第一次个人编程作业
作业呈上
- GitHub链接🔗点击链接进入我的GitHub仓库
- 点击博客左上角的那只猫进入我的GitHub首页
- 可运行的Jar包已发布至release
- 开发平台、环境、工具以及开发者日志等详情在仓库中的README.md中查看
- 博客写的很潦草,我后续或许还会更新,代码也是
计算模块接口的设计与实现过程
整体流程
- 首先呢,我先用土的不能再土的方式展现我的设计思路及流程
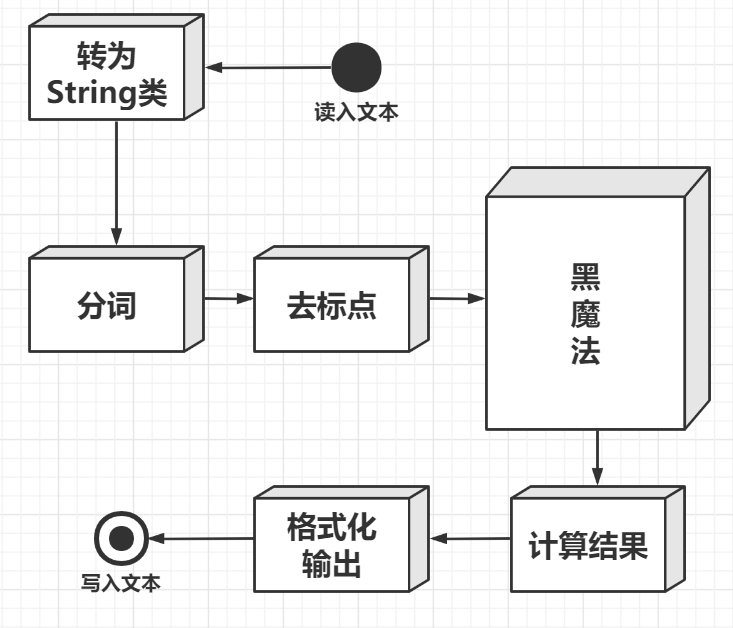
WTF???什么是黑...
咱先不管这个黑魔法是什么,总之就是我的核心算法,我们应该先集中精力把不属于算法的部分(也就是框架)先搞定,不是吗?这样才有精力专心来搞算法。
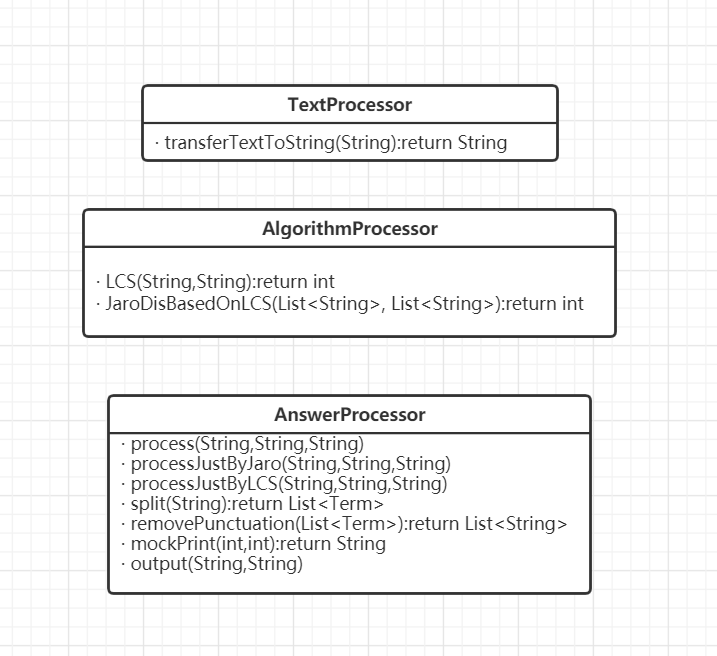
emm...这样或许真的太大白话了,那我具体一点,把它换上我的类和具体实现方法,也顺便展示出我代码中各个类、方法的关系
(0)先展示一下我的类(没有属性,主要还是静态方法,当工具用了)
- TextProcessor:文本处理器,输入文本文件,转字符串
- AlgorithmProcessor:算法处理器,集中用来写算法
- AnswerProcessor:答案处理器,也是最大块的,通过调用TextProcessor和AlgorithmProcessor中的方法,以及自己的一些私有静态方法,集中处理各种字符串和集合,最后输出
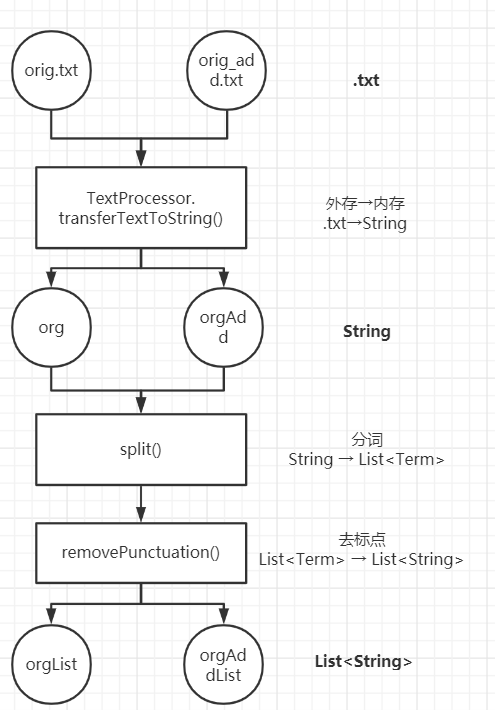
(1)输入硬盘中的.txt → 内存中的String → 分词后的List < String > 集合
(2)分词后的List < String > 集合 → int结果 → 计算出查重率float → 输出到硬盘中的.txt
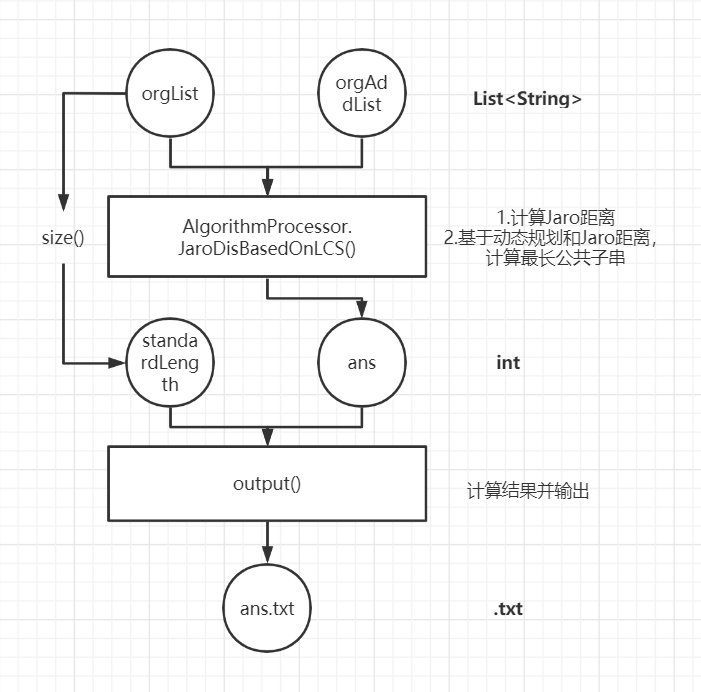
我不知道我这一通狂说有没有说清楚具体流程(除了算法),希望我的图文能说明白,那我下面要说最关键的算法了
核心算法
我先亮方法了,我使用的算法主要是两个的结合体:
- LCS,也就是基于动态规划的最长公共子串
- Tokenizer,是HanLP家的,用来做分词操作
- Jaro-Whinkle距离,是一个计算文本相似度的算法,是Apache家的
嗯,没错,我听从柯老板,我选择了拥抱开源
我们按顺序来说吧!
- 首先是LCS
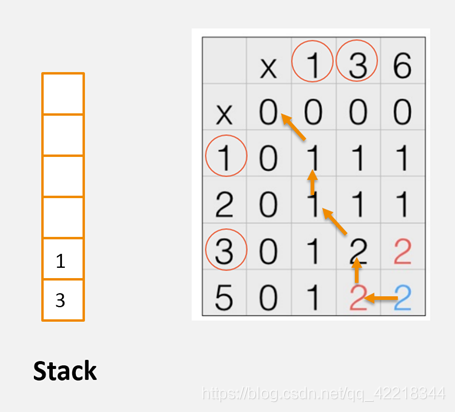
LCS的基本实现思想是,取两个字符串的字符一一比对,若两者相同则令S [i] [j] = S [i] [j] + 1,否则S [i] [j] = max(S [i-1] [j] , S [i] [j-1]),这也是符合LCS的推导公式的。而得到最长相同子串的方法是通过数据结构的栈实现的,因为一般的实现会记录字符的方向,而输出字符串是要从S矩阵的右下角逆序输出,因此很契合栈的结构,其规则是:若S1[i] = S2[j],将字符入栈,否则对比S [i] [j-1]和S [i-1] [j]的大小,若前者不大于后者则遍历后者。(具体详说可以参考这篇博文)
- 再来是HanLP家的Tokenizer,和jieba类似。
这个东西我不想说太多,因为这个不是算法关键所在,属于核心处理前的预处理,分词,大概呢就是基于字符串匹配、理解、统计、规则一系列的方式给他切好,我们这边只是把它当工具来用,并不打算讲太多。
- 最后就是Jaro-Whinkle距离,也是我们的核心所在,虽然它是我调用的工具包,但是它是核心的一部分!所以我会多说点!
我们先说定义:
Jaro Distance也是字符串相似性的一种度量方式,也是一种编辑距离,Jaro 距离越高本文相似性越高;而Jaro–Winkler distance是Jaro Distance的一个变种。其定义如下:
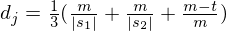
其中
- m是匹配数目(保证顺序相同)
- |s|是字符串长度
- t是换位数目
其中t换位数目表示:两个分别来自S1和S2的字符如果相距不超过

我们就认为这两个字符串是匹配的;而这些相互匹配的字符则决定了换位的数目t,简单来说就是不同顺序的匹配字符的数目的一半即为换位的数目t,举例来说,MARTHA与MARHTA的字符都是匹配的,但是这些匹配的字符中,T和H要换位才能把MARTHA变为MARHTA,那么T和H就是不同的顺序的匹配字符,t=2/2=1。
而Jaro-Winkler则给予了起始部分就相同的字符串更高的分数,他定义了一个前缀p,给予两个字符串,如果前缀部分有长度为 的部分相同,则Jaro-Winkler Distance为:
- dj是两个字符串的Jaro Distance
- l是前缀的相同的长度,但是规定最大为4
- p则是调整分数的常数,规定不能超过0.25,不然可能出现dw大于1的情况,Winkler将这个常数定义为0.1
举个简单的例子:
计算 的距离
的距离
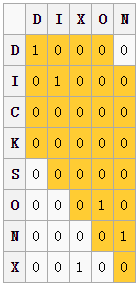
我们利用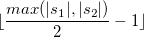 可以得到一个匹配窗口距离为3,图中黄色部分便是匹配窗口,其中1表示一个匹配,我们发现两个X并没有匹配,因为其超出了匹配窗口的距离3。我们可以得到:
可以得到一个匹配窗口距离为3,图中黄色部分便是匹配窗口,其中1表示一个匹配,我们发现两个X并没有匹配,因为其超出了匹配窗口的距离3。我们可以得到:
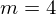

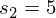
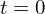
其Jaro score为:
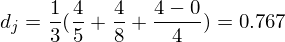
而计算Jaro–Winkler score,我们使用标准权重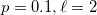 ,其结果如下:
,其结果如下:

疑问
你可能会问,为什么这边有两个算法好像都是在算文本相似度的?不,我们可以把它们两个结合,具体分析可以看下面的性能改进部分。我们把LCS判断相等的条件,换成计算两个词的Jaro距离得分,按经验分析,如果大于0.6,我们就认为它相似,执行原来LCS相等条件的部分。
小总结
我再总结一下吧,大概就是这样:
- 读进来,给他分词,把标点抽掉,就留词组
- 比较两个词组的集合,计算Jaro距离得分,大于0.6,认为他们相似,执行LCS的相等逻辑
- 计算结果,输出去
计算模块接口部分的性能改进
我们先谈算法准确度,先不谈性能嗷!
我们知道Jaro和LCS都是计算文本相似度一类的算法,那我们可以各单独跑一遍看看,咱们先跑纯LCS:
- 测试代码
/**
* 测试全部样例(纯LCS)
*/
@Test
public void testForAllFilesOnlyLCS(){
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file : files){
if(!file.equals("orig.txt")){
System.out.println("开始处理"+file);
AnswerProcessor.processJustByLCS("tests/orig.txt","tests/"+file,"result/ans"+cnt+".txt");
cnt++;
}
}
}
- 控制台输出结果
开始处理orig_0.8_add.txt
查重率为:1.00
结果已写入result/ans1.txt
开始处理orig_0.8_del.txt
查重率为:0.84
结果已写入result/ans2.txt
开始处理orig_0.8_dis_1.txt
查重率为:0.97
结果已写入result/ans3.txt
开始处理orig_0.8_dis_10.txt
查重率为:0.85
结果已写入result/ans4.txt
开始处理orig_0.8_dis_15.txt
查重率为:0.70
结果已写入result/ans5.txt
开始处理orig_0.8_dis_3.txt
查重率为:0.93
结果已写入result/ans6.txt
开始处理orig_0.8_dis_7.txt
查重率为:0.90
结果已写入result/ans7.txt
开始处理orig_0.8_mix.txt
查重率为:0.91
结果已写入result/ans8.txt
开始处理orig_0.8_rep.txt
查重率为:0.83
结果已写入result/ans9.txt
第一个抄袭文本是添加,因为其文本都是原文本存在的内容,结果竟然出来了1.00的结果,全抄??显然不对,LCS的不足之处很快就体现出来了,它非常依赖原文本!我们再来试试纯Jaro:
- 测试代码
/**
* 测试全部样例(纯Jaro)
*/
@Test
public void testForAllFilesOnlyJaro(){
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file : files){
if(!file.equals("orig.txt")){
System.out.println("开始处理"+file);
AnswerProcessor.processJustByJaro("tests/orig.txt","tests/"+file,"result/ans"+cnt+".txt");
cnt++;
}
}
}
- 控制台输出结果
开始处理orig_0.8_add.txt
查重结果为:0.79
结果已写入result/ans1.txt
开始处理orig_0.8_del.txt
查重结果为:0.78
结果已写入result/ans2.txt
开始处理orig_0.8_dis_1.txt
查重结果为:0.99
结果已写入result/ans3.txt
开始处理orig_0.8_dis_10.txt
查重结果为:0.97
结果已写入result/ans4.txt
开始处理orig_0.8_dis_15.txt
查重结果为:0.95
结果已写入result/ans5.txt
开始处理orig_0.8_dis_3.txt
查重结果为:0.99
结果已写入result/ans6.txt
开始处理orig_0.8_dis_7.txt
查重结果为:0.98
结果已写入result/ans7.txt
开始处理orig_0.8_mix.txt
查重结果为:0.82
结果已写入result/ans8.txt
开始处理orig_0.8_rep.txt
查重结果为:0.74
结果已写入result/ans9.txt
诶,这个看着还不错啊,但中间这几个文本...那几个文本是调换顺序,怎么说呢,文本内容其实没变,就是换了一些词的顺序,但是非常接近全抄,其实这个算法这样已经很好了,可我感觉总是差点意思,它不依赖原文本,它靠的是差异;如果文本内容调换顺序,还能维持原来的意思吗?不见得。在某些情况下,经过排列后,其实不算是抄,那是有技巧地推陈出新;还有第一个add的部分,让我想起来小学时候写作文,不会就嗯抄,然后自己添一点,就是自己的了,显然不对,我认为这就是大抄!“天下文章一大抄”这话固然没错,但是好的抄文是懂得排列组合,而非单靠一篇文章推陈出新,基于此,我觉得add的抄袭比重还不够,应该给予更多!
而且不知道你们有没有发现,Jaro有个奖励机制,就是它会奖励前缀相同。正因如此,如果是长文本的话,也就是整篇文章直接来,那它至多只会被奖励一次,就看文章开头,这似乎不太准确;若是加上分词将它切开,放如LCS中,就会获得很多的奖励,这样岂不是更准确,拉开“贫富差距”!
综上考虑,我改进的思路和想法就是:把两者结合!!!结合两者的优势,中和掉二者的不足!
LCS+Jaro:
- 先看代码
/**
* 基于最长公共子串算法,计算Jaro距离
* @param word_a org.txt文件
* @param word_b org_add.txt文件
* @return
*/
public static int JaroDisBasedOnLCS(List<String> word_a, List<String> word_b){
int[][] cell = new int[word_a.size()+1][word_b.size()+1];
int lena = word_a.size();
int lenb = word_b.size();
for(int i=0;i<lena;i++){
for(int j=0;j<lenb;j++){
if(StringUtils.getJaroWinklerDistance(word_a.get(i),word_b.get(j))>0.6){
cell[i+1][j+1] = cell[i][j] + 1;
}else{
cell[i+1][j+1] = Math.max(cell[i][j+1],cell[i+1][j]);
}
}
}
return cell[lena][lenb];
}
- 再来看看运行结果:
开始处理orig_0.8_add.txt
查重率为:0.98
结果已写入result/ans1.txt
开始处理orig_0.8_del.txt
查重率为:0.79
结果已写入result/ans2.txt
开始处理orig_0.8_dis_1.txt
查重率为:0.98
结果已写入result/ans3.txt
开始处理orig_0.8_dis_10.txt
查重率为:0.85
结果已写入result/ans4.txt
开始处理orig_0.8_dis_15.txt
查重率为:0.67
结果已写入result/ans5.txt
开始处理orig_0.8_dis_3.txt
查重率为:0.94
结果已写入result/ans6.txt
开始处理orig_0.8_dis_7.txt
查重率为:0.90
结果已写入result/ans7.txt
开始处理orig_0.8_mix.txt
查重率为:0.90
结果已写入result/ans8.txt
开始处理orig_0.8_rep.txt
查重率为:0.79
结果已写入result/ans9.txt
芜湖,起飞!✈️它已经很贴近我的心理预期了!
但这样结合带来的后果就是...跑得很慢...似乎不是性能改进啊这...
其实我唯一的性能改进的地方就是加了抽去标点符号,那使我速度快了40%,但是这似乎是步骤中必要的一步,也不算是改进啦,后来想起来加上去的,所以性能改进part的话,暂时是没有解决的。
扯完皮了,该回答一下要求的问题了!
(接下来我以添加20%文本的那条为例)
性能分析图展示
- 类的内存消耗
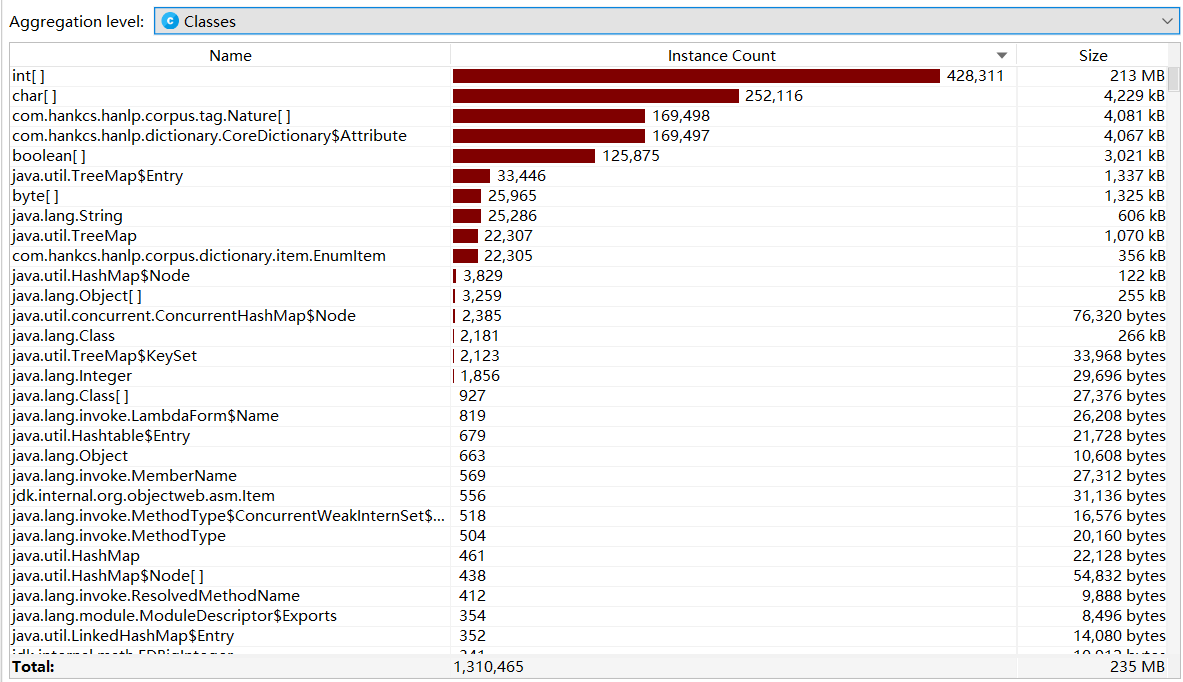
- CPU Load(运行时间:4.2s,满足要求)
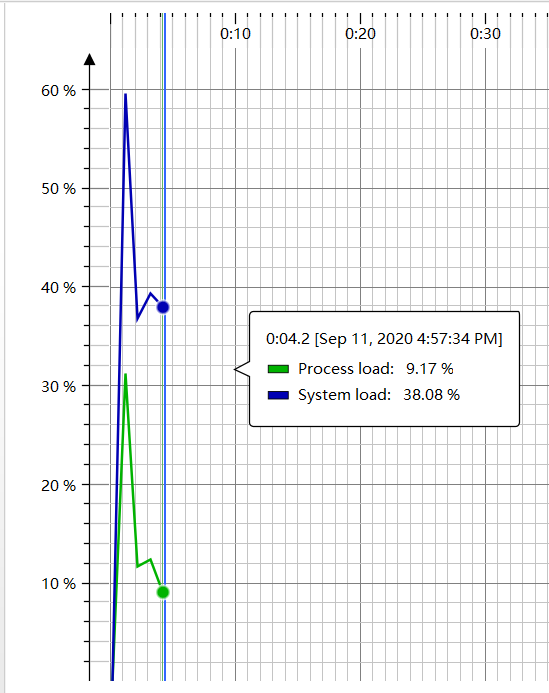
- 堆内存情况
程序中消耗最大的方法
毫无疑问,当然是Jaro啊,在LCS中,它作为每一步的判断条件,不得累死,直接吃掉75%左右,最气的是它没办法优化,因为是我调的别人的,呜呜呜😢

记录在改进计算模块性能上所花费的时间
其实并不多,主要花时间在查找算法资料上,一开始我就是用的LCS,但发现了它的稳定性、效率、准确性,都不尽如人意,想到要结合,或许会好些;硬要算的话,maybe 2小时用来找Jaro了,找到就用了,测试结果虽然不算很好,但也不差
计算模块部分单元测试展示
展示单元测试代码
import org.junit.Test;
import java.io.File;
/**
* 测试
*/
public class TestCase {
/**
* 测试全部样例(纯Jaro)
*/
@Test
public void testForAllFilesOnlyJaro(){
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file : files){
if(!file.equals("orig.txt")){
System.out.println("开始处理"+file);
AnswerProcessor.processJustByJaro("tests/orig.txt","tests/"+file,"result/ans"+cnt+".txt");
cnt++;
}
}
}
/**
* 测试全部样例(纯LCS)
*/
@Test
public void testForAllFilesOnlyLCS(){
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file : files){
if(!file.equals("orig.txt")){
System.out.println("开始处理"+file);
AnswerProcessor.processJustByLCS("tests/orig.txt","tests/"+file,"result/ans"+cnt+".txt");
cnt++;
}
}
}
/**
* 测试全部样例(Jaro+LCS)
*/
@Test
public void testAllFiles(){
File f = new File("tests");
String[] files = f.list();
int cnt = 1;
for(String file : files){
if(!file.equals("orig.txt")){
System.out.println("开始处理"+file);
AnswerProcessor.process("tests/orig.txt","tests/"+file,"result/ans"+cnt+".txt");
cnt++;
}
}
}
/**
* 测试20%文本添加情况:orig_0.8_add.txt
*/
@Test
public void testForAdd(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_add.txt","ans.txt");
}
/**
* 测试20%文本删除情况:orig_0.8_del.txt
*/
@Test
public void testForDel(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_del.txt","ans.txt");
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_1.txt
*/
@Test
public void testForDis1(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_dis_1.txt","ans.txt");
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_3.txt
*/
@Test
public void testForDis3(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_dis_3.txt","ans.txt");
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_7.txt
*/
@Test
public void testForDis7(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_dis_7.txt","ans.txt");
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_10.txt
*/
@Test
public void testForDis10(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_dis_10.txt","ans.txt");
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_15.txt
*/
@Test
public void testForDis15(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_dis_15.txt","ans.txt");
}
/**
* 测试20%文本格式错乱情况:orig_0.8_mix.txt
*/
@Test
public void testForMix(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_mix.txt","ans.txt");
}
/**
* 测试20%文本错别字情况:orig_0.8_rep.txt
*/
@Test
public void testForRep(){
AnswerProcessor.process("tests/orig.txt","tests/orig_0.8_rep.txt","ans.txt");
}
/**
* 测试相同文本:orig.txt
*/
@Test
public void testForSame(){
AnswerProcessor.process("tests/orig.txt","tests/orig.txt","ans.txt");
}
}
说明测试的方法,构造测试数据的思路
- 测试的方法就是分别跑LCS、Jaro、LCS+Jaro咯!就遍历一下原文文本所在文件夹的所有文件,读进来处理就行!其他就是分别对单个文件进行测试。为了防止出错,我还加了个相同文件的,要是不为1就出事了!
- 至于测试数据,我觉得给的样例就很好了,涵盖了不同情况:添加、删除、错别字、打乱顺序、格式错乱等...
测试结果
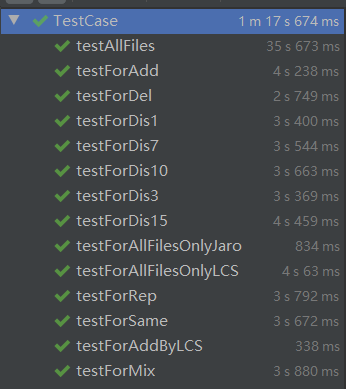
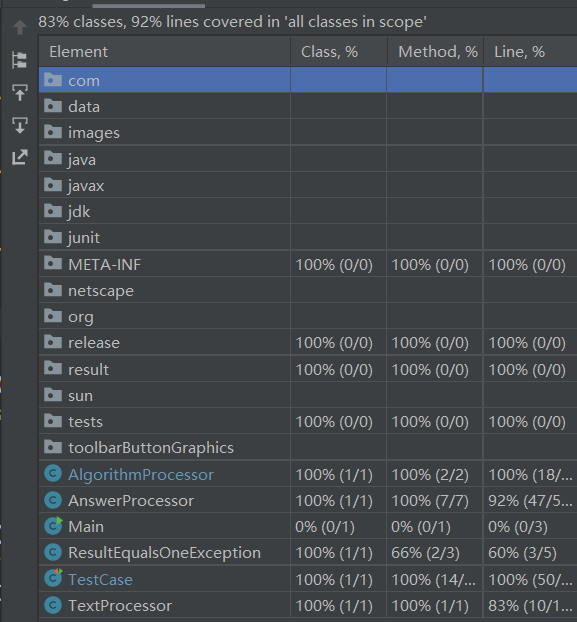
测试覆盖率截图
评价一下自己的测试
- 没有使用Assert断言,不知是我还不太会用,还是确实用不上,感觉不需要啊我这个
- 没有试验大数据文本来跑,是个缺憾(我盲猜会非常非常慢)
计算模块部分异常处理说明
我设计的异常
/**
* 非相同文本,查重率却为1
*/
public class ResultEqualsOneException extends Exception{
public ResultEqualsOneException() {
}
public ResultEqualsOneException(String message) {
super(message);
}
@Override
public String getMessage() {
return super.getMessage();
}
}
// 具体使用
if(ans/standardLength==1.00 && !orgFileName.equals(orgAddFileName)){
try {
throw new ResultEqualsOneException("非相同文本,查重率怎么会为1呢?");
} catch (ResultEqualsOneException e) {
e.printStackTrace();
}
}
测试
我们试一下相同文本的情况,会不会报

再试一下LCS的add文本看看

和前文提到的1.00的结果一致
其实还可以写一个与之对应的异常和测试方法,就是那两个完全不同的文本来测是否为0;这个其实我有测过了,是对的,但我觉得意义真的不大,又删去了,这样真的不是一个好的异常和测试的设计。(空文本测试同理)
总结
- 接口的设计的话,我觉得这次其实看不出什么,因为只是个小小的小项目,写的也基本上是工具类,体现不出设计模式一类的东西
- 性能改进方面真的很抱歉啊,没办法,拥抱开源的我,还把自己写的垃圾LCS和Apache的库结合了,结果就是淦慢,希望下次能自己设计算法吧,自己的东西才方便优化
- 单元测试的话,第一次使用,很遗憾没能用上断言(除了两个完全相同和两个完全不同的或许可以硬用上Assert的Equals,其他我真不知道怎么用,可能也和我的代码有关系),希望下次有机会能用上,还有测试压力部分,逃避了,下次尽量找大数据怼
- 异常处理部分,说实话,真的不知道能写什么异常,绞尽脑汁,就想到一个,还是没去Override的,直接就等于Exception改个名儿,希望下次能提升自身逻辑严谨性,考虑尽量周全(也可能是项目还不够大吧)
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 480 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 180 |
| Design Spec | 生成设计文档 | 60 | 20 |
| Design Review | 设计复审 | 30 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 390 | 210 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 120 |
| Reporting | 报告 | 90 | 120 |
| Test Repor | 测试报告 | 60 | 100 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 30 |
| Total | 合计 | 1840 | 1275 |

