BUAA_OO第一单元博客作业
第一次作业
UML 图
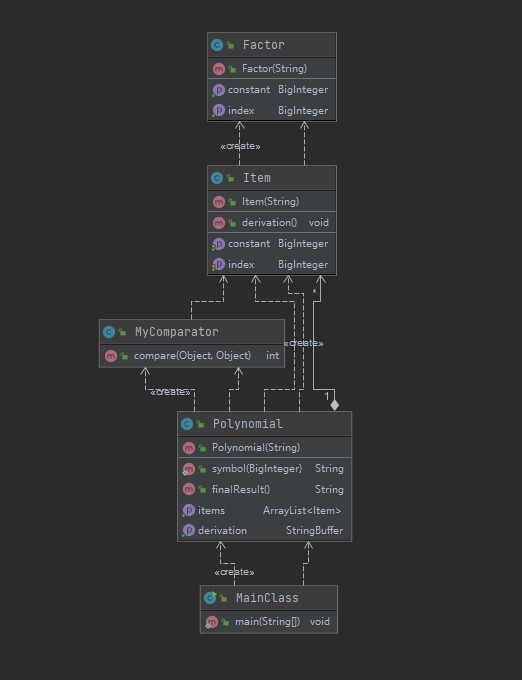
架构与实现方法
根据题目对因子,项,表达式的定义,我建立了Polynomial Item Factor 三个类来分别表示表达式,项,因子。
类的属性方法:
Polynomial:创建Arraylist<Item>属性,来统一管理所有的项,在最后对项进行合并和化简,最后求导。
Item:创建ArrayList<Factor>属性,统一管理项的所有因子,最后对所有项进行合并。
Factor:每个因子含有Constant系数、index指数两个属性。
具体思路:
利用正则表达式来对表达式拆分成项,将项拆分成因子,并对因子的两个属性进行赋值。
性能优化:先对相同指数的项进行合并,再通过MyComparator类对items的系数进行降序排列。但是我忽略了可以将x**2 转化成x*x,导致再强测中性能没有拿到满分。
度量分析
类度量分析
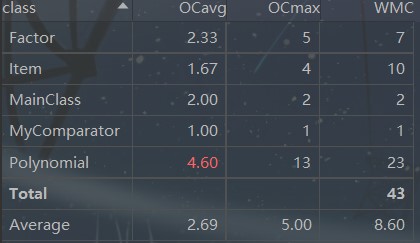
在Polynomial类中OCavg的值过高,由于第一次作业较为简单,就没有考虑过多的封装问题,导致类中循环过多,且容易出错。
方法度量分析
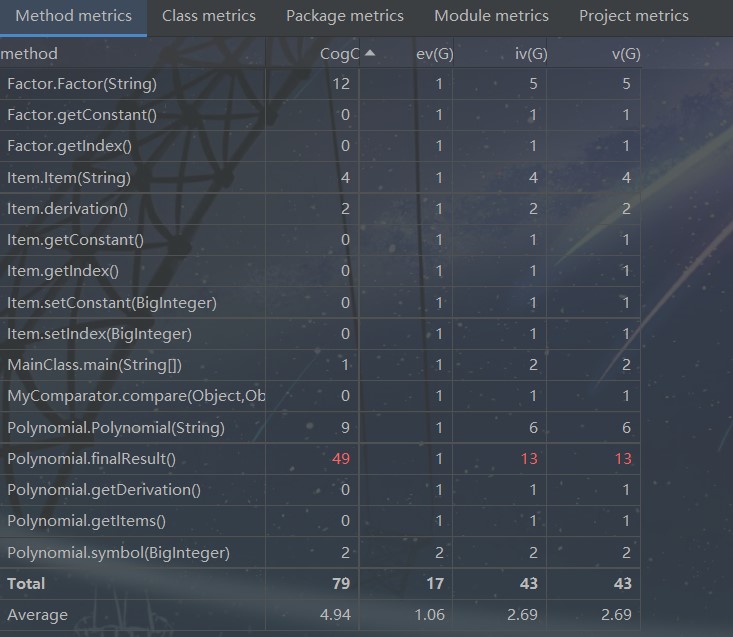
从图中可知,Polynomial类中的finalResult方法的模块设计复杂度过高,模块的耦合度较高。同时圈复杂度较高,不容易调试出错误信息,难于维护。
Dependency metrics

度量总结
出现以上问题是因为我在Polynomial.finalResult方法中应用数量较多的for循环。可以将ArrayList转化为HashMap来减少循环遍历的次数,降低模块设计复杂度和圈复杂度。
debug&hack
debug:
第一次作业较为简单,并且正确的使用了正则匹配,利用自动评测机进行debug时就没有出现问题。我们两位同学依次搭建了随机数据生成机、对拍机和python的自动评测机,有效的发现了其他同学的问题,对自己代码的修正和评测别人有很大的帮助。
hack:
在攻击别人时,通过查看他的代码,发现项与项之间的符号出现了问题,便构造了x ++ -1*x的测试样例。
第二次作业
UML 图
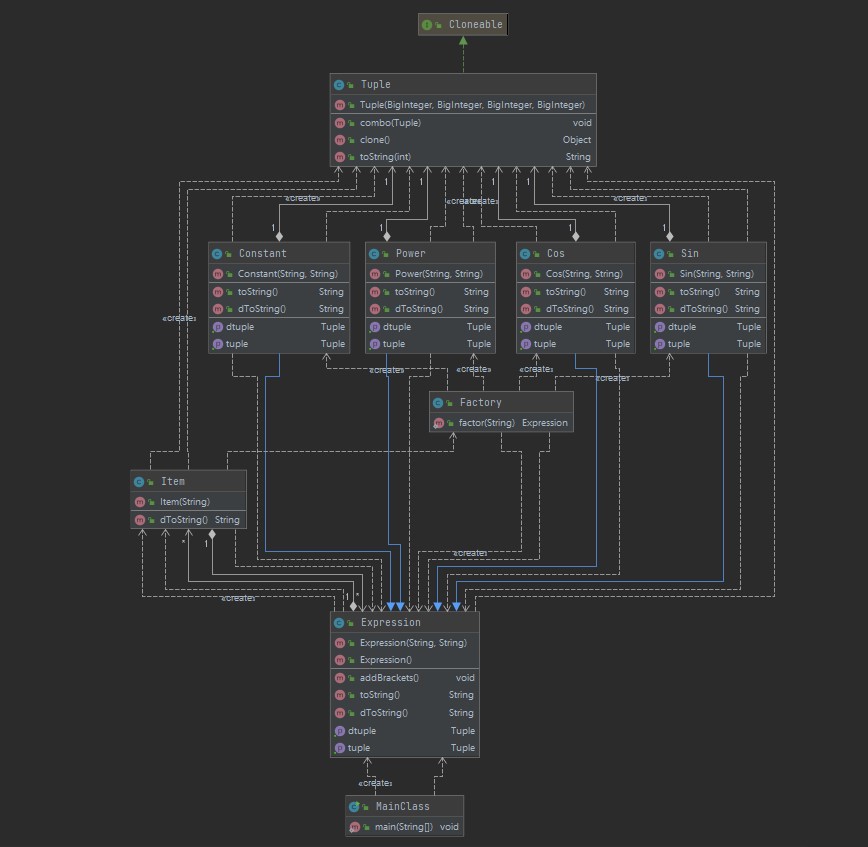
架构与实现方法
我认为第二次作业的难度相对第一次来说有了陡增,不仅新增加了cos sin因子, 并且引入了包含括号的表达式因子,对于括号的处理时本次作业的难点之一。对此我的思路是利用递归的方法依次的求出因子 项 表达式因子 的导数,并用String 来输出表示。
类的结构:
Expresion:表达式类可以拆分成``Item,dToString()方法返回求导后字符串 ,其中会调用Item.dToString(),ToString()`方法返回本身的字符串。
Item:项类可以拆分成Expression类,通过Factory工厂类新建出五种因子(包含表达式因子),dToString()方法返回求导后的字符串,其中调用Tuple.toString(),在这个方法中需要用到乘法的求导公式。
Power、Constant、Cos、Sin:因为表达式因子是Expression类的,所以它们继承了Expression,便于在Item中用ArrayList<Expression>进行管理,都包含dToString()和toString()方法。
Tuple:用于一个项中非表达式因子的化简即对*化简,项中非表达式因子的属性有constantsinIndexcosIndexxindex四种。
具体思路:
对初始的表达式拆分成项,对项拆分成因子。由于因子中可能包含表达式因子, 所以需要
Expression temp = new Expression(str)
新建一个Expression对象即可。程序会调用Expression.dToString()得到表达式因子的导数。
注意TLE问题,解决方法:对求过导的Item 、Expression进行标记,并创建dtostring属性来保存求完导后的字符串,避免对同一Item 、Expression进行多次求导而浪费时间。
度量分析
类度量分析
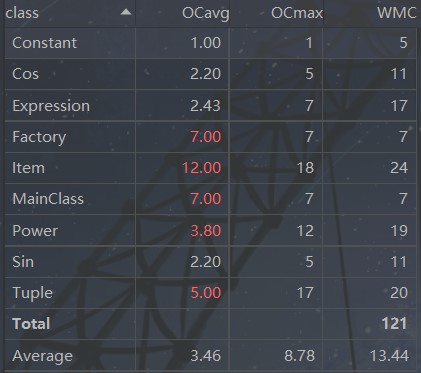
通过度量发现,Factory、Item、MainClass、Power、Tuple的OCavg较高,说明这几个类的平均循环复杂度较高。
方法度量分析

通过方法度量分析,Item.dToString()、Tuple.toString()等的圈复杂度较高,直接导致了所在类的循环复杂度较大。
Dependency metrics

度量总结
可能是因为我使用了for循环来之一的遍历ArrayList中的每个元素,同时在Item.dToString()的乘法求导中使用了双重for循环,导致Item的OCavg过大。延续了第一次作业ArrayList的使用,导致合并时需要循环遍历,并且一直没有意识到这个问题。
debug&hack
debug:
在第二次作业中我出现了超时问题,再进行自我测试时,我利用了python自动评测机,当遇到(((((((((((((((x)))))))))))))))
这种多括号嵌套的问题,由于一开始程序会对同一个Expression、Item进行多次求导,进而导致超时。在互测之后,我对这两个类添加了标记,详见架构及实现方法。
hack:
针对我的错误,我利用多层括号嵌套进行了hack。
第三次作业
UML图

架构与实现方法
第三次作业相对于前两次来说增加了格式判断的内容,同时要求在Sin、Cos类中可以是表达式因子。就难度而言没有较大的提升,但是想要分辨清楚所有的格式错位,以及查到错误后的跳出操作还是有一定难度的。
类的结构:
Sin、Cos:这两个类中新增加了构建表达式因子的方法,将括号内的因子打到Factory工厂类中,新建表达式对象即可。
StopMsgExpection:新建的异常类,当检测到不合规的格式时,就可以抛出这个异常throw new StopMsgExpection(),并在MainClass中捕获,终止对表达式的分析。
其余类:与第二次作业大致相同,只是增加了判断格式合法性以及抛出异常的方法。
具体思路:
在进行表达式拆成项、项拆成因子、Sin Cos内因子类型这三处进行合法性判断。
拆项:从左到右遍历表达式的各个字符,通过括号之外的并且不是带符号整数的
+、-进行拆项,从而得到项。此时若出现)数量大于(,则表达式错误,抛出异常。拆因子:从左到右遍历项的各个字符,当
(与)的数量相同时,若找到*,则可以得到因子的字符串,同时对此字符串进行正则表达式匹配,若匹配成功则是合法的因子,否则抛出异常。
SinCos内的因子类型:同于拆因子时的类型判断,利用正则表达式匹配,失败则抛出异常。
注意:不能随意的对表达式进行预处理,因为随意的合并+ -会导致表达式的格式发生改变。但是为了之后拆因子的方便可以将**替换为^,但在这之间要先判断表达式是否含有^,含有非法字符的话要立刻抛出异常。同时还要注意指数的大小范围。
度量分析
类度量分析

与第二次作业一样,大部分类的OCavg较高,类中的循环过多,其中Item类最为严重,因为我在这个类中应用了三重的for循环进行乘法求导,在MainClass类中为了除去带符号的整数的前导零应允了双重的for循环,在Factory类中应用了switch语句,在因子类中为了进行优化,使用了大量的if else语句。
方法度量分析

有大量的方法CogC较高,原因在于我的很多方法都是面向过程的,并没有很好的建立起面向对象的结构,通过iv(G)可见,类中的每个方法的紧密程度不高,而v(G)也体现出了方法的循环层数较多,难于调试的缺点。
Dependency metrics

度量总结
在方法的层面来看,各个方法连接不紧密,循环较多,进而导致所在类的WMC较高。
在类的层面来看,正是因为我没有构建很好的类结构,才导致了类中方法的繁琐与复杂,导致方法的CogC过高。
debug&hack
debug:
虽然顺利的通过了强测,但是在互测时还是出现了输出的求导后的表达式格式错误,空有两处bug。
在
MainClass类最后的化简处理时,将*1*替换成了空串,此时我忘记考虑了x**1*5这类指数为1的情况。
在优化项时,若符号时
-,则对求完导的表达式加上(),但是我忘记考虑常数求导之后时空串的情况,出现了
-(89)输出-()的情况,并且Expression.dToString()的复杂度也较高,不易调试出bug。
hack:
房间内的代码还都是挺不错的,但是通过对某份代码的分析,我发现了它对cos sin类型因子的格式存在着误判,对空串 以及指数范围存在着一定的错误,这三个问题应该都是由于审题不清造成的。
重构经历
一开始认为第一次的结构不错,但是在第二次引入表达式因子时,立刻就发现了第一次结构的明显漏洞,所以进行了痛苦并快乐着的重构😢,但是因为时间较为紧张,重构的递归出现了一些小的问题,导致超时。
到三次作业时,我便仔细的考虑了是否要重构,最终纠正了第二次作业递归超时的问题之后,便开心地选择了迭代:happy:。
心得体会
在经过了这第一单元的大作业,我发现了Java语言功能的强大,并迅速的掌握了一些基本的语法,也明白了面向对象设计的强大功能。
但是就目前为止,我还是存在着一些语法上的漏洞导致代码的效率不高,例如还没有熟练的掌握并使用HashMap、Implements的使用方法,必须要抓紧实践一下。
更为重要的一点是,在动手写代码之前要经过严谨的思考,确定每个类的属性和方法,以及各个类、接口之间的继承等关系,这样才能顺利地写出高效、简洁的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号