
路由器等NAT设备中TIME_WAIT套接字分析
在TCP连接断开的四次挥手中,套接字的TIME_WAIT阶段经常在各种考题和Linux系统优化中出现,本文主要针对路由器类(NAT)设备的TIME_WAIT状态进行分析,并指出一些常见误区和优化建议,希望起到抛砖引玉的效果。
基础知识介绍
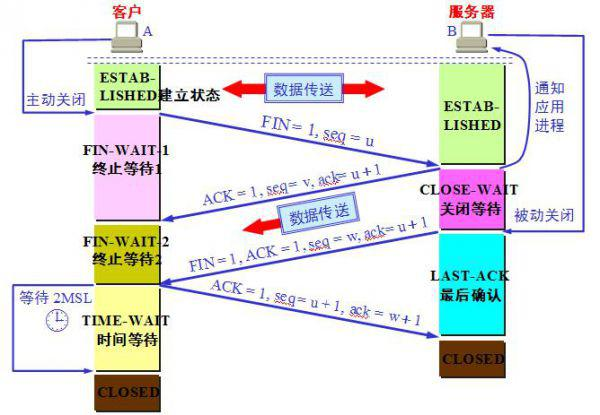
TCP四次挥手的如上图所示,可以看出,该状态时长为2MSL,具体时间不同操作系统有差别,主流Linux系统上为60秒。设置该状态的原因有二:为实现TCP全双工连接的可靠释放,以及使旧的数据包在网络因过期而消失,更详尽的信息可自行查阅资料。
常见误区
-
TIME_WAIT是服务器上才会大量出现的
这种说法并不准确。TIME_WAIT是“断开连接”的一方进入的状态,那么设备是个人PC还是云服务器都不重要,只要它成为TCP的断开发起者,就可能进入TIME_WAIT。简要来说,TIME_WAIT的出现不在于设备“是什么”,而在于它扮演的“角色”。
例如,一个静态网页服务器,其所有资源都在本地磁盘上(这点很重要,意味这该服务器不需连接第三方),且断开是由用户发起的,那这台服务器上完全可能没有TIME_WAIT;而一台FTP服务器,则可能产生大量TIME_WAIT状态,因为FTP传输结束的挥手是服务端开始的。
-
TIME_WAIT多了后设备会无法接受新连接
有可能,具体情况比较复杂。一方面,Linux是有最大文件打开数限制的,而处于某一状态的连接过多就容易触发too many files open,这时新连接自然进不来了。TIME_WAIT状态过多是一种情况,但其他状态也可能造成同样的现象。
另一方面,TIME_WAIT连接也是占着端口号的,往往是一个五位数的随机端口号,而Linux对向外端口号的分配有一个范围,由net.ipv4.ip_local_port_range确定,默认值不到3w个,这个范围的端口号被用完了会导致服务器无法建立对外的新连接,但在那些已分配的端口上进入的新连接不受影响(前提是没触碰最大文件打开数之类的限制)。
以一台HTTP正向代理服务器为例,在产生足够多TIME_WAIT套接字时,它监听的HTTP代理端口上接受新的代理连接理论上不会受影响,但向原始服务器发起新请求会无法进行。
-
通过修改Linux内核参数/proc/sys/net/ipv4/tcp_fin_timeout可以减少TIME_WAIT时间
不可以。有些教程会建议修改/etc/sysctl.conf文件,增加net.ipv4.tcp_fin_timeout = {比60更小的数},这样做是无效的。
tcp_fin_timeout指的是FIN_WAIT_2的时间,在TCP标准中这个等待本来是没有超时的,只是大多数OS实现了超时功能,并且Linux中这个值恰好也是60(有些发行版可能比60小),但它与TIME_WAIT的60并没有什么联系(有些教程说修改tcp_fin_timeout是修改TIME_WAIT的显示值也不对,还是没搞明白两者根本不是一个东西)。真正想修改通常只能在编译Linux内核时更改,其定义在include/net/tcp.h文件里,#define TCP_TIMEWAIT_LEN (60*HZ) 。
然而值得注意的是,某些内核(比如阿里云)加入了tcp_tw_timeout,可以动态修改TIME_WAIT。
-
主动断开连接的一方必定经历TIME_WAIT阶段
不一定。在Linux中实现了FIN_WAIT2阶段的超时tcp_fin_timeout,如果超时时间内对端没有发送FIN,这个连接会在FIN_WAIT2超时后直接消失掉(默认状态是这样,如果修改了tcp_fin_timeout为更大的值,在较新内核中会有不一样的表现,详情可参考这篇文章)。
此外,TIME_WAIT数量达到tcp_max_tw_buckets后,新的连接由于无法再进入TIME_WAIT会直接关闭。
-
TIME_WAIT状态只有在超时时间过后才会消失
并不是,有几种例外:
- net.ipv4.tcp_tw_reuse = 1会开启TIME_WAIT套接字重用,某种程度上也算提前消失了。
- net.ipv4.tcp_tw_recycle = 1会开启TIME_WAIT套接字回收,有些教程会建议将该参数开启,但容易在NAT场景中出现问题, linux 内核 4.12 版本已经去掉了 net.ipv4.tcp_tw_recycle。
路由器中的TIME_WAIT
SSH连接一台路由器(192.168.1.1),查看当前活动连接
netstat -antpl
会发现结果很少,那么局域网用户建立的连接都去哪儿了呢?这里要涉及到连接跟踪表nf_conntrack,它会记录NAT的返回路径,相关介绍推荐这篇和这篇文章。
cat /proc/net/nf_conntrack
可以看到这里记录了所有局域网内、局域网-公网连接,可以看到这里所列连接的src和dst都没有192.168.1.1的(除了这条SSH连接),所以显示本机统计数据的netstat并未记录。在返回结果里我们能看到许多处于TIME_WAIT状态的连接,我们随机截取一条:
ipv4 2 tcp 6 117 TIME_WAIT src=192.168.1.192 dst=114.114.114.114 sport=57560 dport=3821 packets=4758 bytes=334836 src=114.114.114.114 dst=121.47.114.69 sport=3821 dport=57560 packets=3431 bytes=538831 [ASSURED] mark=0 use=2
114.114.114.114是公网上的一台服务器,内网主机192.168.1.192连接到其3821端口的某个服务,121.47.114.69是路由器分配到的地址。在192主机手动断开连接后,192主机上的对应TCP连接在挥手中很快来到TIME_WAIT,而nf_conntrack中的对应连接,也作为114服务器的客户端,同样进入TIME_WAIT。
有趣的是,Linux中默认的TIME_WAIT时间都是60s,但这里却是120s!这说明nf_conntrack跟踪的连接似乎不使用内核配置的参数,事实也是如此。以华硕路由器为例,其默认值如下图:
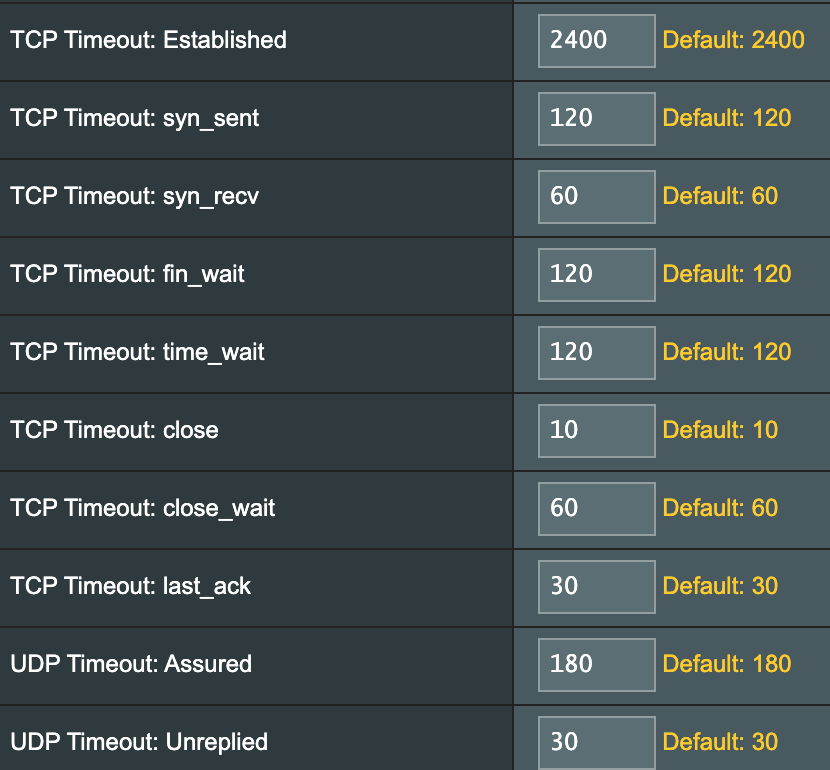
这里设置的超时值可能导致NAT环境下的TCP连接产生一些问题,比如Linux中的established timeout是7200,而这里是2400,所以某些时候我们明明为SSH设置了大于TCP超时的心跳包interval,却仍旧发生意外断线,可以检查下是否interval大于了路由器的established timeout。
图中参数也可以通过操作文件的方法进行修改,位于/proc/sys/net/netfilter/下。一般来说,由于这里的TIME_WAIT timeout长达120秒,在路由器后用户与公网服务器短时间内大量创建-关闭TCP连接的场景下(比如以http 1.0协议访问网站),会很快在nf_conntrack中积累起大量TIME_WAIT,这可能导致两个结果:
- nf_conntrack_expect(专门为一些特殊协议开启的穿透连接,比如主动FTP的NAT穿透)超过nf_conntrack_expect_max,跟踪表溢出。
- 跟踪表总连接数达到nf_conntrack_max,跟踪表溢出。
两个结果都会表现为路由器开始丢包,为了避免这种情况,我们可以适当调大nf_conntrack_expect_max和nf_conntrack_max值,也可以减少nf_conntrack_tcp_timeout_time_wait;而nf_conntrack_max又与nf_conntrack_buckets的值有一定关系,具体可参加这篇文章。
Nginx产生的TIME_WAIT
在被配置为proxy_pass的Nginx中,请求的转发与NAT过程有些形似。假设有A、B、C三台主机,A作为客户端访问B,B上的Nginx代理了C网站,则在A访问结束后,在B上netstat可看到一条B到C处于TIME_WAIT的连接,超时时间是Linux默认的60s,A到B的则已迅速关闭了;而在nf_conntrack中,则记录了两条TIME_WAIT状态,分别是A到B的和B到C的,超时时间均为120s。这说明Nginx的proxy_pass与路由器NAT转发的原理有根本性差异,它实打实地在本地建立了两条TCP连接,且其转发也不依赖nf_conntrack的记录。
而如果在location区块中未配置使用http1.1与后端服务器通信,Nginx将使用http1.0,所以TCP关闭将由后端服务器发起,于是在nf_conntrack中我们能看到C到B的TIME_WAIT连接,而netstat在B上并看不到C、B间的TIME_WAIT;但可能看到A与B的TIME_WAIT,这是因为A的浏览器会以http1.1建立与Nginx的连接,默认开启keepalive,所以TCP连接建立后会维持一段时间留待复用,直到闲置时间达到Nginx设置的keepalive,这时由Nginx主动关闭TCP连接,在B上可能看到TIME_WAIT。

