一机器学习简介
0. 概念
通过机器来模拟人类认知能力的技术.
1. 人工智能发展必备三要素
数据、算法、计算力(CPU\GPU\TPU)
CPU、GPU对比:
CPU 适合IO密集型任务;GPU 适合计算密集型任务。
2. 人工智能、机器学习、深度学习关系
人工智能
机器学习
深度学习
...
...
...
机器学习是人工智能的一个实现途径;深度学习是机器学习的一个方法发展而来, 由神经网络发展而来。
3. 人工智能应用场景
网络安全、电子商务、计算模拟、社交网络。。。
4. 人工智能主要分支
通讯、感知与行动是现代人工智能的三个关键能力,在这里我们将根据这些能力/应用对这三个技术领域进行介绍:计算机视觉(CV)、自然语言处理(NLP):在 NLP 领域中,将覆盖文本挖掘/分类、机器翻译和语音识别、机器人
-
计算机视觉(CV):机器感知环境的能力,包括图像形成、图像处理、图像提取、图像三维推理等。物体检测和人脸识别是其比较成功的研究领域。
-
语音识别:包括语音转文字、文字转语音
-
文本挖掘/分类:这里的文本挖掘主要是指文本分类,该技术可用于理解、组织和分类结构化或非结构化文本文档。其涵盖的主要任务有句法分析、情绪分析和垃圾信息检测。
-
机器翻译:利用机器的力量自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
-
机器人:机器人学(Robotics)研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。
5. 机器学习
1. 什么是机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
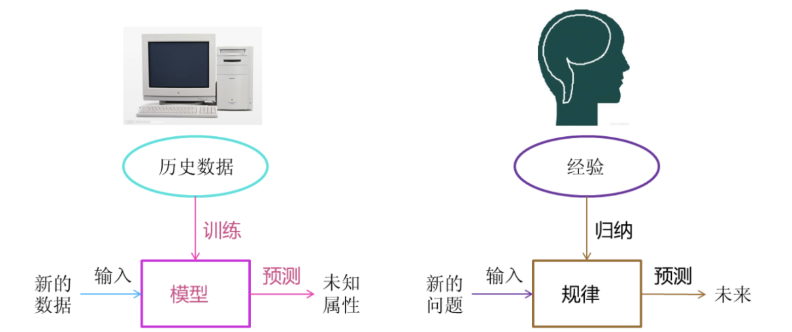
2. 机器学习工作流程

- 1.获取数据
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
- 结果达到要求,上线服务
- 没有达到要求,重新上面步骤
1. 获取数据


数据简介:一行数据称为一个样本;一列数据称为一个特征;有些数据有目标值(标签值),有些数据没有目标值(如上面电影类型就是这个数据集的目标值)
数据类型:第一种是特征值+目标值(目标值是连续的和离散的);第二种是只有特征值,没有目标值
数据分割:分为训练数据和测试数据。 训练数据用于构建模型,测试模型用于评估模型是否有效。两个占比为 7:3 - 8:2 之间。
2. 数据基本处理
包括空值、异常值等处理
3. 特征工程
特征工程是使用专业背景和技巧处理数据,使得特征能再机器学习算法上发挥更好的作用的过程。(数据和特征决定了机器学习的上限,模型和算法只是逼近这个上限)
- 特征提取
将任意数据(文本或图像)转换为可用于机器学习的数字特征
- 特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据
- 特征降维
在某些限定条件下,降低随机变量(特征)个数,得到一组不相关主变量的过程。 比如3D变成2D。
4. 机器学习
参考下面6
5. 模型评估
参考下面7
6. 机器学习算法分类
根据数据集组成不同。可以把机器学习算法分类:监督学习、无监督学习、半监督学习、强化学习
1. 监督学习
指:输入数据是由输入特征和目标值所组成。函数的输出可以是一个连续的值,称为回归;或是输出有限个离散值,称为分类。
- 回归问题: 房价预测。预测的结果可能是一条连续曲线。
- 分类问题:根据肿瘤特征判断良性还是恶性,得到的结果是"良性"或者"恶性",是离散的。
2. 无监督学习
指:输入是由特征值组成,没有目标值。输入数据没有被标记,也没有确定的结果,样本数据类别未知;需要根据样本间的相似性对样本集进行类别划分。
比如人群分类。 根据有无帽子、有无头发等划分的结果不同。
可以分为:
聚类:聚类是一种将对象分组为聚类的方法,使得具有最多相似性的对象保留在一个组中,并且与另一组的对象具有较少或没有相似性。聚类分析发现数据对象之间的共性,并根据这些共性的存在和不存在对它们进行分类。使用案例包括细分客户、新闻聚类、文章推荐等。
关联:关联规则是一种无监督学习方法,用于查找大型数据库中变量之间的关系。它确定在数据集中一起出现的项目集。关联规则使营销策略更加有效。例如购买 X 商品(假设是面包)的人也倾向于购买 Y(黄油/果酱)商品。关联规则的一个典型例子是市场篮子分析。
有监督无监督对比:
| 类别 | 输入 | 输出 |
|---|---|---|
| 监督学习 | 有特征值,有目标值 | 目标值连续:回归;目标值离散:分类 |
| 无监督学习 | 有特征值,无目标值 |
3. 半监督学习
指:训练集同时包含标记样本数据和未标记样本数据。
4. 强化学习
实质是make decisions 问题,即自动进行决策,并且可以连续决策。强化学习的目标就是获得更多的累计奖励。
比如:小孩想要走路,但有个前提是必须先站起来,站起来之后还要保持平衡; 接下来先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
相关对比:
| in | out | 目的 | 例子 | |
|---|---|---|---|---|
| 监督学习 (supervised learning) | 有标签 | 有反馈 | 预测结果 | 猫狗分类 房价预测 |
| 无监督学习 (unsupervised learning) | 无标签 | 无反馈 | 发现潜在结构 | “物以类聚,人以群分” |
| 半监督学习 (Semi-Supervised Learning) | 部分有标签,部分无标签 | 有反馈 | 降低数据标记的难度 | |
| 强化学习 (reinforcement learning) | 决策流程及激励系统 | 一系列行动 | 长期利益最大化 | 学下棋 |
7. 模型评估
模型评估是模型开发过程中不可或缺的一部分。它有助于表达数据的最佳模型和所选模型将来工作的性能如何。
按照数据集的目标值不同,可以把模型评估分类:分类模型评估和回归模型评估。
1. 分类模型评估
根据肿瘤特征判断良性还是恶性,得到的结果是"良性"或者"恶性",是离散的。评价的指标可以有:
准确率:预测正确的占样本总数的比例
其他评价指标:精确率、召回率、AUC指标等
2. 回归模型评估
房价预测的例子。指标有:
均方根误差:(Root Mean Squared Error)一个衡量回归模型误差率的常用公式。不过,它只能比较误差是相同单位的模型。

举例:
假设上面的房价预测,只有五个样本,对应的
真实值为:100,120,125,230,400
预测值为:105,119,120,230,410
那么使用均方根误差求解得:

其他评价指标:相对平方误差(Relative Squared Error,RSE)、平均绝对误差(Mean Absolute Error,MAE)、相对绝对误差(Relative Absolute Error,RAE)
3. 拟合
评价模型的表现效果,可以分为两大类。 过拟合、欠拟合
- 欠拟合:模型学习的太过粗糙,连训练集中的样本数据特征店都没有学出来。总的来说就是学习到的东西太少,模型学习太粗糙。
比如: 机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。

- 过拟合:模型在训练样本中表现得过滤优越,导致在测试数据集中表现不佳。总的来说就是学习到的东西太多,学习的特征太多,不好泛化。
例子:比如在训练集中,天鹅的羽毛都是白的,以后看到黑色羽毛就回认为不是天鹅

8. 补充:机器学习项目流程
- 抽象成数学问题:明确我们可以获得什么样的数据,抽象出的问题,是一个分类还是回归或者是聚类的问题。
- 获取数据
- 特征预处理与特征选择:筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
- 训练模型与调优
- 模型诊断
- 模型融合
- 上线运行
9. 补充:深度学习简介
深度学习(Deep learning), 也称为深度结构学习、层次学习、深度机器学习, 是一类算法集合。 是机器学习的一个分支。
深度学习的发展源头是神经网络。

深度学习方法近年来,在会话识别、图像识别和对象侦测等领域表现出了惊人的准确性。
但是,“深度学习”这个词语很古老,它在1986年由Dechter在机器学习领域提出,然后在2000年有Aizenberg等人引入到人工神经网络中。而现在,由于Alex Krizhevsky在2012年使用卷积网络结构赢得了ImageNet比赛之后受到大家的瞩目。
多层是神经网络,在最初几层是识别简单内容,后面几层是识别一些复杂内容。
1层:负责识别颜色及简单纹理
2层:一些神经元可以识别更加细化的纹理,布纹,刻纹,叶纹等
3层:一些神经元负责感受黑夜里的黄色烛光,高光,萤火,鸡蛋黄色等。
4层:一些神经元识别萌狗的脸,宠物形貌,圆柱体事物,七星瓢虫等的存在。
5层:一些神经元负责识别花,黑眼圈动物,鸟,键盘,原型屋顶等。
10. 补充:可用数据集
一些开源的网站提供了常用的数据集,可以供我们下载使用。
kaggle: https://www.kaggle.com/datasets
UCI: https://archive.ics.uci.edu/ml/index.php
scikit-learn: https://scikit-learn.org/stable/datasets
11. 补充:scikit-learn
sklearn是一个python学习库,包含了许多经典的算法以及数据集。一般python机器学习用到的库包括:pandas、numpy、matplotlib、scikit-learn等,scikit-learn文档写的比较详细,其包含的内容如下:
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
官网: https://www.scikitlearn.com.cn/
其获取数据集有两种方式:
load_xxx: 获取小数据集(依赖库自带)
fetch_xxx: 从互联网下载一些大的数据集
补充:python机器学习依赖的库
(1). requirements.txt内容如下:
matplotlib==2.2.2
numpy==1.14.2
pandas==0.20.3
tables==3.4.2
jupyter==1.0.0
(2). 安装多模块
pip install -r requirements.txt


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2020-09-25 Springcloud入门父工程创建&订单模块&支付模块开发
2019-09-25 python模块、异常、日志
2017-09-25 JS函数(自调函数)与闭包【高级函数】
2017-09-25 Java基础加强-(注解,动态代理,类加载器,servlet3.0新特性)
2017-09-25 Intent显示启动与隐式启动