数据结构 - 左偏树/可并堆学习笔记
 数据结构——左偏树/可并堆学习笔记
数据结构——左偏树/可并堆学习笔记
引入
作为树形数据结构的一员——堆,对于取极值拥有着优秀的复杂度,但是,合并两个堆却成为了一个问题。除了朴素算法外,还有什么算法可以合并两个堆呢?
正文
那么,可并堆是个啥呢?简单来说,它是一个支持合并操作的二叉堆(好像是废话)。
首先,简单介绍一下二叉堆的性质,学过的读者可自行跳过。
- 二叉堆是一棵二叉树
- 二叉堆分为小根堆和大根堆
- 小根堆,顾名思义,就是每个结点的权值都比它的两个子结点(如果是空结点则忽略)小,大根堆也同理。
很显然,因为二叉堆(\(\texttt{priority_queue}\))的性质很有限(重点只有一句话),所以它支持的操作也十分有限,常用的只有查询堆顶(\(\texttt{top}\)),压入堆(\(\texttt{push}\)),弹出堆顶(\(\texttt{pop}\))。
如果我们想要让两个堆合并,暴力的做法就需要 \(O(n\log n)\) 的时间复杂度,显然这
还不是最优解。那么为了应对合并的情况,可并堆就诞生了,它可以用
\(O(\log n + \log m)\) 的时间复杂度完美胜任合并两个堆的任务。下面,我就来介绍竞赛中常见的一种实现方法: \(\textbf{左偏树}\)
左偏树的性质
知周所众,堆的性质只针对根结点,对左右儿子没有任何限制。性质太少导致难以通过较优的算法完成合并操作。但是,我们可以人为地给堆的左右儿子添加一些新的性质,比如接下来说的 \(\textbf{dist}\) 值。
dist 定义
(百度词条的定义不方便写代码,这里放的是 OI Wiki 上的定义)
对于一棵二叉树,我们定义 外节点 为左儿子或右儿子为空的节点,定义一个外节点的 \(\texttt{dist}\) 为 \(\texttt{1}\),一个不是外节点的节点 \(\texttt{dist}\) 为其到子树中最近的外节点的距离加一。空节点的 \(\texttt{dist}\) 为 \(\texttt{0}\) 。
以上为引用。
$ \texttt{qk} $ 版定义:
设当前结点为 \(\texttt{p}\),则 \(dist_p\) 为子树中深度最小的空结点的到 \(\texttt{p}\) 的距离。
注:\(\texttt{dist}\) 又称 \(\texttt{npl}\) 或 \(\texttt{s-value}\)
看图:
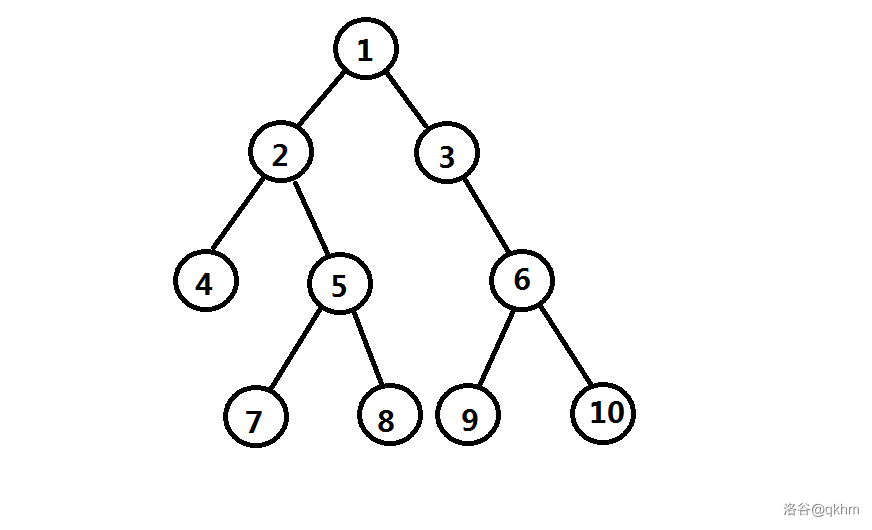
举个栗子,\(\texttt{3,9,10}\) 号结点的 \(\texttt{dist}\) 都是 \(\texttt{1}\),
而 \(\texttt{2,6}\) 号结点的 \(\texttt{dist}\) 为 \(\texttt{2}\).
左偏树的定义
\(\textbf{每个结点的左儿子 dist 都不小于它右儿子的 dist}\)
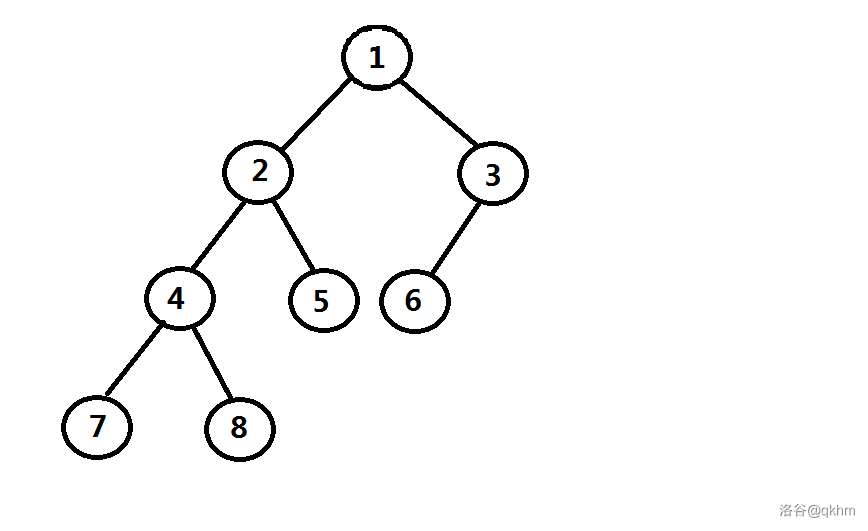
显然,上面的那张图中不是一棵左偏树,而下面这棵就是一棵左偏树(确实树如其名)
不过,下面这棵树也是一棵左偏树,因为它满足左偏树的性质(图中红色数字标注了每个结点的 \(\texttt{dist}\) 值)。
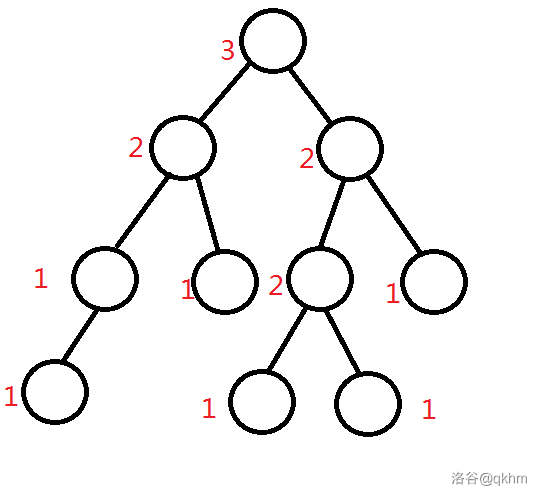
所以,判断是否为左偏树也不能以偏~概全,而
这条性质被叫做左偏树的 \(\texttt{左偏性质}\)
由左偏性质还可以延伸出一条很重要的性质
: 显然,一个结点的 \(\texttt{dist}\) 能且只能被它两个子结点中 \(\texttt{dist}\) 小的更新(想一想,为什么),而右儿子的 \(\texttt{dist}\) 永远比左儿子小,所以可以直接使用右儿子的 \(\texttt{dist}\) 来更新当前结点的 \(\texttt{dist}\)。
得到如下公式
\(dist_p = dist_r + 1\)
记住这个公式,后面合并时会用到。
合并操作 (merge)
这个操作可谓是所有可并堆的灵魂所在了,理解它也很容易。左偏树的合并代码可以分为 \(3\) 部分(这里以小根堆为例)。
- 把根结点权值小的堆(根为 \(\texttt{x}\))作为基础,它的所有左儿子不做出改变,而把另一个堆(根为 \(\texttt{y}\))和 \(\texttt{x}\) 的右儿子继续递归合并。
- 递归到 \(\texttt{x,y}\) 中的一个为空结点时结束,返回不为空的结点编号
- 更新 \(\texttt{dist}\) 值,且把不满足左偏性质的左右儿子互换。
具体图例如下:
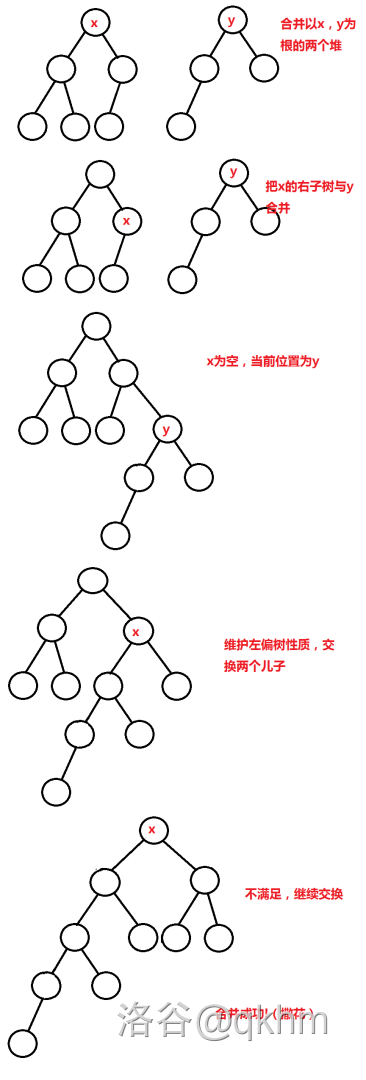
神说手玩一下代码可以帮助理解
int merge(int x,int y){
if(!x | !y) return x | y;
if(val(x) > val(y)) swap(x, y);
r(x) = merge(r(x), y);
if(dst(l(x)) < dst(r(x))) swap(l(x), r(x));
dst(x) = dst(r(x)) + 1;
return x;
}
查询堆顶 (find)
只需要使用一个 \(\texttt{fa}\) 数组来存储每个结点所在子树的根结点就好了。当然,这还不是最优的算法(因为可能会退化成链),我们还可以使用路径压缩,使每个结点直接指向自己的根结点。
查询代码如下:
int find(int x){
return fa(x) == x ? x : fa(x) = find(fa(x));
}
完善后的合并代码(其实只加了一句话)
int merge(int x,int y){
if(!x | !y) return x | y;
if(val(x) > val(y)) swap(x, y);
r(x) = merge(r(x), y);
if(dst(l(x)) < dst(r(x))) swap(l(x), r(x));
dst(x) = dst(r(x)) + 1;
fa(l(x)) = fa(r(x)) = fa(x) = x;
return x;
}
压入堆 (push)
把问题转换成把一个堆和一个只有单个结点的堆合并即可,不再贴代码。
建堆 (build)
如果已经给出一些在同一个堆里的结点信息,是否可以直接建堆,而不是挨个 \(\texttt{push}\) 呢?那当然是有的(不然我说这干嘛)。
和建普通堆一样,一般通过队列实现,每次把队首的两个堆取出来,合并后扔到队尾,直到只剩下一个堆。
示例图长这样:
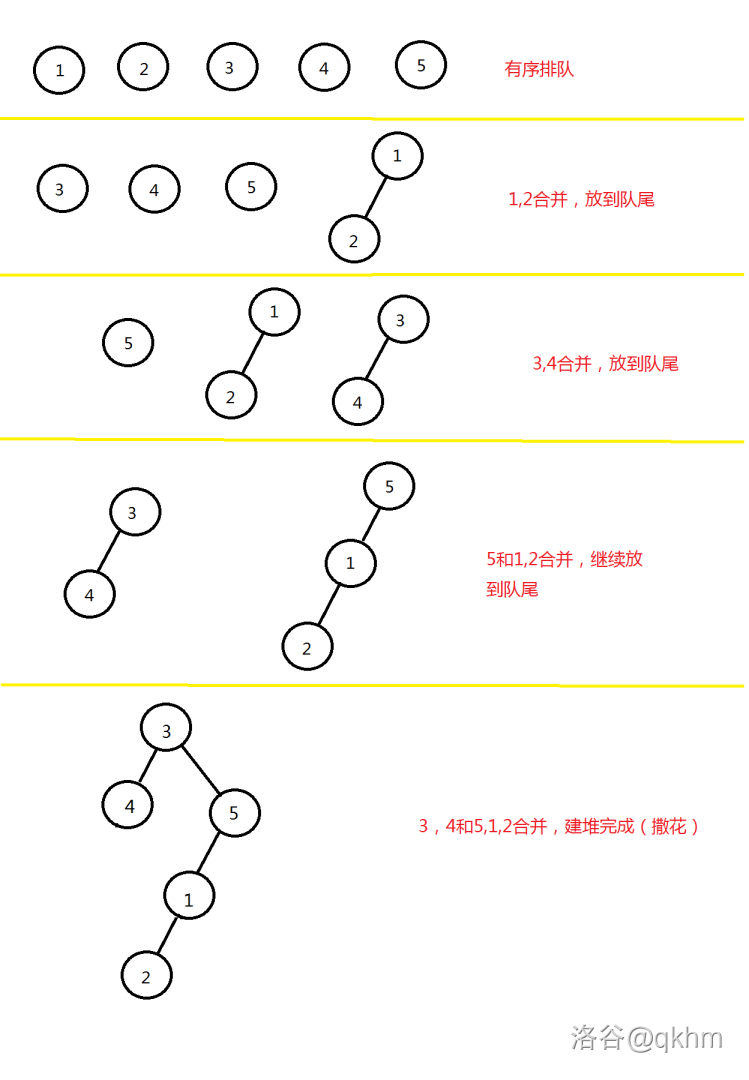
代码如下:
int build(){
queue <int> q;
for(int i = 1;i <= n;++ i) q.push(i);
while(q.size() > 1){
int x = q.front();q.pop();
int y = q.front();q.pop();
q.push(merge(x, y));//取出前两个合并
}
return q.front();//返回合并出的根结点
}
时间复杂度可以看这张图:
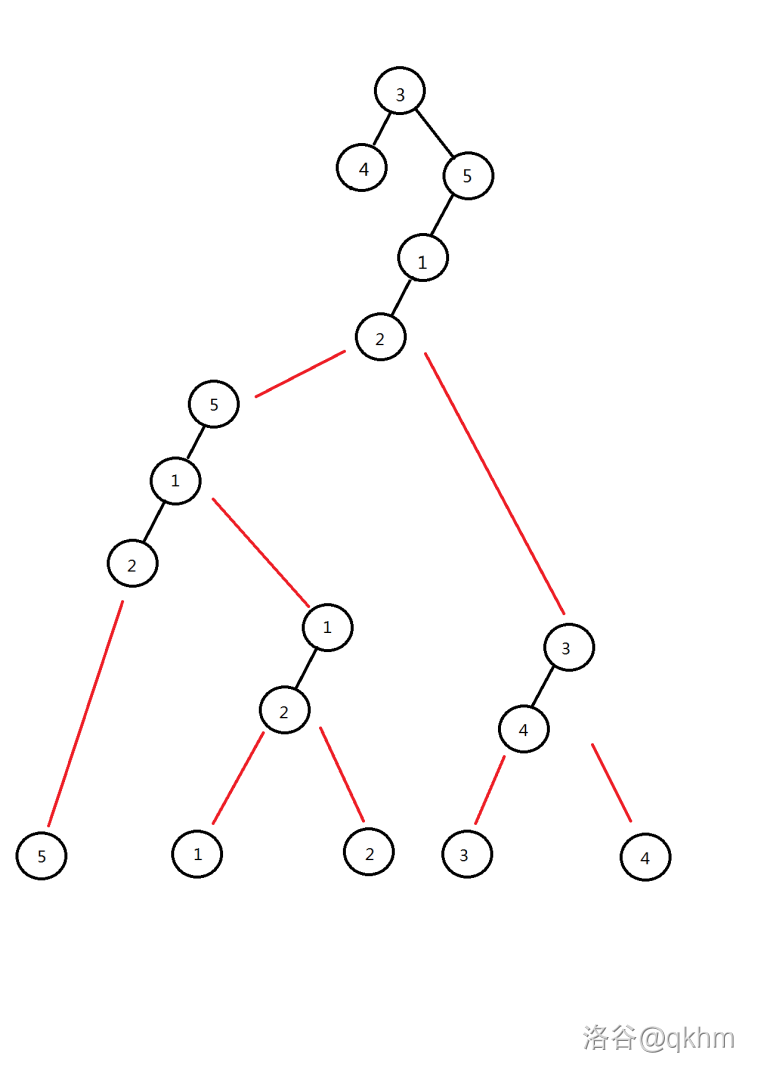
可以看到,要比朴素 \(\texttt{push}\) 的 \(O(n \log n)\) 快不少,只合并了 \(\texttt{4}\) 次,大概是 \(O(n)\) 的,有常数。
弹出堆顶 (pop)
把根结点的左右儿子合并,再维护一下并查集就好了,但有一些地方需要格外注意,先看代码
int pop(int x){
val(x) = -1;
fa(l(x)) = l(x),fa(r(x)) = r(x);
fa(x) = merge(l(x), r(x));
return 0;
}
这里把根结点的权值定为 \(\texttt{-1}\) 来表示它被删掉了,同时维护左右子树的 \(\texttt{fa}\) 。
有些读者可能对这条语句很疑惑
fa(x) = merge(l(x), r(x));
\(\texttt{x}\) 不是被删掉了吗,为什么要多此一举地改变 \(fa_x\),合并儿子不就行了吗?其实是因为这里只改变了根结点附近的 \(\texttt{fa}\) ,还有一些结点仍然认被删结点 \(\texttt{x}\) 为老大,所以让 \(\texttt{x}\) 认新合并出的根结点为老大,这样后面的结点自然也就认新根结点为老大了(老大的老大还是老大)。避免了并查集产生混乱。(\(\texttt{dp}\) 优化里也有类似的转换思想)
例题
看到这,你应该已经学会了左偏树的基础操作,但光说不练假把式,让我们看一道例题。
重点之前已经提过,直接贴代码(为了偷懒便于读者理解使用了 \(\texttt{define}\) )
#include<bits/stdc++.h>
#define l(p) tr[p].lt
#define r(p) tr[p].rt
#define val(p) tr[p].val
#define dst(p) tr[p].dist
#define fa(p) tr[p].fa
using namespace std;
const int Maxn = 1e5+100;
struct teap{int fa, lt, rt, val, dist;}tr[Maxn];
int n, m;
int find(int x){return fa(x) == x ? x :fa(x) = find(fa(x));}
int merge(int x,int y){
if(!x | !y) return x | y;
if(val(x) > val(y)) swap(x, y);
r(x) = merge(r(x), y);
if(dst(l(x)) < dst(r(x))) swap(l(x), r(x));
dst(x) = dst(r(x)) + 1;
fa(l(x)) = fa(r(x)) = fa(x) = x;
return x;
}
int pop(int x){val(x) = -1;fa(l(x)) = l(x),fa(r(x)) = r(x);fa(x) = merge(l(x), r(x));return 0;}
int main(){
scanf("%d%d",& n,& m);
for(int i = 1;i <= n;++ i)
fa(i) = i,scanf("%d", & val(i));
int t, x, y;
for(int i = 1;i <= m;++ i){
scanf("%d%d",& t,& x);
if(t == 1){
scanf("%d",& y);
if(val(x) == -1 || val(y) == -1) continue;
int l = find(x),r = find(y);
if(l != r) fa(l) = fa(r) = merge(l, r);
}
else{
if(val(x) == -1) printf("-1\n");
else printf("%d\n",val(find(x))),pop(find(x));
}
}
return 0;
}
课后习题 (几道十分经典的题目)
进阶部分
删除任意数
-
给定权值
其实包括普通的二叉堆和左偏树,都是不太支持删除指定权值的数的。因为需要遍历整个堆来寻找,\(O(nk)\) 的时间复杂度对于竞赛无法接受。如果实在想实现这种操作,可以在外面再敲一个平衡树之类的数据结构维护结点编号和权值的关系,或者可以通过 \(\texttt{map}\) 维护,但毕竟不是平衡树的题目,局限性还是有的。不过不必担心,这种
双层大数据结构的毒瘤题目应该不会在正式竞赛中出现。 -
给定结点编号
这种要求就十分好满足了,有两种情况。
- 删除的是根结点,和上文中的 \(\textbf{pop函数}\) 一样,不再赘述。
- 删除的是某个结点的子结点,这时其实仍然可以通过合并左右儿子的方式来删除,但问题是,这样删除会影响到这个结点的祖先。所以我们对每个节点记录它的父结点,每次合并后往上查找是否有需要更新的值,有则更新(注意这时不能再使用路径压缩了)。
函数具体代码如下:
上传操作(\(\texttt{pushUp}\) )
void pushUp(int x){
if(!x) return;
if (dist(l(x)) < dist(r(x))) swap(l(x), r(x)); //upd on 2025.4.30
if(dist(x) != dist(r(x)) + 1){
dist(x) = dist(r(x)) + 1;
pushUp(fa(x));//有更改才继续上传
}
}
删除操作(\(\texttt{pop}\))
int pop(int x){
return merge(l(x), r(x));//合并函数放下面
}
修改某个堆中全部结点的权值
可以给根结点打懒惰标记,只有查询或合并的时候才更改结点的权值,而懒惰标记的形式与线段树类似。
下传操作(\(\texttt{pushDown}\))
void pushDown(int x){
if(add(x) == 0 && mul(x) == 1) return;//小优化
if(l(x)){
val(l(x)) *= mul(x);
val(l(x)) += add(x);
mul(l(x)) *= mul(x);
add(l(x)) *= mul(x);
add(l(x)) += add(x);
}
if(r(x)){
val(r(x)) *= mul(x);
val(r(x)) += add(x);
mul(r(x)) *= mul(x);
add(r(x)) *= mul(x);
add(r(x)) += add(x);
}
add(x) = 0,mul(x) = 1;//加法清零,乘法归一
}
还是合并操作(\(\texttt{merge}\))
int merge(int x,int y){
if(!x || !y) return x | y;
if(val(x) > val(y)) swap(x, y);
pushDown(x),pushDown(y);//防止合并后找不到自己的儿子,先下传
r(x) = merge(r(x), y);
if(dist(l(x)) < dist(r(x))) swap(l(x), r(x));
pushUp(x);
fa(l(x)) = fa(r(x)) = x;//注意这里的 fa 不再是它的根结点,而是它的直接父亲
return x;
}
\(\textbf{注意, pushDown 一定要加上,不要漏了。}\)
例题
\(\textbf{简化题意}\):
有 \(\texttt{n}\) 个骑士攻城,如果骑士战斗力比城池的防御力高就能攻下,并且战斗力加强,否则会战死。问每个骑士攻下了多少座城,以及每座城有多少骑士战死。(所有城池构成了一棵树)
\(\textbf{思路}\):
每次把攻同一座城的骑士中取最弱的出来和城池的防御力作比较,如果低就战死,否则所有幸存的骑士(数量可能为 \(\texttt{0}\))就都能攻下。然后把幸存的骑士与攻占此城池的父亲城池的骑士一起攻占父亲城池。从叶子城池到根城池如此执行即可。
很显然,每次取最弱 \(+\) 合并两个城池的骑士,这题应该是可并堆。
具体实现:攻占同一城池的骑士建一个堆,每次取出堆顶与城池防御力作比较,低的就弹出。最后把幸存的骑士与攻占此城池的父亲城池的骑士合并,继续操作。
实例代码(久远代码,空结点 dist 为 -1):
#include<bits/stdc++.h>
#define int long long
#define l(p) tr[p].lt
#define r(p) tr[p].rt
#define dst(p) tr[p].dist
#define val(p) tr[p].val
#define add(p) tr[p].add
#define mul(p) tr[p].mul
#define h(i) c[i].h
#define f(i) c[i].f
#define a(i) c[i].a
#define v(i) c[i].v
#define d(i) c[i].die
#define cit(p) tr[p].cit
#define die(p) tr[p].die
using namespace std;
const int Maxn = 3e5+10;
struct node{int lt, rt, val, add, mul, dist, cit, die;node(){mul=1;}}tr[Maxn];
struct city{int h, f, a, v, die;}c[Maxn];
int n, m, root[Maxn], dep[Maxn];
void pushDown(int x){
if(add(x) == 0 && mul(x) == 1) return;
if(l(x)){
val(l(x)) *= mul(x);
val(l(x)) += add(x);
mul(l(x)) *= mul(x);
add(l(x)) *= mul(x);//这句话少写了,找了我一下午
add(l(x)) += add(x);
}
if(r(x)){
val(r(x)) *= mul(x);
val(r(x)) += add(x);
mul(r(x)) *= mul(x);
add(r(x)) *= mul(x);//还有这句
add(r(x)) += add(x);
}
add(x) = 0,mul(x) = 1;
}
int merge(int x,int y){
if(!x || !y) return x | y;
if(val(x) > val(y)) swap(x, y);
pushDown(x),pushDown(y);
r(x) = merge(r(x), y);
if(dst(l(x)) < dst(r(x))) swap(l(x), r(x));
dst(x) = dst(r(x)) + 1;
return x;
}
int pop(int x){return merge(l(x),r(x));}
int read(){
int x = 0;bool f = 0;char c = getchar();
while(c < '0' || c > '9') {if(c == '-') f = 1;c = getchar();}
while(c >= '0' && c <= '9') {x = (x << 3) + (x << 1) + c - '0';c = getchar();}
return f ? -x : x;
}
signed main(){
n = read(),m = read();
memset(root, -1, sizeof(root));
for(int i = 1;i <= n;++ i) h(i) = read();
dep[1] = 1;dst(0) = -1;//编号为0的结点特殊处理,原因留给读者自己思考(提示:手动删除这条语句,看会发生什么)
for(int i = 2;i <= n;++ i)
f(i) = read(),a(i) = read(),v(i) = read(),
dep[i] = dep[f(i)] + 1;
for(int i = 1;i <= m;++ i){
val(i) = read(),cit(i) = read(),mul(i) = 1;
if(root[cit(i)] == -1) root[cit(i)] = i;
else root[cit(i)] = merge(root[cit(i)], i);
}
for(int x = n;x >= 1;-- x){//作者开始没看见 fi<i,用拓扑处理的, T 到飞起
while(root[x] != -1 && h(x) > val(root[x])){
die(root[x]) = x;++ d(x);
pushDown(root[x]);
if(!l(root[x])) root[x] = -1;//根据左偏性质,左儿子为空此堆最多只有一个根结点
else root[x] = pop(root[x]);
}
if(x == 1) break;;
if(root[x] != -1){
if(a(x)) mul(root[x]) *= v(x),add(root[x]) *= v(x),val(root[x]) *= v(x);
else val(root[x]) += v(x),add(root[x]) += v(x);
pushDown(root[x]);
if(root[f(x)] == -1) root[f(x)] = root[x];
else root[f(x)] = merge(root[f(x)], root[x]);
}
}
for(int i = 1;i <= n;++ i)
printf("%lld\n", d(i));
for(int i = 1;i <= m;++ i)
printf("%lld\n", dep[cit(i)] - dep[die(i)]);
return 0;
}
习题(成果检测机):
P4331 [BalticOI 2004]Sequence 数字序列
扩展部分
其他可并堆
\(\textbf{根据个人情况选择性学习}\)
- \(\texttt{斐波那契堆(Fibonacci heap)}\)
拥有超高效率的神仙数据结构(合并均摊复杂度为 \(O(1)\)),但码量偏大,学习使用都需要一定的时间成本。
斐波那契堆是由一些有根树(不一定是二叉树)组成,每个结点存储键值,度数,前驱后继,第一个儿子,父结点 等值 。通过类似双向链表的结构存储和查询(孩子兄弟表示法),合并就是把两个链表合成一个链表。
- \(\texttt{配对堆}\)
被认为是简化的斐波那契堆,因为弹出堆顶时要把子结点两两配对以提高效率而得名。
- \(\texttt{斜堆}\)
斜堆(\(\texttt{Skew heap}\))也叫自适应堆(\(\texttt{self-adjusting heap}\)),其实就是简化版的左偏树,或者说左偏树的变种,它和左偏树唯一的区别在于合并操作。
斜堆并没有 \(\texttt{dist}\) 的概念,它在合并时无需比较左儿子和右儿子的 \(\texttt{dist}\) ,而是直接无脑交换,不过时间复杂度均摊也是 \(\log\) 级别的(左偏树最差 \(\log n\))。
- \(\texttt{二项堆}\)
二项堆(\(\texttt{binomial heap}\)) 是一种对结点度数进行限制的可并堆。
简单来说,度数为 \(\texttt{k}\) 的结点,一个二项堆中只能有 \(\texttt{0}\) 或 \(\texttt{1}\) 个。
通过让一个二项堆去当另一个二项堆的左儿子来实现合并,同样,二项堆不一定是二叉树。
可持久化
没错,作为唯一坚守本心,仍是二叉结构的左偏树,也是极少的支持可持久化的可并堆之一。持久化的做法和其他持久化数据结构类似。每次合并时,把作为基础的根结点 \(\texttt{x copy}\) 一份,把 \(\texttt{copy}\) 出来的新结点与 \(\texttt{y}\) 继续合并。
可持久化可并堆可以用来解决 k短路问题。
持久化版合并实例代码如下:
int merge(int x,int y){
if(!x | !y) return x | y;
if(val(x) > val(y)) swap(x, y);
int cnt = ++ idx;//新建一个结点
l(cnt) = l(x),val(cnt) = val(x);//继承
r(cnt) = merge(r(x), y);//以下为基础操作
if(dist(l(cnt)) < dist(r(cnt))) swap(l(cnt), r(cnt));
dist(cnt) = dist(r(cnt)) + 1;
return cnt;
}
左偏树小结
其实左偏树的题目还可以使用线段树合并或其他手段 \(\texttt{AC}\) ,而左偏树效率也比不上斐波那契堆和配对堆等数据结构,但那些方法要么理解困难,要么代码赘长,码量巨大,对蒟蒻极不友好。相比之下,上手难度较小,应用范围偏广的左偏树就十分适合在高级数据结构学习初期,帮助学者理解树形结构的基础思想。
虽然在 \(\texttt{pbds}\) 时代,手写堆(包括可并堆)已经基本过时了,但是,左偏树的独特思想仍然在信息学的海洋中闪烁着迷人的光辉。
后记
其实理解了左偏树后,你会发现不是必须左偏的,有些人就喜欢写右偏树(诱骗树),这种输入法都打不出来的奇怪数据结构。
关于左偏树的时间复杂度证明 -> 戳这
以及 OI Wiki 上对左偏树的介绍 -> 戳这
还有本文部分习题的代码 -> 戳这
最后附上我个人推荐的数据结构学习顺序
- 入门: 栈,队列,二叉树,链表等
- 进阶:单调栈,单调队列,堆,\(\texttt{ST}\) 表,并查集,\(\texttt{Hash}\) 表等
- 进入新世界:树状数组,线段树基础,字典树(\(\texttt{Trie}\)),左偏树等
- 登堂入室:后缀树,分块,树套树,并查集扩展应用,平衡树(包括但不限于 \(\texttt{FHQ , Splay , 替罪羊}\)),可持久化系列,动态树等
\(\textbf{越简单巧妙的数据结构越是凝聚了发明者的心血与智慧}\)
\(\textbf{数据结构的大门在向你敞开呢,少年}\)
作者碎碎念
蒟蒻作者的第一篇学习笔记,如果觉得有什么问题,一定要私信作者改正啊。
特别鸣谢 $ \textbf{Trump__Biden,Full_Speed , Mortis_Life } $ 等多位 \(\texttt{dalao}\) 对本文的支持
以及 \(\textbf{5k_sync_closer}\) \(\texttt{dalao}\) 对本文的排版指导
时间仓促,如有错误欢迎指出,欢迎在评论区讨论,如对您有帮助还请点个推荐、关注支持一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号