
快速排序相比其他极大排序在效率和空间复杂度上都算是比较优得。并且在进行了三数取中优化以后,除了及其小的情况外,基本能保持logn的时间复杂度。
三数取中法;在一堆数据中随机取三个数,然后取其中间大小的数。
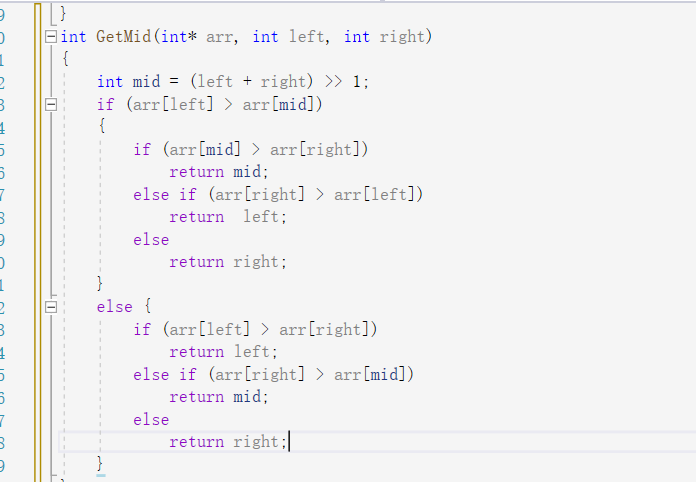
有了三数取中的基础以后,快速排序的key就可以用三数取中来完成了。
1:快速排序有三种常用的方法分别是:1:第一种方法(具体名字不太清楚)2:挖坑法3:快慢指针法。
1:首先是匿名的这种方法;这种方法的思路是,在数组中选取一个key,然后从数组两边开始从左边找到比key大的数,从右边找到比key小的数然后两个数互换,再继续向中间寻找,直到两指针相遇,将key的值放在相遇的点,再以key为分割点,分别向左右两个区间递归,直到将所有的数排好序。
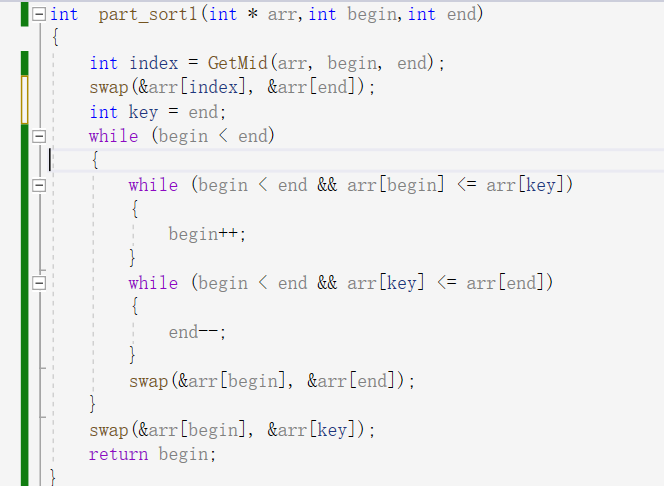
步骤:首先需要写其子函数部分:首先取三个数的下标计算出数组中中间大的那个数的下标index,然后将index与end互换,这里为什么必须要让index与end互换呢,若不呼唤就会出问题,最后key就会放错位置。此时end就是中间大的数了。
然后以begin<end为循环的进入条件,若begin<key则继续,意思就是在前面找到比key大的数停止循环,若end>key则继续,意思是再后面找到小于key的值就停止循环,然后begin与end互换,直到begin<end不成立为止,最后将key放在begin或end的位置,因为此时begin和end已经相遇,然后返回end。此时end位置的数已经到了他应该到的位置。
然后就是主递归函数,若是区间不存在就返回空,函数中定义一个div接受子函数的返回值,这个返回值的数位置是正确的,然后递归进入div的左右区间依次将所有的数放到他应该在的位置。就排序完成了。
下图是子递归函数,
这是主递归函数

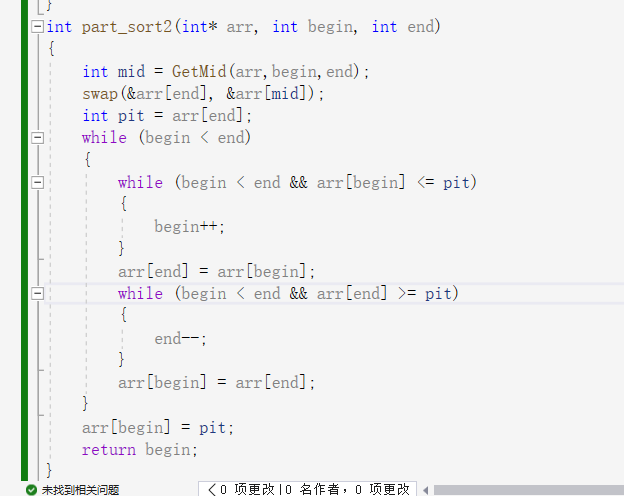
2:然后是第二种方法:挖坑法,这种方法与第一种方法大同小异这种方法思路是同样用三数取中法设定一个key,但是这里将key赋给一个临时变量,此时key所在的位置就变成了”坑“,从左边找到一个比key大的数放到坑里,从右边找到一个比key小的值放到坑里,直到begin和end相遇,此时将key放到相遇的位置,就完成一次排序了。
之后就是用返回值进行递归:
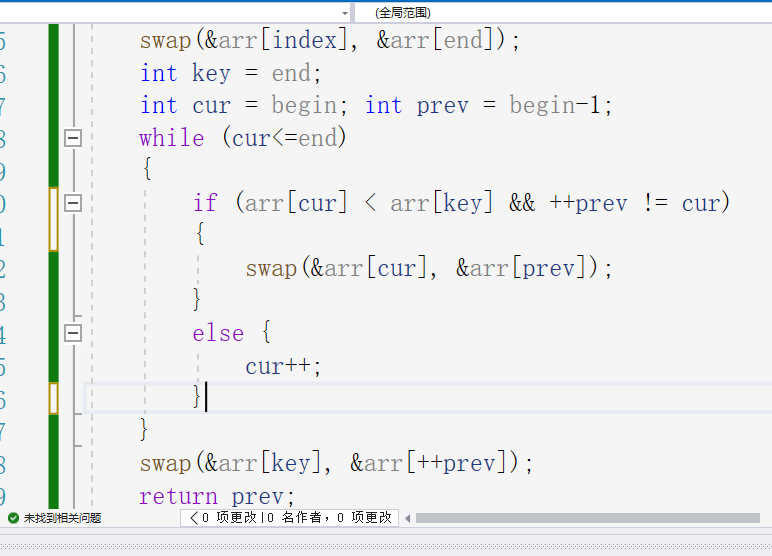
3:快慢指针法,这个方法比较怪,具体步骤是这样子的,先是老规矩三数取中找到key,再定义一个prev再定义一个cur从begin开始向end走,初始定义的prev比cur要少一,首先若cur的值比key小,且prev自增后不等于cur就让cur与prev交换,然后再次判断,本来对这里后半段语句不理解,当去掉这半句后,发现cur总是不能自增,所以这里还有一个作用是,让prev自增后若与cur相等给cur创作自增的条件,做的过程中若cur的值比key小它们就交换,不然cur就继续走,直到cur走出去,然后prev与key交换,完成第一次排序。
快速排序相比于其他几大排序无论是时间复杂度与空间复杂度都分别有一定的优势。
冒泡排序基本上没多大用,基本用于新手过度。
希尔排序是插入排序的优化版,代码简单,适合理清思路。
堆排序本质是一种选择排序,它利用了树形结构,可以用来在海量数据中选取特定大小的序列。
归并排序的时间复杂度很稳定但是他额外要求了空间复杂度。
快速排序的特点就是快速,但是有时候也是不稳定的,但是处理一般的数据也够了,基本上库里也就用的是快速排序。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人