const rows: 1 filtered: 33.33 Extra: Using index condition; Using filesort 1 row in set, 1 warning (0.00 sec)
C选项验证:where c1=x and c4= x group by c3,c2
一般而言,分组统计首先是按分组字段有序排列(这里的一般是指不使用索引的情况。使用临时表进行排序)
mysql> explain select * from t5 where c1='a' and c4='d' group by c3,c2\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 33.33 Extra: Using index condition; Using temporary; Using filesort #表示使用临时表排序,且使用文件排序 1 row in set, 1 warning (0.00 sec)
将上面的分组按c2,c3验证(首先按c2,c3排序,由于c1使用索引,且c2,c3有序,因此不会使用临时表,也不会使用文件排序)
mysql> explain select * from t5 where c1='a' and c4='d' group by c2,c3\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 33.33 Extra: Using index condition 1 row in set, 1 warning (0.00 sec)
D选项验证:(c1使用了索引,由于c1下面的c2有序,c2下面的c3有序,所以使用c2,c3的索引进行排序,总的来说c1使用了索引)
mysql> explain select * from t5 where c1='a' and c5='e' order by c2,c3\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 33.33 Extra: Using index condition; Using where 1 row in set, 1 warning (0.00 sec)
将上面排序条件换为c3,c2之后验证:(先按c3,再按c2排序,所以取出来之后需要在磁盘排序)
mysql> explain select * from t5 where c1='a' and c5='e' order by c3,c2\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 33.33 Extra: Using index condition; Using where; Using filesort 1 row in set, 1 warning (0.00 sec)
E选项验证:(此处c2='b'后面按c2排序,可以将c2看为一个常量,也就不影响c3的索引,所以使用c3索引排序,前面使用了c1,c2索引)
等价于 select * from t5 where c1='a' and c2='b' and c5='e' order by c3 (因为c2是一个常量,因为c2的值既是固定的,参与排序时并不考虑)
mysql> explain select * from t5 where c1='a' and c2='b' and c5='e' order by c2,c 3 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 6 ref: const,const rows: 1 filtered: 33.33 Extra: Using index condition; Using where 1 row in set, 1 warning (0.00 sec)
至此上面的题目解决。
一道面试题:
有商品表, 有主键,goods_id, 栏目列 cat_id, 价格price
说:在价格列上已经加了索引,但按价格查询还是很慢,
问可能是什么原因,怎么解决?
答: 在实际场景中,一个电商网站的商品分类很多,直接在所有商品中,按价格查商品,是极少的,一般客户都来到分类下,然后再查.
改正: 去掉单独的Price列的索引, 加 (cat_id,price)复合索引
再查询.
高性能索引策略
理想的索引
1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
0:对于innodb而言,因为节点下有数据文件,因此节点的分裂将会比较慢.
对于innodb的主键,尽量用整型,而且是递增的整型.
如果是无规律的数据,将会产生的页的分裂,影响速度.
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
2:对于左前缀不易区分的列 ,建立索引的技巧
如 url列
http://www.baidu.com
http://www.zixue.it
列的前11个字符都是一样的,不易区分, 可以用如下2个办法来解决
1: 把列内容倒过来存储,并建立索引
Moc.udiab.www//:ptth
Ti.euxiz.www//://ptth
这样左前缀区分度大,
2: 伪hash索引效果
同时存 url_hash列
3:多列索引
3.1 多列索引的考虑因素---
列的查询频率 , 列的区分度,
Show profiles; 查看效率:
| 18 | 0.00183800 | select * from it_area where name like '%东山%' | 20 | 0.00169300 | select a.* from it_area as a inner join (select id from it_area where name like '%东山%') as t on a.id=t.id |
发现 第2种做法,虽然语句复杂,但速度却稍占优势.
第2种做法中, 内层查询,只沿着name索引层顺序走, name索引层包含了id值的.
所以,走完索引层之后,找到所有合适的id,
再通过join, 用id一次性查出所有列. 走完name列再取.
第1种做法: 沿着name的索引文件走, 走到满足的条件的索引,就取出其id,并通过id去取数据, 边走边取.
通过id查找行的过程被延后了. --- 这种技巧,称为”延迟关联”.
使用crc32()函数构造伪哈希效果,当然md5()也可以
crc32类似于md5,和sha-1,是一种加密算法:参考:http://www.cnblogs.com/qlqwjy/p/8594271.html 对于相同的数据采用加密算法后取得的结果相同:
mysql> select crc32('3'); +------------+ | crc32('3') | +------------+ | 1842515611 | +------------+ 1 row in set (0.00 sec)
简单说,crc32是将利用数据产生一个无符号的整数。
创建表:
CREATE TABLE t7( id INT AUTO_INCREMENT PRIMARY KEY, url VARCHAR(40), crcurl INT UNSIGNED NOT NULL DEFAULT 0);
插入三条数据:
mysql> insert into t7(url) values('http://www.baidu.com'); Query OK, 1 row affected (0.10 sec) mysql> insert into t7(url) values('http://www.zixue.com'); Query OK, 1 row affected (0.10 sec) mysql> insert into t7(url) values('http://www.qlq.com'); Query OK, 1 row affected (0.19 sec) mysql> update t7 set crcurl = crc32(url); Query OK, 3 rows affected (0.22 sec) Rows matched: 3 Changed: 3 Warnings: 0 mysql> select * from t7; +----+----------------------+------------+ | id | url | crcurl | +----+----------------------+------------+ | 7 | http://www.baidu.com | 3500265894 | | 9 | http://www.zixue.com | 2107636668 | | 11 | http://www.qlq.com | 2605661224 | +----+----------------------+------------+ 3 rows in set (0.00 sec)
对url与crcurl分别建立添加索引:
mysql> alter table t7 add index url(url(15)); Query OK, 0 rows affected (0.51 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table t7 add index crcurl(crcurl); Query OK, 0 rows affected (0.43 sec) Records: 0 Duplicates: 0 Warnings: 0
分析根据url查询百度的信息,查看索引的长度:
mysql> explain select * from t7 where url='http://www.baidu.com'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t7 partitions: NULL type: ref possible_keys: url key: url key_len: 48 ref: const rows: 1 filtered: 100.00 Extra: Using where 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t7 where crcurl=crc32('http://www.baidu.com')\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t7 partitions: NULL type: ref possible_keys: crcurl key: crcurl key_len: 4 ref: const rows: 1 filtered: 100.00 Extra: NULL 1 row in set, 1 warning (0.00 sec)
所以,上面的方法可以说是将对一列的索引转化为另一列,最好使用整型(长度短,节约空间)。利用一定的算法将相似度较高的数据存到另一列并添加索引。
1.一道面试题:
对于一个索引,不想截取一半又想有较高的相似度的做法是什么?
可以这样回答:将此列利用crc32计算后新添加一列,并对此列添加索引。查询的时候利用crc32对数据处理后与此列对比。将索引转义到另一列上。
索引长度的确定:
针对列中的值,从左往右截取部分,来建索引(索引长度是针对指定的列的前几位建立索引)
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
比如:
mysql> select c1 from t6; +--------------+ | c1 | +--------------+ | 我们是中国人 | | 我是中国人 | | 我们都是好人 | | 我们不是人 | | 你是好人 | | 你们都是人 |
(1)如果我们对c1建立长度为1的索引
分析: 索引值有(我,你),这样对于我字查询的时候利用索引会查出4条数据,区分度不搞,例如: 用 where c1="我们都是中国人",将会用我字去查询索引,查我字查出4条记录,所以索引度不高
(2)如果我们对c1建立长度为6的索引
分析: 上面6条数据都会建立索引,所以利用=查询的时候区分度就是1,但是索引长度长的话占用内存大,增删改查会比较慢。
所以, 我们要在 区分度 + 长度 两者上,取得一个平衡.
惯用手法: 截取不同长度,并测试其区分度,
所以, 我们要在 区分度 + 长度 两者上,取得一个平衡.
惯用手法: 截取不同长度,并测试其区分度,区分度的计算方法就是索引个数除以数据总数。而索引的个数就是对添加索引的列截取索引长度之后,看有多少个不同的值。
如下:计算区分度的简单计算:
mysql> select count(distinct left(word,6))/count(*) from dict; +---------------------------------------+ | count(distinct left(word,6))/count(*) | +---------------------------------------+ | 0.9992 | +---------------------------------------+ 1 row in set (0.30 sec)
对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
总结: BTree索引必须遵循左前缀匹配,且必须使用=进行查询,也就是精确到一个值
1.BTree索引相当于是有序的排列,where查询的时候会根据对应的顺序位置去利用索引进行查询
2.多列索引中索引的使用规则遵循左前缀匹配原则,也就是一个索引能不能用上关键看其上一个索引能不能精确的定位(使用"="查询的可以精确,使用区间查询和模糊查询不能精确)
3.索引对于排序的作用:排序的字段能否使用上索引是看其前面的查询数据能不能精确的定位到一个值,如果其前面的索引都是使用等号查询,则索引会用于排序,如果索引不能用于排序则会使用文件排序,也就是在磁盘上进行排序。
例如:对于上面的index(c1,c2,c3,c4)
mysql> explain select * from t5 where c1='a' order by c2,c3\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 100.00 Extra: Using index condition #由于c1使用了索引,c1下的c2是有序的,c2下的c3是有序的,索引排序的时候会根据c2的顺序不停的扫描c2下的c3,也就是c2,c3索引用于排序 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t5 where c1='a' order by c3\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t5 partitions: NULL type: ref possible_keys: c1234 key: c1234 key_len: 3 ref: const rows: 2 filtered: 100.00 Extra: Using index condition; Using filesort #由于c1使用了索引,但是没有使用c2,所以c2,c3索引不能用于排序,也就需要文件排序(磁盘中进行)
1 row in set, 1 warning (0.00 sec)
4.索引对于分组的作用:首先明白分组的时候是先按分组的字段进行排序,然后值相同的才属于同一个组,所以索引对于分组的作用类似于对排序的作用。
5.查看一个表的索引:
mysql> show index from tblname; mysql> show keys from tblname;
例如:
mysql> show keys from t5\G *************************** 1. row *************************** Table: t5 Non_unique: 1 Key_name: c1234 Seq_in_index: 1 Column_name: c1 Collation: A Cardinality: 1 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 2. row *************************** Table: t5 Non_unique: 1 Key_name: c1234 Seq_in_index: 2 Column_name: c2 Collation: A Cardinality: 1 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 3. row *************************** Table: t5 Non_unique: 1 Key_name: c1234 Seq_in_index: 3 Column_name: c3 Collation: A Cardinality: 1 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 4. row *************************** Table: t5 Non_unique: 1 Key_name: c1234 Seq_in_index: 4 Column_name: c4 Collation: A Cardinality: 1 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: 4 rows in set (0.00 sec)
理想的索引
1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
补充一个小知识点:
如果是用like '数学%' --这种模糊查询的是可以走范围索引的
如果开头有%号是不走索引的


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix