nebula简单使用以及安装
参考:
https://docs.nebula-graph.io/3.2.0/
https://docs.nebula-graph.com.cn/3.2.0/
1. 安裝nebula
查看linux 发行版:
[root@XXX insurance]# cat /etc/system-release
Red Hat Enterprise Linux Server release 7.2 (Maipo)
下载安装包:
wget https://oss-cdn.nebula-graph.io/package/3.2.0/nebula-graph-3.2.1.el7.x86_64.rpm
安装:
sudo rpm -ivh nebula-graph-3.2.1.el7.x86_64.rpm
也可以指定安装路径:如不设置,系统会将 NebulaGraph 安装到默认路径/usr/local/nebula/
sudo rpm -ivh --prefix=<installation_path> <package_name>
启动:
[root@xxx insurance]# sudo /usr/local/nebula/scripts/nebula.service start all
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done
[root@xxx insurance]# ps -ef | grep nebula
root 10645 1 5 13:53 ? 00:00:00 /usr/local/nebula/bin/nebula-metad --flagfile /usr/local/nebula/etc/nebula-metad.conf
root 10720 1 1 13:53 ? 00:00:00 /usr/local/nebula/bin/nebula-graphd --flagfile /usr/local/nebula/etc/nebula-graphd.conf
root 10753 1 36 13:53 ? 00:00:02 /usr/local/nebula/bin/nebula-storaged --flagfile /usr/local/nebula/etc/nebula-storaged.conf
root 11034 4920 0 13:53 pts/0 00:00:00 grep --color=auto nebula
查看状态:(如果多次安装可能会端口占用等问题,卸载掉杀掉对应进程就可以了)
[root@xxx insurance]# sudo /usr/local/nebula/scripts/nebula.service status all
[INFO] nebula-metad: Running as 10645, Listening on 9559
[INFO] nebula-graphd: Running as 10720, Listening on 9669
[INFO] nebula-storaged: Running as 10753, Listening on 9779
2. 安装studio
see: https://docs.nebula-graph.io/3.2.0/nebula-studio/deploy-connect/st-ug-deploy/
console 命令行工具安装报错,暂时不做研究。可视化管理, 类似于neo4j 的web 界面。
1. 下载rpm包
2. rpm -i xxx.rpm
[root@xxx insurance]# rpm -i nebula-graph-studio-3.4.1.x86_64.rpm
Start installing Nebula Studio now...
Nebula Studio has been installed.
Created symlink from /etc/systemd/system/multi-user.target.wants/nebula-graph-studio.service to /usr/lib/systemd/system/nebula-graph-studio.service.
Nebula Studio started automatically.
安装会自动注册服务,可以用systemctl 进行查看:
systemctl status nebula-graph-studio.service
lsof -i:7001
默认是启动的7001端口, 好像是node 启动的一个服务。
连接成功需要添加主机到集群中:(成功之后才可以进行读写数据到storage)
# 添加
ADD HOSTS 127.0.0.1:9779
# 查看
SHOW HOSTS
# 删除
DROP HOSTS 127.0.0.1:9779
3. 简单使用
一个 NebulaGraph 实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。
为了在图空间中插入数据,需要为图数据库定义一个 Schema。NebulaGraph 的 Schema 是由如下几部分组成。
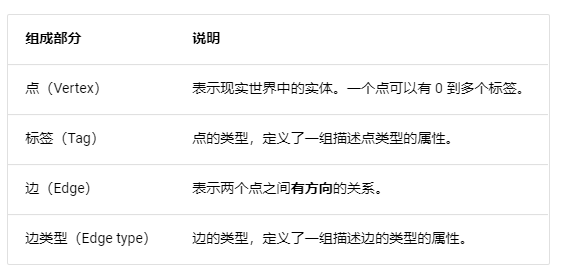
构造如下数据:

NebulaGraph 中执行如下创建和修改操作,是异步实现的。要在下一个心跳周期之后才能生效,否则访问会报错。为确保数据同步,后续操作能顺利进行,请等待 2 个心跳周期(20 秒)。
1. 创建图space
语法:
CREATE SPACE [IF NOT EXISTS] <graph_space_name> (
[partition_num = <partition_number>,]
[replica_factor = <replica_number>,]
vid_type = {FIXED_STRING(<N>) | INT64}
)
[COMMENT = '<comment>'];
自己测试:
CREATE SPACE qlq_test (vid_type = FIXED_STRING(30))
SHOW SPACES;
use qlq_test;
每个图空间在data 目录都有一个文件夹,图空间之间的数据是隔离的。
[root@xxx nebula]# pwd
/usr/local/nebula/data/storage/nebula
[root@xxx nebula]# ll
total 0
drwxr-xr-x 4 root root 27 Jun 25 2021 1
drwxr-xr-x 4 root root 27 Jun 25 2021 2
drwxr-xr-x 4 root root 27 Sep 27 15:31 8
drwxr-xr-x 4 root root 27 Sep 27 15:40 9
2. 创建Tag和EdgeType
语法:
CREATE {TAG | EDGE} [IF NOT EXISTS] {<tag_name> | <edge_type_name>}
(
<prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];
例如:
创建 Tag:player和team,以及 Edge type:follow和serve。说明如下表

CREATE TAG player(name string, age int);
CREATE TAG team(name string);
CREATE EDGE follow(degree int);
CREATE EDGE serve(start_year int, end_year int);
3. 插入点和边
1. 插入语法
- 点
INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...]
VALUES <vid>: ([prop_value_list])
tag_props:
tag_name ([prop_name_list])
prop_name_list:
[prop_name [, prop_name] ...]
prop_value_list:
[prop_value [, prop_value] ...]
- 边
INSERT EDGE [IF NOT EXISTS] <edge_type> ( <prop_name_list> ) VALUES
<src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> )
[, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...];
<prop_name_list> ::=
[ <prop_name> [, <prop_name> ] ...]
<prop_value_list> ::=
[ <prop_value> [, <prop_value> ] ...]
2. 插入
INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
最终构造的关系入图:

3. 查询
0. 查看版本
show hosts graph
1. 查询点和边类型
SHOW SPACES;
SHOW TAGS;
SHOW EDGES;
2. 简单的查询
这种查询不需要索引,但是必须加limit 限制返回的数量。
- 找点
按tag匹配:
match (a:player) return a limit 10
也可以查询所有的:
MATCH (v)
RETURN v
LIMIT 30;
根据属性匹配:
# 根据name 属性查找
MATCH (v:player{name: "Tim"})
RETURN v
LIMIT 30;
# 也可以用下面
MATCH (v:player)
where v.player.name == "Tony Parker"
RETURN v
LIMIT 30
# 模糊匹配
MATCH (v:player) where v.player.name contains "im" RETURN v LIMIT 30;
根据点ID查找:(也可以 IN ["player101", "player102"] 批量查找)
MATCH (v) WHERE id(v) == 'player101' RETURN v
- 找边
# 匹配边可以不创建索引,但需要使用 LIMIT 限制输出结果数量,并且必须指定边的方向
MATCH ()<-[e]-() RETURN e LIMIT 10
# 匹配边类型
MATCH ()<-[e:follow]-() RETURN e LIMIT 10
# 匹配多种类型的边
MATCH (v:player)-[e:follow|:serve]->(v2) RETURN e;
# 匹配边属性
MATCH ()<-[e:follow{degree:96}]-() RETURN e LIMIT 10
# 根据Tag 查找表
MATCH r=(v:player)--(v2:player) RETURN r
# 匹配带方向的点
MATCH r=(v:player)-->(v2:player) RETURN r
3.一些组合查询
- 从 VID 为player101的球员开始,沿着边follow找到连接的球员
nebula> GO FROM "player101" OVER follow YIELD id($$);
+-------------+
| id($$) |
+-------------+
| "player100" |
| "player102" |
+-------------+

- 从 VID 为
player101的球员开始,沿着边follow查找年龄大于或等于 35 岁的球员,并返回他们的姓名和年龄,同时重命名对应的列。
nebula> GO FROM "player101" OVER follow WHERE properties($$).age >= 35 \
YIELD properties($$).name AS Teammate, properties($$).age AS Age;
+-----------------+-----+
| Teammate | Age |
+-----------------+-----+
| "Tim Duncan" | 42 |
+-----------------+-----+
- 从 VID 为
player101的球员开始,沿着边follow查找连接的球员,然后检索这些球员的球队。为了合并这两个查询请求,可以使用管道符或临时变量。
# 使用管道符
nebula> GO FROM "player101" OVER follow YIELD dst(edge) AS id | \
GO FROM $-.id OVER serve YIELD properties($$).name AS Team, \
properties($^).name AS Player;
# 使用临时变量
nebula> $var = GO FROM "player101" OVER follow YIELD dst(edge) AS id; \
GO FROM $var.id OVER serve YIELD properties($$).name AS Team, \
properties($^).name AS Player;

- 查询 VID 为player100的球员的属性。
nebula> FETCH PROP ON player "player100" YIELD properties(vertex);
+-------------------------------+
| properties(VERTEX) |
+-------------------------------+
| {age: 42, name: "Tim Duncan"} |
+-------------------------------+
4. 索引相关
# 在 Tag player 的 name 属性和 Edge type follow 上创建索引。
CREATE TAG INDEX IF NOT EXISTS name ON player(name(20))
CREATE EDGE INDEX IF NOT EXISTS follow_index on follow();
# 重建索引使其生效(会返回一个JOBID)
REBUILD TAG INDEX name;
REBUILD EDGE INDEX follow_index;
# 查看JOBID 状态,判断是否成功
SHOW JOB jobIDNum
5. 修改点和边
用户可以使用
UPDATE语句或UPSERT语句修改现有数据。
UPSERT是UPDATE和INSERT的结合体。当使用UPSERT更新一个点或边,如果它不存在,数据库会自动插入一个新的点或边。
- 用
UPDATE修改 VID 为player100的球员的name属性,然后用FETCH语句检查结果
nebula> UPDATE VERTEX "player100" SET player.name = "Tim";
nebula> FETCH PROP ON player "player100" YIELD properties(vertex);
+------------------------+
| properties(VERTEX) |
+------------------------+
| {age: 42, name: "Tim"} |
+------------------------+
- 用
UPDATE修改某条边的degree属性,然后用FETCH检查结果。
nebula> UPDATE EDGE "player101" -> "player100" OF follow SET degree = 96;
nebula> FETCH PROP ON follow "player101" -> "player100" YIELD properties(edge);
+------------------+
| properties(EDGE) |
+------------------+
| {degree: 96} |
+------------------+
- 用
INSERT插入一个 VID 为player111的点,然后用UPSERT更新它。
nebula> INSERT VERTEX player(name,age) VALUES "player111":("David West", 38);
nebula> UPSERT VERTEX "player111" SET player.name = "David", player.age = $^.player.age + 11 \
WHEN $^.player.name == "David West" AND $^.player.age > 20 \
YIELD $^.player.name AS Name, $^.player.age AS Age;
+---------+-----+
| Name | Age |
+---------+-----+
| "David" | 49 |
+---------+-----+
6. 删除点和边
# 删除点
nebula> DELETE VERTEX "player111", "team203";
# 删除边
nebula> DELETE EDGE follow "player101" -> "team204";


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2018-02-05 根据文件名字获取文件的前缀和后缀的工具类
2018-02-05 【Eclpise】Eclipse中Tomcat启动失败或者是重启失败