
并发编程之进程
一、什么是进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作
系统结构的基础
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。
注意:同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱。
二、进程调度
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
先来先服务(FCFS)调度算法:对长作业有利,对短作业无益 短作业(进程)优先调度算法(SJ/PF):对短作业有利,多长作业无益
时间片轮转法+多级反馈队列:
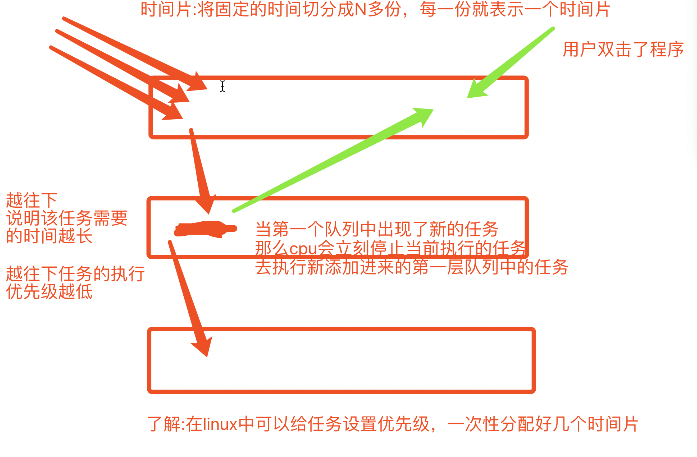
三、进程的并发与并行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是
cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
并行:同时运行,只有具备多个cpu才能实现并行

四、同步\异步and阻塞\非阻塞
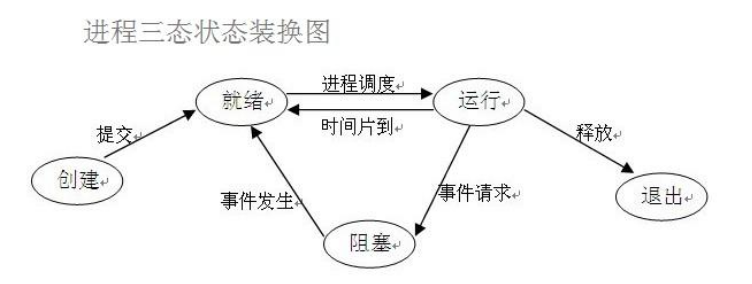
在了解其他概念之前,我们首先要了解进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。 (1)就绪(Ready)状态 当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。 (2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。 (3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种
例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
同步和异步:
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务
序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。
所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,
只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以
它是不可靠的任务序列。
阻塞与非阻塞:
阻塞和非阻塞这两个概念与程序(线程)等待消息通知(无所谓同步或者异步)时的状态有关。也就是说阻塞
与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的
# 同步/异步与阻塞/非阻塞
同步阻塞形式 效率最低。举例子来说,就是你专心排队办银行业务,什么别的事都不做。 异步阻塞形式 如果在银行等待办理业务的人采用的是异步的方式去等待消息被触发(通知),也就是领了一张小纸条,假如在这段时间里他不能离开银行做其它的
事情,那么很显然,这个人被阻塞在了这个等待的操作上面;异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞
同步非阻塞形式
实际上是效率低下的。想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要
在这两种不同的行为之间来回的切换,效率可想而知是低下的。
异步非阻塞形式
效率更高,因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
比如说,这个人突然发觉自己烟瘾犯了,需要出去抽根烟,于是他告诉大堂经理说,排到我这个号码的时候麻烦到外面通知我一下,那么他就没有被阻塞在这个等待的
操作上面,自然这个就是异步+非阻塞的方式了。
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。
五、python创建进程的两种方式
multiprocess模块不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎
包含了和进程有关的所有子模块,我们用的是process模块。process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'python',)
4 kwargs表示调用对象的字典,kwargs={'name':'python','age':18}
5 name为子进程的名称


1 p.start():启动进程,并调用该子进程中的p.run() 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 4 p.is_alive():如果p仍然运行,返回True 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
在一个python进程中开启子进程,start方法和并发效果:
方式一: from multiprocessing import Process import time def task(name): print('%s is running'%name) time.sleep(3) print('%s is over'%name) if __name__ == '__main__': # 1 创建一个对象 p = Process(target=task, args=('name',)) # 容器类型哪怕里面只有1个元素 建议要用逗号隔开 # 2 开启进程 p.start() # 告诉操作系统帮你创建一个进程 异步 print('主进程')
方式二:类的继承 from multiprocessing import Process import time class MyProcess(Process): def run(self): print('hello word') time.sleep(1) print('get out!') if __name__ == '__main__': p = MyProcess() p.start() print('主进程')
join方法:让主进程等待子进程代码运行结束之后,再继续运行。不影响其他子进程的执行
import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) print('我是子进程') if __name__ == '__main__': p = Process(target=f, args=('aaa',)) p.start() p.join() print('我是父进程')
多个进程同时运行(注意,子进程的执行顺序不是根据启动顺序决定的)
import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': p_lst = [] for i in range(5): # 使用for循环 p = Process(target=f, args=('aaa',)) p.start() p_lst.append(p)
多进程同时运行的join方法:
import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': p_lst = [] for i in range(5): p = Process(target=f, args=('aaa',)) p.start() p_lst.append(p) [p.join() for p in p_lst] print('父进程在执行')
进程之间的数据隔离问题:
from multiprocessing import Process money = 100 def task(): global money # 局部修改全局 money = 666 print('子进程',money) if __name__ == '__main__': p = Process(target=task) p.start() p.join() print(money)
六、进程对象及其方法介绍
一台计算机上面运行着很多进程,那么计算机是如何区分并管理这些进程服务端的呢? 计算机会给每一个运行的进程分配一个PID号 如何查看: windows电脑 进入cmd输入tasklist即可查看 tasklist |findstr PID查看具体的进程 mac电脑 进入终端之后输入ps aux ps aux|grep PID查看具体的进程 from multiprocessing import Process, current_process current_process().pid # 查看当前进程的进程号 import os os.getpid() # 查看当前进程进程号 os.getppid() # 查看当前进程的父进程进程号 p.terminate() # 杀死当前进程 # 是告诉操作系统帮你去杀死当前进程 但是需要一定的时间 而代码的运行速度极快 time.sleep(0.1) print(p.is_alive()) # 判断当前进程是否存活
七、僵尸进程与孤儿进程
# 僵尸进程
死了但是没有死透
当你开设了子进程之后 该进程死后不会立刻释放占用的进程号
因为我要让父进程能够查看到它开设的子进程的一些基本信息 占用的pid号 运行时间。。。
所有的进程都会步入僵尸进程
父进程不死并且在无限制的创建子进程并且子进程也不结束
回收子进程占用的pid号
父进程等待子进程运行结束
父进程调用join方法
# 孤儿进程
子进程存活,父进程意外死亡
操作系统会开设一个“儿童福利院”专门管理孤儿进程回收相关资源
八、守护进程
守护进程会随着主进程的结束而结束。
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError:
daemonic processesare not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
from multiprocessing import Process import time def task(name): print('%s正在活着'% name) time.sleep(3) print('%s正在死亡' % name) if __name__ == '__main__': p = Process(target=task,args=('公公',)) # p = Process(target=task,kwargs={'name':'公公'}) p.daemon = True # 将进程p设置成守护进程 这一句一定要放在start方法上面才有效否则会直接报错 p.start() print('太上皇寿终正寝')
九、互斥锁
多个进程操作同一份数据的时候,会出现数据错乱的问题
针对上述问题,解决方式就是加锁处理:将并发变成串行,牺牲效率但是保证了数据的安全
from multiprocessing import Process, Lock import json import time import random # 查票 def search(i): # 文件操作读取票数 with open('data','r',encoding='utf8') as f: dic = json.load(f) print('用户%s查询余票:%s'%(i, dic.get('ticket_num'))) # 买票 1.先查 2.再买 def buy(i): # 先查票 with open('data','r',encoding='utf8') as f: dic = json.load(f) # 模拟网络延迟 time.sleep(random.randint(1,3)) # 判断当前是否有票 if dic.get('ticket_num') > 0: # 修改数据库 买票 dic['ticket_num'] -= 1 # 写入数据库 with open('data','w',encoding='utf8') as f: json.dump(dic,f) print('用户%s买票成功'%i) else: print('用户%s买票失败'%i) # 整合上面两个函数 def run(i, mutex): search(i) # 给买票环节加锁处理 # 抢锁 mutex.acquire() buy(i) # 释放锁 mutex.release() if __name__ == '__main__': # 在主进程中生成一把锁 让所有的子进程抢 谁先抢到谁先买票 mutex = Lock() for i in range(1,11): p = Process(target=run, args=(i, mutex)) p.start()
注意:
1.锁不要轻易的使用,容易造成死锁现象(我们写代码一般不会用到,都是内部封装好的)
2.锁只在处理数据的部分加来保证数据安全(只在争抢数据的环节加锁处理即可)
十、进程间通信——队列(multiprocess.Queue)
进程间通信:IPC(Inter-Process Communication)
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
from multiprocessing import Queue # 创建一个队列 q = Queue(5) # 括号内可以传数字 标示生成的队列最大可以同时存放的数据量 # 往队列中存数据 q.put(111) q.put(222) q.put(333) # print(q.full()) # 判断当前队列是否满了 # print(q.empty()) # 判断当前队列是否空了 q.put(444) q.put(555) # print(q.full()) # 判断当前队列是否满了 # q.put(666) # 当队列数据放满了之后 如果还有数据要放程序会阻塞 直到有位置让出来 不会报错 # 去队列中取数据 v1 = q.get() v2 = q.get() v3 = q.get() v4 = q.get() v5 = q.get() # print(q.empty()) # V6 = q.get_nowait() # 没有数据直接报错queue.Empty # v6 = q.get(timeout=3) # 没有数据之后原地等待三秒之后再报错 queue.Empty try: v6 = q.get(timeout=3) print(v6) except Exception as e: print('一滴都没有了!') # # v6 = q.get() # 队列中如果已经没有数据的话 get方法会原地阻塞 # print(v1, v2, v3, v4, v5, v6)
from multiprocessing import Queue, Process """ 研究思路 1.主进程跟子进程借助于队列通信 2.子进程跟子进程借助于队列通信 """ def producer(q): q.put('我是23号技师 很高兴为您服务') def consumer(q): print(q.get()) if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) p1 = Process(target=consumer,args=(q,)) p.start() p1.start()
from multiprocessing import Process, Queue, JoinableQueue import time import random def producer(name, food, q): for i in range(5): data = '%s生产了%s%s' % (name, food, i) # 模拟延迟 time.sleep(random.randint(1, 3)) print(data) # 将数据放入 队列中 q.put(data) def consumer(name, q): # 消费者胃口很大 光盘行动 while True: food = q.get() # 没有数据就会卡住 # 判断当前是否有结束的标识 # if food is None:break time.sleep(random.randint(1, 3)) print('%s吃了%s' % (name, food)) q.task_done() # 告诉队列你已经从里面取出了一个数据并且处理完毕了 if __name__ == '__main__': # q = Queue() q = JoinableQueue() p1 = Process(target=producer, args=('大厨1', '包子', q)) p2 = Process(target=producer, args=('大厨2', '泔水', q)) c1 = Process(target=consumer, args=('消费者1', q)) c2 = Process(target=consumer, args=('消费者1', q)) p1.start() p2.start() # 将消费者设置成守护进程 c1.daemon = True c2.daemon = True c1.start() c2.start() p1.join() p2.join() # 等待生产者生产完毕之后 往队列中添加特定的结束符号 # q.put(None) # 肯定在所有生产者生产的数据的末尾 # q.put(None) # 肯定在所有生产者生产的数据的末尾 q.join() # 等待队列中所有的数据被取完再执行往下执行代码 """ JoinableQueue 每当你往该队列中存入数据的时候 内部会有一个计数器+1 没当你调用task_done的时候 计数器-1 q.join() 当计数器为0的时候 才往后运行 """ # 只要q.join执行完毕 说明消费者已经处理完数据了 消费者就没有存在的必要了

