幂法(指数迭代法)
幂法是通过迭代来计算矩阵的主特征值(按模最大的特征值)与其对应特征向量的方法,适合于用于大型稀疏矩阵。
1 基本定义#
设,其特征值为,对应特征向量,即,且线性无关。任取一个非零向量,构造一个关于矩阵的乘幂的向量序列:
称为迭代向量。
设特征值的前个为绝对值最大的特征值(ppt中分为强占优和非强占优,感觉没必要),即有:
由于 线性无关,所以构成的一个基,于是能被表达为:
(且设非全零)
由:
其中:
因为最大,所以有,从而有:
所以有:
因为在上式中是固定项,可以看出,迭代到后期,和的各个元素有固定比值,即:
这样,收敛到主特征值后,还可另外计算它对应的一个特征向量(其实就是构成的前项之和,而且只能算一个):
其中收敛速度由比值决定,越小收敛越快。
2 幂法改进#
以上定义中,随着不断的迭代,如果,会无限大;如果,则会趋于0。在计算机中就会导致溢出而出错。当然如果很小,使得能快速收敛为0,并且不会太大或太小以至于在收敛前就溢出了,那用上述方法就行了。
但是通常不会碰到那么好的运气,所以就在每次迭代的时候就要对进行“规范化”,防止它溢出。规范化就是将向量除以一个标量,使向量的长度为1,而向量的长度有多种度量法,比如等。一般使用,就是向量各个分量的绝对值的最大值(用别的也一样,但是这个复杂度最小,计算机最好算)。
为了便于理解,将一次迭代分为两步,一步乘矩阵,一步除以向量长度进行规范化:
| 迭代序号 | 乘() | 规范化() |
| 初始化 | 随机取 | |
| 1 | ||
| 2 | ||
| ... | ... | ... |
| k | ||
| ... | ... | ... |
2.1 主特征值 #
对于向量序列:
对取范数:
注意!在计算机中并不是直接通过这个极限来计算,而是通过上面表格的迭代来实现,由于每一步的“规范化”,才能使得计算成为可能。而且如果直接用这个极限算的话就和前面的没区别了,“规范化”的优势没有用起来。
另外,因为算范数的时候是先取向量分量的绝对值再算的,所以改进后的方法计算出来的主特征值不可避免带有绝对值,因此特征值的符号还要再判断一下(下面判断)。而改进之前的是不带的(因为没有计算范数进行规范化),如果符合条件,改进之前的也可一试。
2.2 主特征值对应的一个特征向量#
观察向量:
如上,通过可获得一个单位化的主特征值特征向量。因为还乘上了的符号,所以向量各个分量的符号和迭代的次数有关。当足够大(使迭代收敛),连续两次迭代,的分量的符号不变时,则可以判断主特征值符号为正,否则为负,从而解决了上面主特征值符号未知的问题。
另外,求出的单位特征向量(如果用L2范数)是主特征值的所有不相关特征向量的线性组合,与设置的有关。当然如果主特征值的没有重根,且不为零(为零的话就迭代出第二大的特征值),那规范化后得出的都是同一个特征向量而和无关(如果特征值为负,符号可能随迭代次数改变)。
2.3 Python代码#

import numpy as np #矩阵A A = np.matrix( [[-5.6,2.,0.], [3.,-1.,1.], [0.,1.,3.]]) L0=2#范数类型 v = np.matrix([[-2.],[-7.],[1.]])#v0 u = v/(np.linalg.norm(v,L0))#u0 #迭代函数 def iterate_fun(A,u,final,L): i=0 while i<final: v = A*u u = v/(np.linalg.norm(v,L)) i=i+1 print("幂法特征值:") print(np.linalg.norm(v,L)) print("numpy特征值:") print(np.linalg.eig(A)[0]) print("幂法特征向量:") print(u) print("numpy特征向量:") print(np.linalg.eig(A)[1]) iterate_fun(A,u,1010,L0)
结果截图:

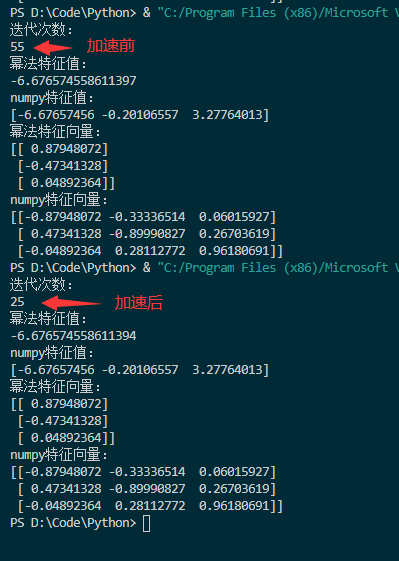
主特征值与numpy算出来绝对值一致。这里用的是L2范数,且主特征值无重根,所以计算出来的特征向量单位化后和numpy主特征值对应的向量除符号外相同。
3 迭代加速(原点平移法)#
幂法迭代的速度由比值决定,当比值比较接近1时,迭代的速度就可能比较慢了。迭代加速的方法是给矩阵减去一个数量阵:(为单位阵)
假设的特征值为:
则的特征值就是:
而的特征向量都是相同的。
注意!这里与上面假设不同,这里没有绝对值了。那么即使经过数量阵相加,特征值的大小关系还是不变的。用迭代出特征值后再加回即是的特征值。
对于,我们要:
1、保持的绝对值在中依旧是最大,对进行迭代才能算出最大特征值。
2、由于我们想要减小的迭代比值:
实际上,我们可以推断只会取为或是(画个数轴就能判断),而当:
数轴上在中间:(图中假设)

有,此时的迭代比值最小,为:
迭代速度达到最快,而再小或再大都会使迭代速度减慢。
另外,当,还可以求(或)的最小特征值。实际上,通过平移,幂法可以求的就是在数轴两端的特征值。
在实际应用中,的特征值并不知道,所以是不能精确计算的,这个方法告诉我们,当发现收敛速度很慢时,我们可以适当地变动一下加速收敛。
3.1 加速python代码#
代码加速迭代计算最小特征值(负数,绝对值最大),加速前迭代55次,加速后迭代25次,速度提升约50%。
import numpy as np p = (-0.20106557+3.27764013)/2#p的大小 #矩阵A A = np.matrix( [[-5.6,2.,0.], [3.,-1.,1.], [0.,1.,3.]]) A = A-np.eye(3)*p #平移 L0=2#范数类型 v = np.matrix([[-2.],[-7.],[1.]])#v0 u = v/(np.linalg.norm(v,L0))#u0 #迭代函数 def iterate_fun(A,v,u,L): i=0 former_v = -1 after_v = -1 isPositive = 1 while True: i=i+1 former_v = np.linalg.norm(v,L) v = A*u after_v = np.linalg.norm(v,L) if former_v-after_v==0.: if u[0]*v[0] < 0: isPositive = -1 break u = v/(np.linalg.norm(v,L)) print("迭代次数:") print(i) print("幂法特征值:") print(isPositive*np.linalg.norm(v,L)+p) print("numpy特征值:") print(np.linalg.eig(A+np.eye(3)*p)[0]) print("幂法特征向量:") print(u) print("numpy特征向量:") print(np.linalg.eig(A+np.eye(3)*p)[1]) iterate_fun(A,v,u,L0)
结果截图:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!