支持向量机——内核
对于非线性“Decision Boundary”
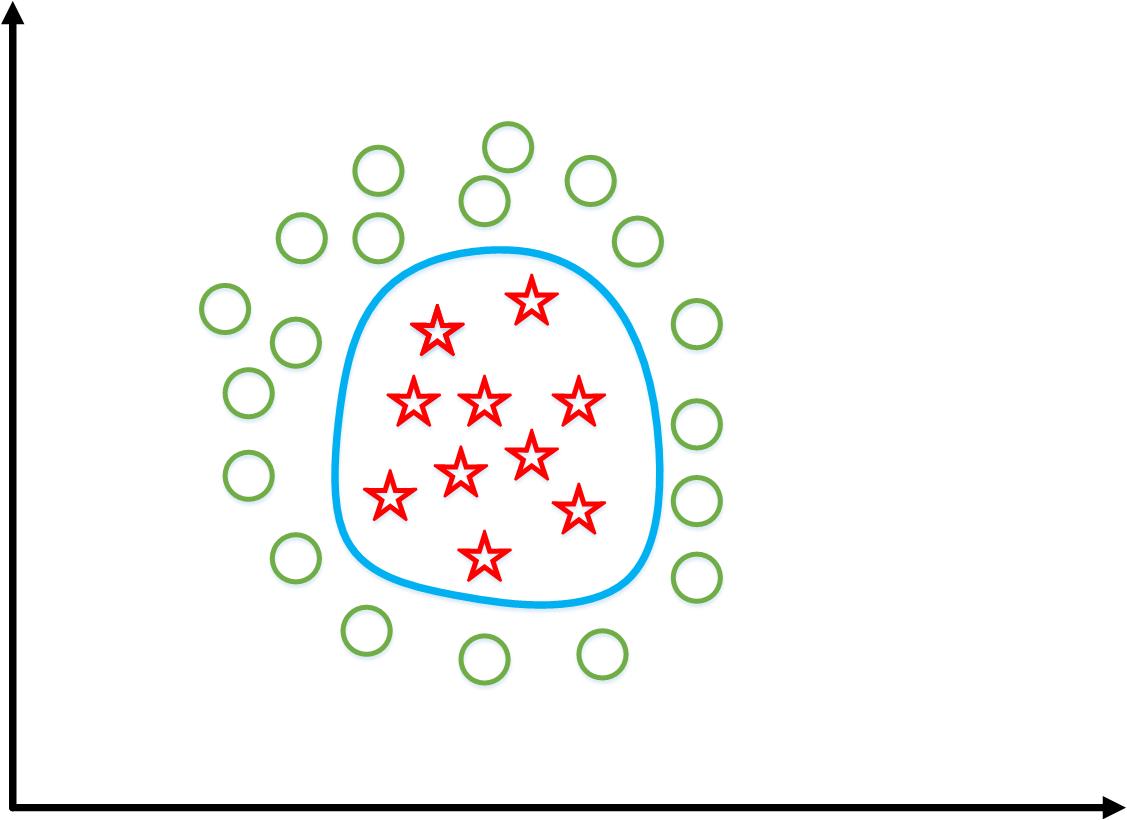
如果用传统的多项式回归,有
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2} + {\theta _3}{x_1}{x_2} + {\theta _4}x_1^2 + {\theta _5}x_2^2 + \cdot \cdot \cdot \]
并且,想要
\[{h_\theta }\left( x \right) = \left\{ {\begin{array}{*{20}{c}}
{\begin{array}{*{20}{c}}
1&{{\theta _0} + {\theta _1}{x_1} + \cdot \cdot \cdot \ge 0}
\end{array}}\\
{\begin{array}{*{20}{c}}
0&{{\theta _0} + {\theta _1}{x_1} + \cdot \cdot \cdot < 0}
\end{array}}
\end{array}} \right.\]
这时,把hθ(x)写成如下形式
\[\begin{array}{l}
{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}{f_1} + {\theta _2}{f_2} + {\theta _3}{f_3} + {\theta _4}{f_4} + {\theta _5}{f_5} + \cdot \cdot \cdot \\
{f_1} = {x_1},{f_2} = {x_2},{f_3} = {x_1}{x_2},{f_4} = x_1^2,{f_5} = x_2^2,...
\end{array}\]
那么问题来了,有没有与这些f不同或比现在这些f更好的选择呢?(比“相乘”、“平方”等更好或不同)
内核
这里为了方便理解,在给定x的情况下,只计算三个新的特征。
这三个特征是根据三个给定的“landmarks”:l(1),l(2),l(3)计算出来的(“landmarks”如何确定稍后再说)。
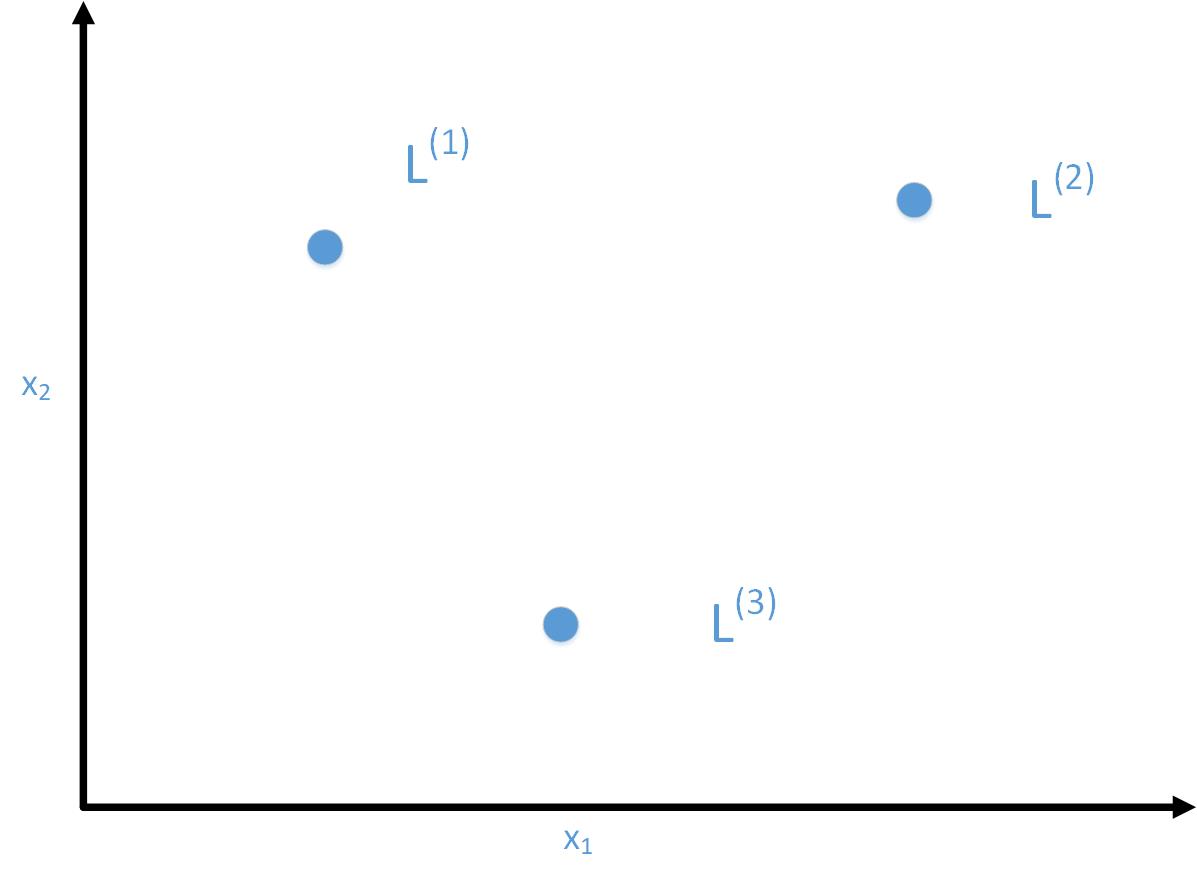
这里假设x只有两个特征x1和x2(这里忽略x0=1)
给出x后,分别计算x与l(1),l(2),l(3)的“similarity”
\[\begin{array}{l}
{f_1} = similarity\left( {x,{l^{\left( 1 \right)}}} \right) = \exp \left( { - \frac{{{{\left\| {x - {l^{\left( 1 \right)}}} \right\|}^2}}}{{2{\sigma ^2}}}} \right)\\
{f_2} = similarity\left( {x,{l^{\left( 2 \right)}}} \right) = \exp \left( { - \frac{{{{\left\| {x - {l^{\left( 2 \right)}}} \right\|}^2}}}{{2{\sigma ^2}}}} \right)\\
{f_3} = similarity\left( {x,{l^{\left( 3 \right)}}} \right) = \exp \left( { - \frac{{{{\left\| {x - {l^{\left( 3 \right)}}} \right\|}^2}}}{{2{\sigma ^2}}}} \right)
\end{array}\]
这里的“similarity”函数就是“内核”,这种内核又称为“高斯内核”。
这个内核函数的作用是什么?
对于
\[{f_1} = similarity\left( {x,{l^{\left( 1 \right)}}} \right) = \exp \left( { - \frac{{{{\left\| {x - {l^{\left( 1 \right)}}} \right\|}^2}}}{{2{\sigma ^2}}}} \right) = \exp \left( { - \frac{{\sum\limits_{j = 1}^n {{{\left( {{x_j} - l_j^{\left( 1 \right)}} \right)}^2}} }}{{2{\sigma ^2}}}} \right)\]
当x≈l(1)时:
\[{f_1} \approx \exp \left( { - \frac{{{0^2}}}{{2{\sigma ^2}}}} \right) \approx 1\]
当x距离l(1)比较远时
\[{f_1} \approx \exp \left( { - \frac{{l\arg enumbe{r^2}}}{{2{\sigma ^2}}}} \right) \approx 0\]
同理,可以得到x与经过“内核”函数后的结果。
用图比较直观的理解
假设
\[\begin{array}{l}
{l^{\left( 1 \right)}} = \left[ {\begin{array}{*{20}{c}}
3\\
5
\end{array}} \right]\\
{f_1} = \exp \left( { - \frac{{{{\left\| {x - {l^{\left( 1 \right)}}} \right\|}^2}}}{{2{\sigma ^2}}}} \right)
\end{array}\]
当σ2=1时
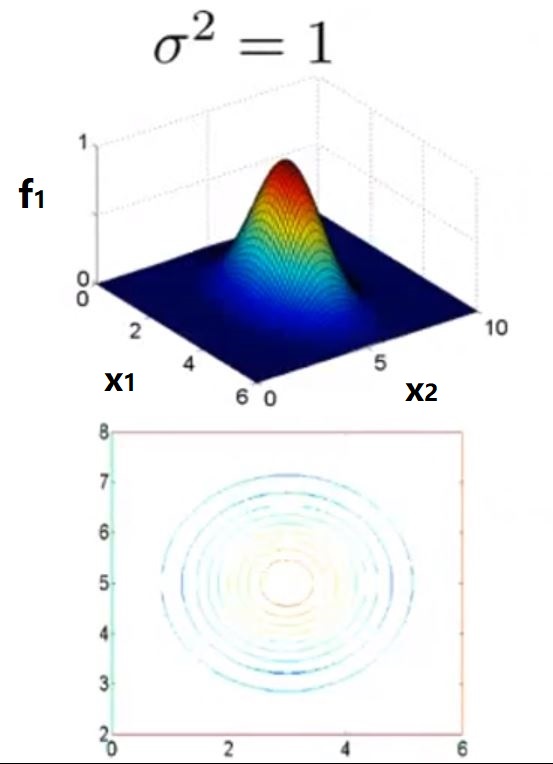
内核函数的示意图如图中上半部分,可以看出当x距离l(1)越近,f1越接近于1,越远越接近于0.
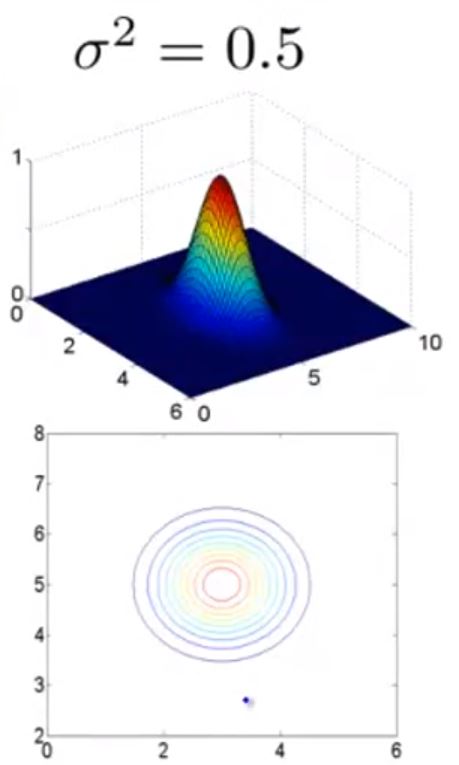
而对于不同的σ来说,图形的形状不相同
当σ2=0.5时
当σ2=3时
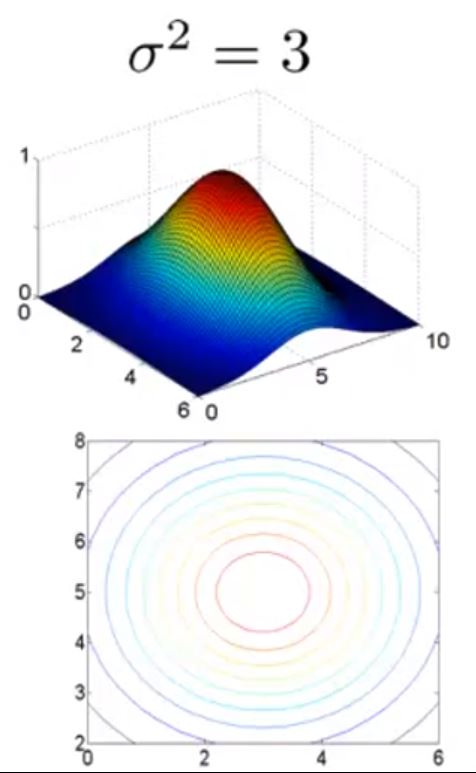
它们的区别在于当x距离l距离变化时f的变化“快慢”不同。
举具体例子
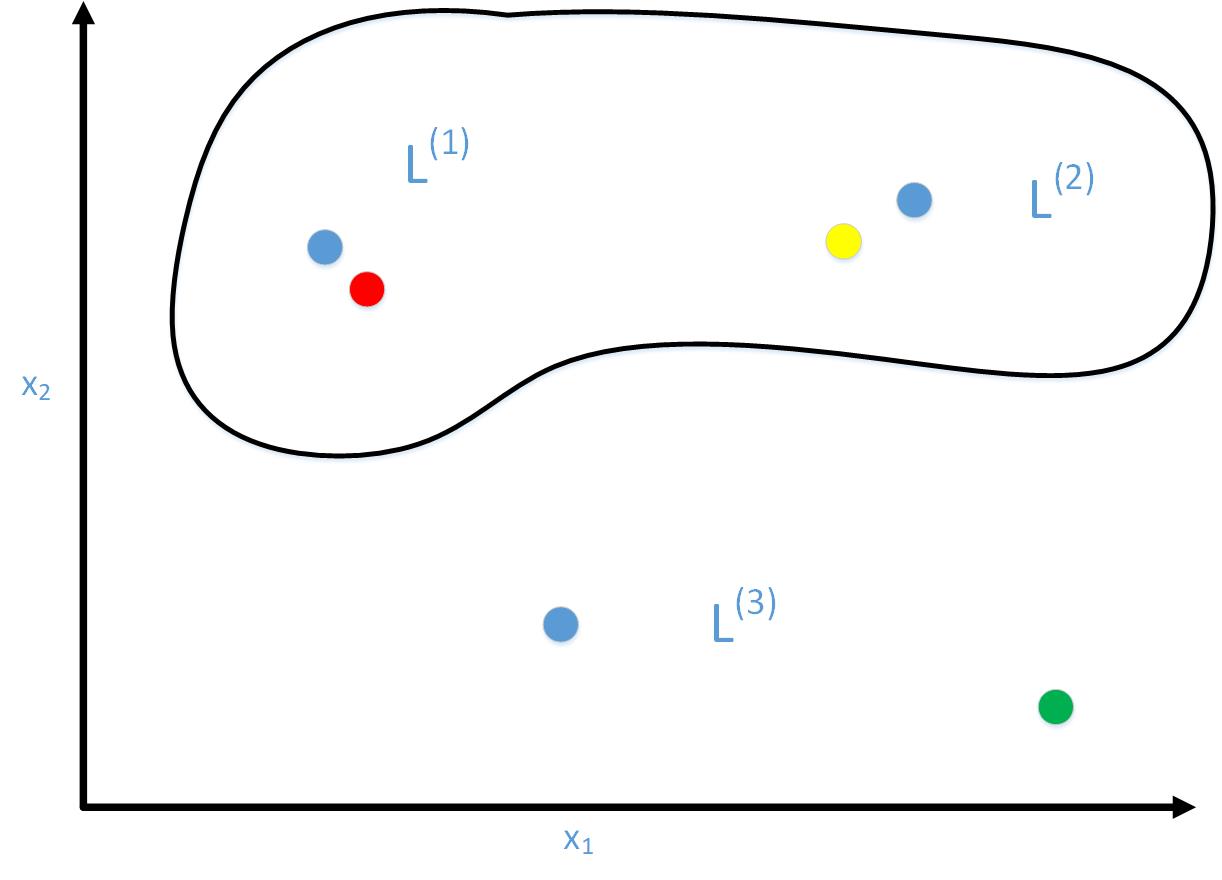
给出x;给出l(1),l(2),l(3)
支持向量机会计算f1,f2,f3
现假设经过训练后得到的参数值θ0=-0.5,θ1=1,θ2=1,θ3=0。
则当x距离l(1)较近时(图中红点)f1≈1,f2≈0,f3≈0,hθ(x)≈0.5≥0,则预测结果为1
同理当为图中绿点时,预测结果为0;黄点时,预测结果为1.
最终支持向量机会得到如图黑色曲线那样的“Decision Boundary”。
如何选定l?
支持向量机会选取所有的样本作为l,也就是如果有m个样本,既有m个l(1),...,l(m)。
经过处理后,支持向量机现在的任务是
\[\underbrace {\min }_\theta \left\{ {C\left[ {\sum\limits_{i = 1}^m {{y^{\left( i \right)}}{\mathop{\rm Cos}\nolimits} {t_1}\left( {{\theta ^T}{f^{\left( i \right)}}} \right) + \left( {1 - {y^{\left( i \right)}}} \right){\mathop{\rm Cos}\nolimits} {t_0}\left( {{\theta ^T}{f^{\left( i \right)}}} \right)} } \right] + \frac{1}{2}\sum\limits_{j = 1}^n {\theta _j^2} } \right\}\]
SVM的参数选择
对于C(相当于1/λ):
- 比较大的C,会出现“低偏差”,“高方差”。这会陷入“过拟合”情况;
- 比较小的C,会出现“高偏差”,“低方差”,这会陷入“欠拟合”情况。
对于σ2:
比较大的σ2,特征f会变化的比较“顺滑”,会出现“高偏差”,“低方差”,这会陷入“欠拟合”情况;
比较小的σ2,特征f会变化的比较“快速”,会出现“低偏差”,“高方差”。这会陷入“过拟合”情况。
内核选择
除了高斯内核,还有:
- “线性内核”,也就是没有内核(θTx)
- “多项式内核”
- String kernel
- chi-square kernel
- histogram
- intersection kernel
- .
- .
多分类
- SVM包中会内置多分类功能
- 可以用“one-vs-all”方法(将别的所有类看成一类)。
逻辑回归 VS. SVMs
- n = 特征的数量,m = 训练样本的数量。
- 当 n 比较大(相对于m)时,用逻辑回归或者SVM的“线性内核”版本;
- 当 n 比较小,m 不是非常大时,用SVM的“高斯内核”版本;
- 当 n 比较小,m 非常大时,创造/增加 n ,然后用用逻辑回归或者SVM的“线性内核”(或者“无内核”)版本;
- 神经网络(插一脚)对于上面这些情况都能很好的工作,但是可能会训练比较慢;
- SVM的“代价函数”是凸函数,所以不需要担心陷入局部最小的问题。

