BUAA_OO第三单元博客作业
BUAA_OO第三单元博客作业
实现规格采取的设计策略
-
确定每个类的功能
首先要对方法所在的类进行自然语言上的理解,大致了解类中每个方法的功能和作用。根据方法来确定类的属性,进一步选择实现属性的类型或是容器。这样可以对之后各个方法的书写提供纲领上的指导。
-
先处理异常
面向用户设计的程序,一般都要注意对异常的处理,因为使用者可能会作出一些错误的操作。例如访问并不存在的信息,重复添加相同的信息等。这时就需要方法抛出异常。在阅读规格时,由于
normal_behavior的条件可能会较为复杂 ,可以先处理异常eceptional_behavior,这样便于处理normal_behavior情况。 -
复杂规格具体化
针对复杂的规格,不能直接机械的翻译,因为这样很可能会造成效率过低
RTLE的问题,对此可以将其翻译成较为严谨的自然语言,联系实际,进行一定的具体化,这样有利对规格进行优化。当真正理解复杂规格所要实现的功能后,就可以构思自己的方法来实现相同的功能。 -
发现方法之间的联系
一个操作可能要调用两个、三个甚至更多的方法,因此不能将每个方法孤立起来,而是要有一定的大局观,发现各个方法的相同之处和依赖关系,对共通的属性进行着重的分析,这样在优化的时候,可以找到重点优化的方法,修改特定的函数。
基于JML的测试方法和策略
测试方法大体分为两种黑盒测试和白盒测试(JUnit单元测试)。
-
先采用白盒测试(JUnit测试)
采用JUnit单元测试,可以对程序进行较大范围的测试,提高代码检查的覆盖率,通过这种测试可以很快地发现方法编写时的最低级的逻辑错误,以解决高强度测试无法准确定位bug的问题。
具体代码实现:
@Test
void contains() throws EqualPersonIdException {
System.out.println("contains");
MyNetwork n = new MyNetwork();
Person a = new MyPerson(1, "1", 1);
n.addPerson(a);
Assert.assertEquals(n.contains(a.getId()), true);
}
void queryBlockSum() throws EqualPersonIdException, PersonIdNotFoundException, EqualRelationException {
System.out.println("queryBlockSum");
MyNetwork n = new MyNetwork();
Person a = new MyPerson(1, "1", 1);
Person b = new MyPerson(2, "2", 2);
Person c = new MyPerson(3, "3", 3);
Person d = new MyPerson(4, "4", 4);
Person e = new MyPerson(5, "5", 5);
n.addPerson(a);
n.addPerson(b);
n.addPerson(c);
n.addPerson(d);
n.addPerson(e);
n.addRelation(b.getId(), c.getId(), 10);
n.addRelation(c.getId(), d.getId(), 20);
n.addRelation(a.getId(), e.getId(), 30);
Assert.assertEquals(n.queryBlockSum(), 2);
}
例如对deleteColdEmoji(int limit)进行测试,它涉及到
HashSet<Intger> emojiIdSet:emoji的id的集合
HashMap<Intger, Integer> emojiHeadMap :emojiId相应的popular
HashMap<Intger, Message> messages:messageId相应的Message
当某个emoji的popular小于limit时,要在emojiIdSet中删除相应的Id,在emojiHeadMap messages中删除相应的键对。
@Test
void deleteColdEmoji() throws EqualEmojiIdException, EqualPersonIdException, PersonIdNotFoundException, EqualRelationException, RelationNotFoundException, MessageIdNotFoundException, EmojiIdNotFoundException, EqualMessageIdException {
System.out.println("deleteColdEmoji");
int limit;
Network network = new MyNetwork();
network.storeEmojiId(1);network.storeEmojiId(2);network.storeEmojiId(3);network.storeEmojiId(4);
Person a = new MyPerson(1, "1", 1);
Person b = new MyPerson(2, "2", 2);
network.addPerson(a);network.addPerson(b);
network.addRelation(a.getId(), b.getId(), 10);
Message message1 = new MyEmojiMessage(1, 1, a, b);
Message message2 = new MyEmojiMessage(2, 1, a, b);
Message message3 = new MyEmojiMessage(3, 1, a, b);
Message message4 = new MyEmojiMessage(4, 2, a, b);
Message message5 = new MyEmojiMessage(5, 2, a, b);
Message message6 = new MyEmojiMessage(6, 3, a, b);
network.addMessage(message1);network.addMessage(message2);network.addMessage(message3);
network.addMessage(message4);network.addMessage(message5);network.addMessage(message6);
network.sendMessage(1);network.sendMessage(2);network.sendMessage(3);
network.sendMessage(4);network.sendMessage(5);network.sendMessage(6);
limit = 2;Assert.assertEquals(network.deleteColdEmoji(limit), 2);
limit = 3;Assert.assertEquals(network.deleteColdEmoji(limit), 1);
limit = 4;Assert.assertEquals(network.deleteColdEmoji(limit), 0);
}
通过对每个函数编写JUnit测试,可以快速准确的进行测试。
-
采取黑盒测试进行强测
通过自己编写的代码覆盖度较大的、强度较大的数据进行整体性的测试,主要测定难度较大、处理较为繁琐的函数,以及验证不同函数之间的联系是否正确。
当JUnit单元测试发现bug后,可以手动输一些自己编号的数据,对出错的函数就行进一步的测试,若是涉及的函数过多,可以通过一步步的调试,分析每一步属性的正确性来发现错误原因。即可改正绝大部分的错误,一般可以保证程序的正确性。
-
大量随机数据检验正确性
最后使用自动评测及生成的大量的有一定强度的数据对程序进行极端情况的检测,来检查超时问题
容器选择和使用
这次作业中,看似规格给定了一些容器,但是直接使用会导致代码的复杂化,很大程度上会影响程序性能。所以要进行容器的正确选择。
-
用
HashMap替换ArrayList这样可以减小代码的书写难度,因为
HashMap中存储着键对关系,所以当要查找个元素时,对于ArrayList而言,需要进行遍历,而HashMap仅仅只需要调用HashMap.get()方法就可以简单快捷的找到所需的元素。-
实例
/*@ public normal_behavior @ requires contains(id); @ ensures (\exists int i; 0 <= i && i < people.length; people[i].getId() == id && @ \result == people[i]); @ also @ public normal_behavior @ requires !contains(id); @ ensures \result == null; @*/ public /*@pure@*/ Person getPerson(int id); -
解决方法
将
Person[] people改为HashMap<Intger, Person> people。这样就可以通过如下实现函数的功能。public Person getPerson(int id) { return people.get(id); }要注意的是,并不是所有的
ArrayList都要替换成HashMap,在规格中有特定要求(顺序要求)的,如List<Message> receivedMessage,就不可以用HashMap来代替,因为这会影响进入容器的顺序。
-
-
HashMap的删除操作在对容器中的元素进行遍历删除时,很容易会发生越界或是错删的现象(以
deleteColdEmoji()方法为例)-
错误用法
//HashMap<Integer, Integer> emojiHeadMap; for (Integer populor : emojiHeadMap.entryValue()) { if (popular < limit) { emojiHeadMap.reomve(i, people.get(i)); } } -
正确用法
对于
ArrayList容器进行遍历时,要在删除时将下标减1,否则会出现漏删的情况,代码如下若容器为
HashMap,则如下所示//迭代器 Iterator<Entry<Integer, Integer>> iter = emojiHeadMap.entrySer().iterator(); while (iter.hasNext()) { Map.Entry<Intger, Integer> info = iter.next(); if (info.getValue() < limit) { iter.remove(); } } //使用removeIf emojiHeadMap.removeIf(entry -> entry.get(i) < limit);
-
性能优化
一般双重for循环会导致超时,可以增加维护的工作量都来提高查询的效率
-
第一次作业
queryBlockSum()函数RTLE一开始制是机械的将JML转化成了java语言,并没有直观、具体的了解这个函数的物理意义,同时并没有意识到这种双重
for循环会超时,改进的方法是增加维护的成本,使得在多次查询时能够减少时间。此函数的具体意义是找到阻塞集的个数,用
HashMap<Integer, HashSet<Integer>> family来表示所有阻塞集的集合,是一个阻塞集的最小Id指向此集合中所有有联系(直接或是间接的联系)的Id的集合的HashMap。所以可以在
addPerson()以及addRelation()进行对family的维护:- 在
addPerson()中要向family中新添加一个由新添加的Id指向仅含自身Id的HashSet的键对; - 在
addRelation(int id1, int id2, int value)中将id1和id2所处的两个阻塞集融合成一个。
这样在调用
queryBlockSum()时,直接返回family.size()即可完成查询任务。 - 在
-
第二次作业
MyGroup类中的getValueSum()函数RTLE虽然了解了此函数的具体意义,但是没有进行深刻的思考,抱着侥幸的心理,导致双重循环超时。此函数的功能是查询某一个
group中所有的所有边的value * 2的和,为了提高查询的效率,我沿用了family并新增了HashMap<Integer, Integer> groupTovaluesum属性来记录每个group对应的值。需要在
MyGroup类中的addPerson(),delPerson()以及在MyNetwork中的addRelation()中对groupTovaluesum进行维护。- 在
addPerson(Person p)中对新添加的p,根据family找到所有与之有联系的人HashSet<Integer> relations,再遍历relations,若与p在同一个group中,就对此group的值进行更新,即groupTovaluesum.put(x,x); - 在
delPerson(Person p)中对要删除的p,对group中的所有人进行遍历,凡是与p有联系的,valuesum就要减小value * 2,最后在groupTovaluesum中进行更新; - 在
addRelation(int id1, int id2, int value)中,要找到id1和id2同时所在的group,然后对此更新(注意,id1与id2可能同时处在多个group中,对每一个的groupTovaluesum都要更新)。
最后只需要在
getValueSum()中直接返回goupTovaluesum.get(groupId)即可。 - 在
-
第三次作业
sendIndirectMessage(int id)此函数的功能是发送信息,主要可能超时的原因是寻找两个人之间的最短距离,我采用的是
dijkstra的堆优化算法。-
首先来谈一下朴素的
dijkstra算法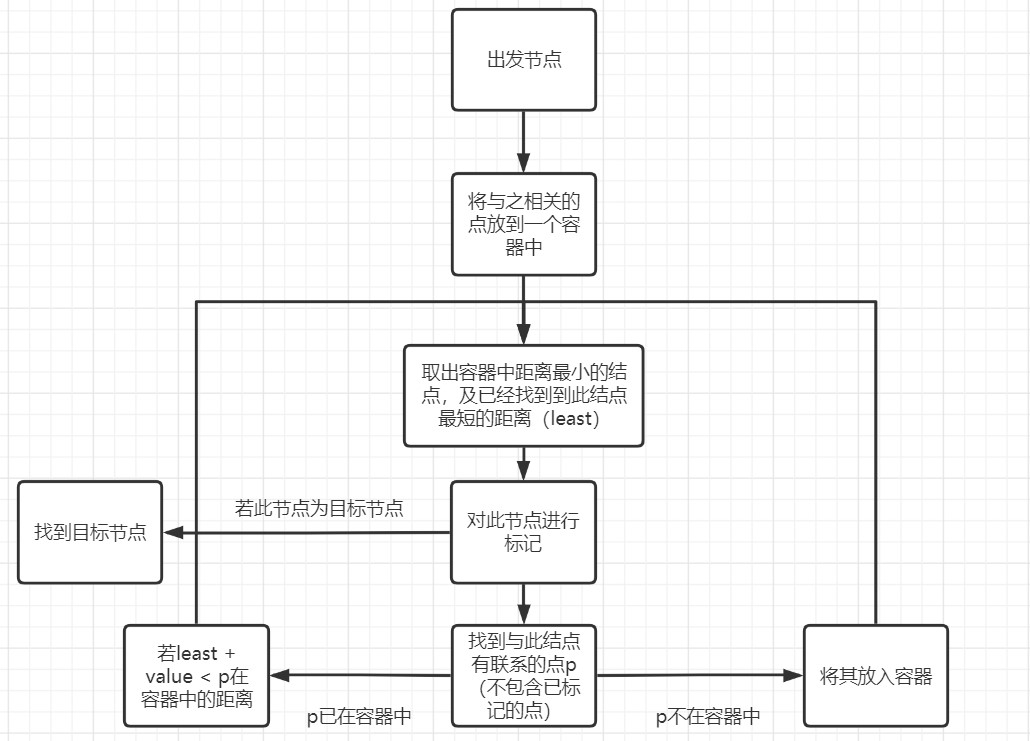
复杂度为O(n2)
-
再聊一下最小堆算法
最小堆定义:最小堆要求父节点比任何的子节点都要小,并且是一个完全二叉树,由此可见根节点的值是最小的。
最小堆的操作(操作完之后,仍然保持最小堆的性质):
-
取出堆顶
取出堆顶节点,将最后的节点放置堆顶,并进行下沉操作。
-
插入节点
将新的节点放置最后的地方,并对之进行上升操作。
-
更新某一节点的值
更新此节点的值,因为新的值若大于原始的值,则进行下沉操作;反之,进行上升操作。
那么什么是上升操作,什么是下降操作呢?代码如下
//上升操作 public void fixUp(int index) { int temp = index; int father = (temp - 1) / 2; //找到此节点的父节点 while (father >= 0) { //若父节点存在 if (data[temp] >= data[father]) { //若此节点的值大于其父节点的值 break; //则退出循环,执行完毕 } else { swap(temp, father); //否则交换此节点和父节点 temp = father; //更新此节点 father = (temp - 1) / 2; //更新父节点 } //继续循环 } } //下降操作同上升操作 public void fixDown(int index) { int temp = index; int son = temp * 2 + 1; while (son < size) { if (son + 1 < size && data[son + 1] < data[son]) { son++; } if (data[temp] >= data[son]) { swap(temp, son); temp = son; son = temp * 2 + 1; } else { break; } } } -
-
dijkstra的堆优化算法将朴素
dijkstra算法中的容器设置为最小堆,找最小元素时直接取出堆顶,找到有联系的点时,运用最小堆的插入、替换算法即可。可以有效的减少寻找最小元素的时间,复杂度为O(n*logn),明显小于O(n2)。
-
架构设计与维护策略
-
UML类图
-
接口类图
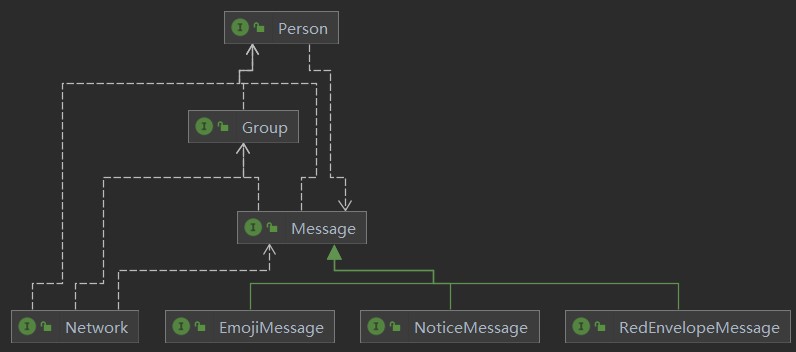
-
创建类图

-
-
类属性的维护和管理(以下举几个例子)
-
MyPerson类HashMap<Person, Integer> relationship:有联系的人及其对应的value。ArrayList<Message> messags:接收到的信息,因为有顺序,所以用ArrayList进行存储。 -
MyGroup类HashMap<Integer, Person> people:存储id指向Person的键对。HashMap<Integer, Integer> groupTovaluesum:存储此group的valuesum。 -
MyNetwork类HashMap<Integer, Person> personHashMap:存储id指向Person的键对。HashMap<Integer, Group> groups:存储groupId指向group的键对。HashMap<Integer, Message> messages:存储messageId指向message的键对。HashMap<Integer, HashSet<Integer>> family:存储一个famliy中一个家族序号最小指向这个家族的所有人的集合的键对(家族定义:所有有联系的人的集合统称为一个家族)。HashMap<Integer, Integer> personFather:存储一个id指向其父亲(家族中序号最小)的键对。HashMap<Integer, HashSet<Integer>> personTogroup:存储id所在的所有group的序号集合的键对。HashMap<Integer, Integer> emojiHeadMap:存储emojiId指向对应的popular的键对。
通过在每一个类中的方法中来维护相应的属性,进而达到对程序的维护。
-
心得体会
第三单元的三次作业看似简单,但是我觉得自己做的不是很好,出现了很多意想不到的错误,像是过度的局部化、没有全面的对程序进行思考,只是以为按照JML规格照搬下来就好。坦率的讲,第三单元所用的时间明显较前两个单元短,也间接导致了出现性能拉跨的情况,不过考着舍友和ljk的帮助勉强苟过去了,第四单元看来是要认真对待了,且行且珍惜。。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号