分布式与集群的区别是什么?
分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示:

这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。
有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance、DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。这样 看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,可以由以下模块组成:
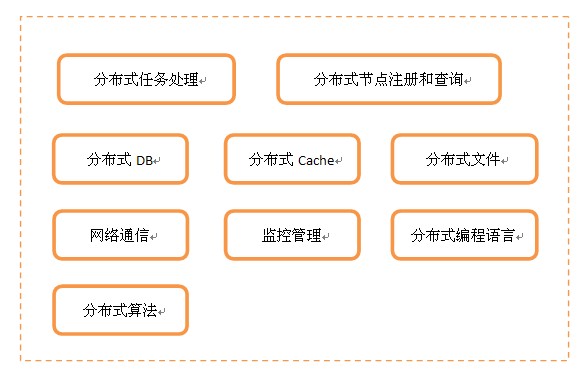
分布式任务处理服务:负责具体的业务逻辑处理
分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁
分布式DB:分布式结构化数据存取
分布式Cache:分布式缓存数据(非持久化)存取
分布式文件:分布式文件存取
网络通信:节点之间的网络数据通信
监控管理:搜集、监控和诊断所有节点运行状态
分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非常好的,可以以此为线索,探索计算机世界的各个角落。
只要是一堆机器,就可以叫集群,他们是不是一起协作着干活,这个谁也不知道;一个程序或系统,只要运行在不同的机器上,就可以叫分布式,嗯,C/S架构也可以叫分布式。
集群一般是物理集中、统一管理的,而分布式系统则不强调这一点。
所以,集群可能运行着一个或多个分布式系统,也可能根本没有运行分布式系统;分布式系统可能运行在一个集群上,也可能运行在不属于一个集群的多台(2台也算多台)机器上。
集群就是逻辑上处理同一任务的机器集合,可以属于同一机房,也可分属不同的机房。分布式这个概念可以运行在某个集群里面,某个集群也可作为分布式概念的一个节点。
一句话,就是:“分头做事”与“一堆人”的区别
分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
2:简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
例如:
如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行该任务需10小时。
采用分布式方案,提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。(这种工作模式的一个典型代表就是Hadoop的Map/Reduce分布式计算模型)
而采用集群方案,同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,1小时后,10个任务同时完成,这样,整身来看,还是1小时内完成一个任务!
集群一般被分为三种类型,高可用集群如RHCS、LifeKeeper等,负载均衡集群如LVS等、高性能运算集群;分布式应该是高性能运算集群范畴内。
集群:同一个业务部署在多台机器上,提高系统可用性
小饭店原来只有一个厨师,切菜洗菜备料炒菜全干。后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关 系是集群。为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,一个配菜师也忙不过来了,又请了个配菜 师,两个配菜师关系是集群


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了