
一、前言
本单元围绕着规格化设计开展本单元围绕着“规格化设计”展开,从简单的JML入手,逐步扩展规格化设计的内容。第一次作业是实现一个简单的路径容器,第二次作业在基于路径容器的基础上实现了一个图,第三次作业则深入到应用层级,实现了一个地铁线路查询程序,进一步的与现实贴近
二、JML知识梳理
初次认识到JML规格我的想法仅仅是:这不就是告诉你这个方法该怎么写了么,自己把这些伪代码翻译成正常的代码不就得了,但是后来我发现事情远远没有这么简单,尤其是对于第一次作业来说一半的测试点都TLE,JML的规格说明不仅仅是方法流程,不可能完全的照搬,按照规格中的数据结构实现更是会造成更大的问题。

那么JML(Java Modeling Language)到底是什么呢?“在面向对象编程中,一个重要原则就是尽可能地推迟对于“过程”的思考。”Java建模语言在Java代码中增加了一些符号,这些符号用来标识一个方法是干什么的,却并不关心它的实现。如果使用JML的话,我们就能够描述一个方法的预期的功能而不管他如何实现。通过这种方式,JML把过程性的思考延迟到方法设计中,从而扩展了面向对象设计的这个原则。比如对于getLeastTicketPrice方法(上图),它带给我的结果是一个思路,按照这个思路走,我的目的是得到正确的result和异常抛出。JML在代码中增加了一些符号,这些符号只表述一个方法干什么,并不关系它的实现过程。使用JML,我们就可以描述对于某一个方法的预期功能,却不管实现过程,JML可以把过程性的思考延迟到方法设计中,这点完全符合了“面向对象”。
那么JML带给我们的好处都有什么呢
- 增加代码的可读性,至少让他人能明白你这个方法的输入和输出,在使用你所书写的这个方法也会变得便利
- 更加符合面向对象的思想,把过程化的思维放在具体实现方法的过程中
- 能够避免一些bug,并且可以针对前置条件后置条件进行测试
三、JML的理论基础
JML的功能及其强大,其主要靠关键字和符号来标识一个方法究竟是干什么的。
JML标记是卸载java代码的注释中的。包含JML标记的多行注释以/*@开头,JML忽略任何以@开头的空行。如果是单行的话,可以使用//@这种标记。
其中主要是前置条件和后置条件,
前置条件表示调用一个方法前必须满足的一些要求。
后置条件规范表示一个方法的责任,也就是当这个方法返回时,它必须满足这个后置条件的要求。
而其次就是ensure关键字,其后面跟着的是方法返回时必须满足的后置条件。
在这些其中则是灵活的运用一些关键字/result:返回值 /old 方法调用前的参数 /forall 等等。
四、JML的工具链
JML拥有很多好用的工具,可以提供JML规范检查,或者是生成测试数据进行测试,我对其中一些工具了解的也不是很多,在其中我接触的比较多的就是junit用起来测试你完成的方法,但是需要自己编写一些测试点。

这是其中对Path类中的getNode进行测试的一个例子,利用junit进行测试基本都很好编写,只需要了解JML的规格定义以及生成一些合适的测试。
五、架构分析
1. 第一次作业的时候由于没有明白具体的测试点都是什么样的,只考虑了正确性,对于时间复杂度之类的完全没有考虑,测试完每个方法的正确性之后就溜之大吉了,基本上采用的都是ArrayList不论是equal、Discount Node 都采用的是ArrayList 这极大的加大的时间复杂度基本上都是O(n),其中完全没用到HashMap这一利器。

在架构方面我也并没有想到为之后的功能拓展预留余地,虽说从第一次作业已经能看出来这一单元和图的计算和查找有关,懒惰和蠢笨就不在此多说了。
2. 第二次作业相比第一次作业增加了图最短路径的查询,一下子从一维路径转为二维图,在经历了上次的惨败后,在这一次作业中我对于其中的很多数据结构都进行了优化,避免了之前的全部ArrayList的简单粗暴,改为HashMap这一增删查时间复杂度都为O(1)的结构。其次是在算法层面进行了优化,对于最短路径采用的是邻接矩阵的幂来求出最短路径。然而由于为了降低空间复杂度和时间复杂度我在对于邻接矩阵的存储采用了 这一方法来存储,好处是极大的降低了时间复杂度,但是在编写代码的时候往往一个走神就忘了自己在写的是哪一部分,这个是元素的行值还是列值。
这一方法来存储,好处是极大的降低了时间复杂度,但是在编写代码的时候往往一个走神就忘了自己在写的是哪一部分,这个是元素的行值还是列值。
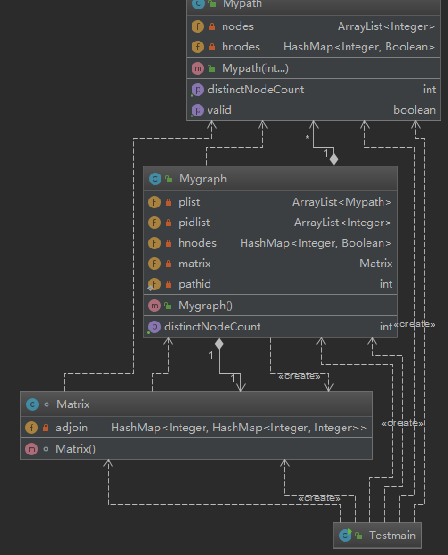
当然,这次将图的计算放在了单独的一个类中,同时也是为下一次作业预留出地方。
3. 第一眼看到第三次作业感觉难度一下就上来了,毕竟第二次作业仅仅添加了一个功能,而第三次作业则包括了连通块、最低票价、最少换乘和最少不满度四种强大的功能查询。但仔细想想无非就是改一下两个节点之间的边权对于不同的问题可以造出一个不同边权的邻接图以此来进行算法上的计算,这只需要对Matrix类中存储矩阵的hashmap进行一下优化即可,增加Node类代表每一个点的信息,而由于更换成了Floyd算法,整体的修改就不多。

五、有关bug
- 自己的bug
在自己测试的过程中,bug主要体现在算法没有优化,因此TLE,最初在编写ADD_PATH的时候没有进行特判,只要是对图结构进行修改的指令都会对整体矩阵进行修改,这极大地增加了时间复杂度,其次是对于一些特别路径的操作没有提前想清楚,造成了写完代码后才发现bug,比如说环形路径和带环形路径的路径,其次则是关于连通块的计算,最初的方案并没有考虑到新添加的路径会让之前两个原本不连通的路径变得连通,其次是在进行图的增添路径操作后要记得更新矩阵和点以及连通块的状态,这也是极为容易出错的。
- hack
本此虽然没有被别人hack但是原因主要全部出在超时方面,在不了解ArrayList的底层实现之前以为是O(1)的复杂的所以用的很多,了解之后才发现ArrayList的equal和一些方法的实现和自己理解中的不同,这也是之后需要注意的,不要想当然,其次就是关于时间复杂度的降低,有时候一个语句就能造成TLE在编写的时候一定要注意不要因为怕麻烦就混用同一个更新算法,造成重复计算,也就是要灵活运用之前计算的结果。
六、感想
本单元是关于JML规格的应用和理解,总的来说收获颇丰,不论是最后一次作业的地铁查询系统的贴近现实以及功能的丰富性,还是对于实现方法的理解都让我对java编程的了解更近一步。而且通过这次作业更能意识到实际上在工程领域中,各类数据结构最常见的存在形式,恰恰就是面向对象的形式,你们使用的HashMap等数据结构就是最好的例子。而对于数据结构对象而言,正确性、复杂度性能、工程性的平衡折中,则是极为重要的,也是最能体现设计水准的(套用作业指导书原话)。很多时候不是写出了算法,这个算法能得出结论就够了,往往还会对时间有需求,对代码的复用性有需求,这些都是我在之前的作业中所没感受到的,毕竟这单元作业我感受到的最大的bug就是防止TLE。综上,编程不仅仅是写代码,往往还涉及架构、算法、优化、接口、复用等等一切都是需要考虑的,希望我能在之后的一个单元努力完成之前的一些想法,减少代码的重构,想的多一些,不过总的来说这一单元的作业还是很让人感到舒适的,可能是因为终于用到了大一学的数据结构??

 浙公网安备 33010602011771号
浙公网安备 33010602011771号