数据结构-后缀自动机(SAM)
 如题
如题
简述
维护字符串所有子串的数据结构,也是一个 。
前置需知
对于一个子串 ,它在原串 中的出现位置组成了一个集合,记作 。
比如 ,, 。
我们称 完全相同的子串组成的集合叫做一个等价类,称其中长度最长的等价类为其代表元素。
例如上面的例子,其中 , 就组成了一个等价类。
我们可以发现等价类的一些性质。
这是很显然的性质,因为他们的结尾位置都完全相同。
对于最长的代表元素,等价类中的其他子串一定是它的后缀。
如图:
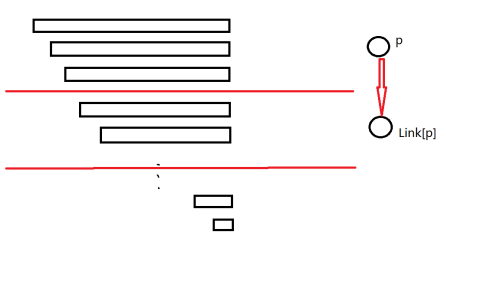
红线分隔开不同等价类,一个等价类对于一个状态。
红色箭头表示后缀指针,之后统一称作 。
如果一个等价类中元素全是另一个等价类 中元素的后缀,那么我们就将 的后缀指针 指向这个等价类。
可以发现,。
特别的,我们将最短子串长度为 的等价类 指向空串。
同样的根据定义,所有的等价类中子串的并一定是原串的子串集。
并且不同的等价类的交一定为 。
也就是说,我们存储的等价类刚好 地遍历了原串的所有子串。
每个状态都代表一个等价类,这是后缀自动机状态存储最重要的性质。
建立
这也是 最关键的操作了,我们采取在线增广的方式解决。
我们称一个状态 通过字符 的转移边能转移到状态 ,
当且仅当 中的所有子串拼接上字符 后全部属于 。
记一个状态中代表元素的长度为 。
假设我们已经求出了 的后缀自动机,我们尝试插入 ,来看看会对 造成什么修改。
看图:
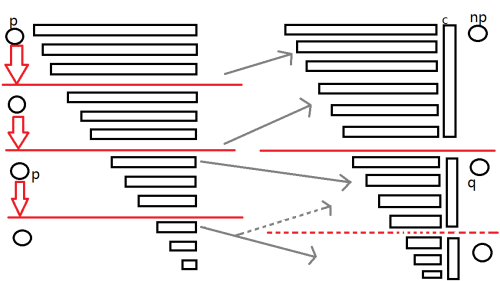
上一个插入的状态为 ,当前插入状态 。
根据定义,我们可以令 ,即从 添加 到 。
接下来,我们需要对 的其他结构进行修改。
让 跳后缀链接迭代其他节点 ,如果 没有一条 的转移边,就像图中第二层的状态,就连一条 的转移边到 ,因为没有其他的地方以这个状态结尾。
如果一直没有 有 的转移边,则将 连向空状态。
如果有,对于这个 (以下记作 ),记 。
看图,如果 状态没有最上面那部分子串,那么它更好可以做 的后缀链接指向的状态。
即 时, 。
但是很多时候,并没有那么简单,根据定义要求新建一个状态 表示 接上一个 转移到的状态。
同时, 。
如图:
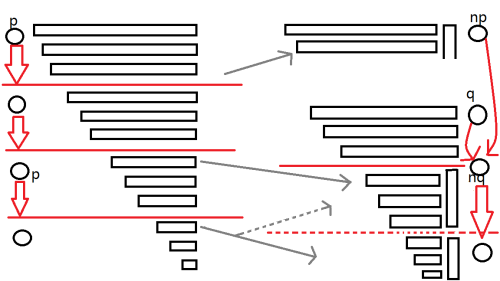
同样的根据定义,因为 为原来 的子集,所以转移边需要继承。
并且 的后缀链接指向 , 的后缀链接继承原来 的后缀链接。
因为 继承了 的大部分信息,在有些博客中这个节点被称作 (克隆)。
同时,其他状态的转移边也会发生一定改变(即实际情况为虚线所示),原本指向 的状态现在要指向 。
容易发现这样的状态一定可以通过 跳后缀链接迭代到达(包括 本身)。
为什么全部都要修改呢?因为 已经可以通过转移边指向 了,接下来遍历到的状态一定是 的后缀,
也就只能转移到 而不是 了。
现在, 的 便可以指向 了,可以把图左右对照来看。
至此,我们已经解决了插入字符的操作。
代码示例:
void Extend(int c) {
int p = Last, np = ++idx; Last = np;//Last , idx 初始值均为 1,即把 1 号状态作为空状态
len[np] = len[p] + 1;
while (p and !ch[p].count(c)) ch[p][c] = np, p = Link[p];
if (!p) Link[np] = 1;
else {
int q = ch[p][c];
if (len[q] == len[p] + 1) Link[np] = q;
else {
int nq = ++idx;
ch[nq] = ch[q], Link[nq] = Link[q];
len[nq] = len[p] + 1, Link[np] = Link[q] = nq;
while (p and ch[p][c] == q) ch[p][c] = nq, p = Link[p];
}
}
++num[np];
}
维护信息
子串出现次数
发现上面代码中的 数组了吗,它就是用来维护子串出现次数的,其实也就是 的大小。
同样的根据定义,一个状态(即等价类)中的子串出现次数是一样的。
因为 链接具有严格的后缀关系,所以它构成了一棵树,并且叶子状态就代表前缀。
(所以后缀自动机的 Link 树其实是前缀树)
对于一个等价类,如图:
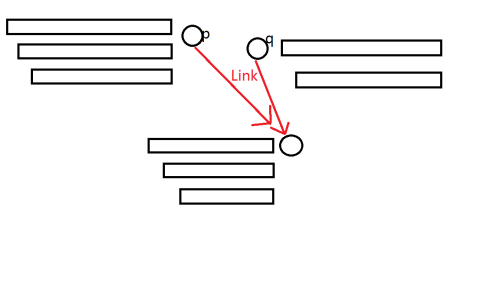
对于属于 的位置, 也一定出现了, 对 的贡献同理。
同时,因为 和 中的字符串本质不同,所以他们出现的位置也肯定不同,对 的贡献 。
不重是显然的,为什么不漏呢?
考虑对于每个状态的代表元素, 指向它的状态的最短子串,就是在这个代表元素前面接上不同的字符组成的,所以不漏。
不过这个结论有时是有问题的,就是对于每个前缀及与前缀在同一个等价类中的子串,它没有办法通过 在前面接上一个字符。
每次插入的前缀状态出现次数初始化为 ,然后对 树求子树和即可。
另外的,因为 边连接的状态长度具有严格的偏序关系,所以对长度进行计数排序后累加,就可以写成常数更小的非递归写法。
void Gets() {
lep(i, 1, idx) tot[len[i]]++; //idx 为 SAM 状态数
lep(i, 1, n) tot[i] += tot[i - 1];
lep(i, 1, idx) sa[tot[len[i]]--] = i;
rep(i, idx, 1) num[Link[sa[i]]] += num[sa[i]];
lep(i, 1, idx) if (num[i] > 1) ans = std::max(ans, num[i] * len[i]);
}
//Luogu P3804 答案统计部分
第 小子串
从空状态走转移边,就是一个在末尾添加字符的过程,不同的路径对应着不同的子串,并且同样是 。
所以求第 小子串即求第 小路径,所以类比平衡树求第 小。
具体的,先预处理出每条转移边能到达的状态数,然后 即可。
void Init() {
lep(i, 1, idx) ++tot[len[i]], sum[i] = (i != 1);
lep(i, 1, n) tot[i] += tot[i - 1];
lep(i, 1, idx) sa[tot[len[i]]--] = i;
rep(i, idx, 1) for (auto t : ch[sa[i]])
sum[sa[i]] += sum[t.second];
}
void Dfs(int u, int k) {
if (k <= (u != 1)) return;
k -= (u != 1);
for (auto t : ch[u]) { int v = t.second;
if (k > sum[v]) k -= sum[v];
else { putchar(t.first + 'a'); Dfs(v, k); return; }
}
}
//SP7258
本质不同的子串个数
所有状态中子串个数,因为等价类中长度连续,所以答案即为 。
void Extend(int c) {
int p = Last, np = ++idx; Last = np;
len[np] = len[p] + 1;
while (p and !ch[p].count(c)) ch[p][c] = np, p = Link[p];
if (!p) Link[np] = 1;
else {
int q = ch[p][c];
if (len[q] == len[p] + 1) Link[np] = q;
else {
int nq = ++idx;
ch[nq] = ch[q], Link[nq] = Link[q], len[nq] = len[p] + 1;
Link[np] = Link[q] = nq;
while (p and ch[p][c] == q) ch[p][c] = nq, p = Link[p];
}
}
ans += len[np] - len[Link[np]];
}//SP705
可以发现这是一个动态过程。
最小表示法
将原串 复制一份接到后面,求最小的长度为 的子串。
void Solve(int u, int len) {
if (len == n) return;
printf("%d ", ch[u].begin()->first);
Solve(ch[u].begin()->second, len + 1);
}//Luogu P1368
两个串的最长公共子串
对于其中一个串 建立后缀自动机,对于另一个串 ,我们试图对其的每一个前缀找到可以匹配的最大后缀长度 。
答案即为 。
考虑类似于 自动机的匹配过程,记录当前所处状态 和 。
我们处理到当前字符 ,如果 存在 的转移边,则转移,并且 。
如果不存在,我们尝试缩短 以匹配上 , 让 通过后缀链接访问其后缀状态,尝试匹配。
int Gets(int c) {
while (v != 1 and !ch[v].count(c)) v = Link[v], l = len[v];
if (ch[v].count(c)) v = ch[v][c], ++l;
}
void Solve() {
lep(i, 1, m) {
Gets(t[i] - 'a');
ans = std::max(ans, l);
}
}//SP1811
时间仓促,如有错误欢迎指出,欢迎在评论区讨论,如对您有帮助还请点个推荐、关注支持一下




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探
· 为什么 退出登录 或 修改密码 无法使 token 失效