
MapReduce源码阅读
MapReduce运行流程图:
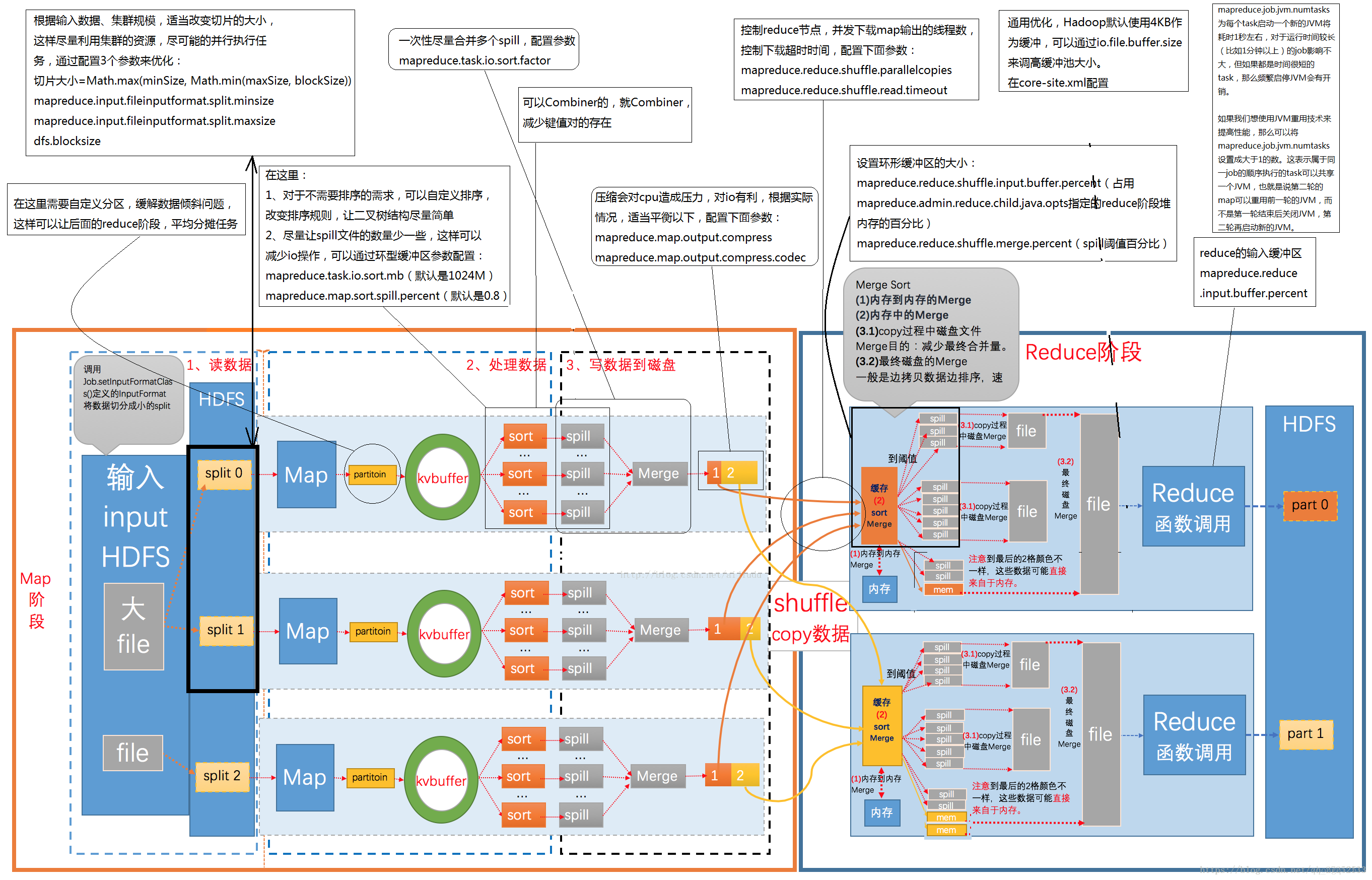
个人感悟:
- maptask中的InputFileReader组件读取的是hdfs中默认的一个block大小的文件,即128M,在mr中一个数据块即为一个split;
- 环形缓冲区其实为一个连续内存的字节数组,大小默认为100M,达到80%进行磁盘溢写;
- 从环形缓冲区中溢写出的文件spill都为有序的文件,多个spill合并成一个Merge文件和一个索引文件,标记从哪到哪属于哪个reduce的分区,提高后期reduce拉取map端输出数据的效率;
- reducer端从map输出端拉取使用协议为http,不停的拉取数据后将数据放在缓冲中进行在内存中进行合并;
- reducer端中的reduce函数使用的输入数据来源有2个:
- 数据量较小时,直接使用内存中的数据作为数据输入源;
- 数据量大时,则使用多次从reducer端内存溢写合并的文件作为数据的输入源头;
- Reducer端中输入的File有序的必要性:
- 如果无序则相同key进行汇总数据时候需要遍历很多次;
- 如果有序则reduce方法汇总数据的时候只需要遍历一次;
- Mapper端在环形缓冲区对数据进行排序的必要性: 环形缓冲区存在必要性:实现数据在mapper端的排序自由;
- 对环形缓冲区中的数据进行排序后,reducer端拉取数据后在内存中即可以使用更高效的归并排序对拉取后所有的数据进行排序来提高排序的高效性;
- Reducer端拉取数据来源为磁盘,如果想要实现对拉取数据高效性,可以使用数据提前在mapper端进行排序好;
- mapper端环形缓冲区溢写的多个有些spill磁盘文件后,spill合并成merge时候会再次启用一次归并排序;
- 常用的分区方式:hashPartitioner、rangePartitioner、Robin、自定义等,mapper端合并溢写的数据后数据并不一定是按照分区编号均匀的分布,所有可能导致reducer端拉取数据后产生数据倾斜;
- Reducer端拉取数据到内存中后也会按照拉取不同mapper端的有序文件数据再进行一次归并排序;
- 每个mapper端只输出一个mapper文件,不设计成一个分区一个文件的设计方式: mapper端spill文件merge并不是等所有的spill都溢写完成才开始进行合并,默认溢写3个文件就开始进行文件合并;
- 如果reducer的设置数据量太多,则可能会产生太多的小文件。
- Reducer中缓存的大小也是为100M;
笔记:

mapper阶段溢出的磁盘文件的组织形式: 1,a,1 1,a,2 1,a,1 1,b,1 1,b,2 ... 1,z,22 2,c,1 2,f,1 2,f,22
reducer的输入大文件的格式: a,1 a,2 a,1 a,2 a,1 a,2 a,1 a,1 ..... b,1 b,1 b,2
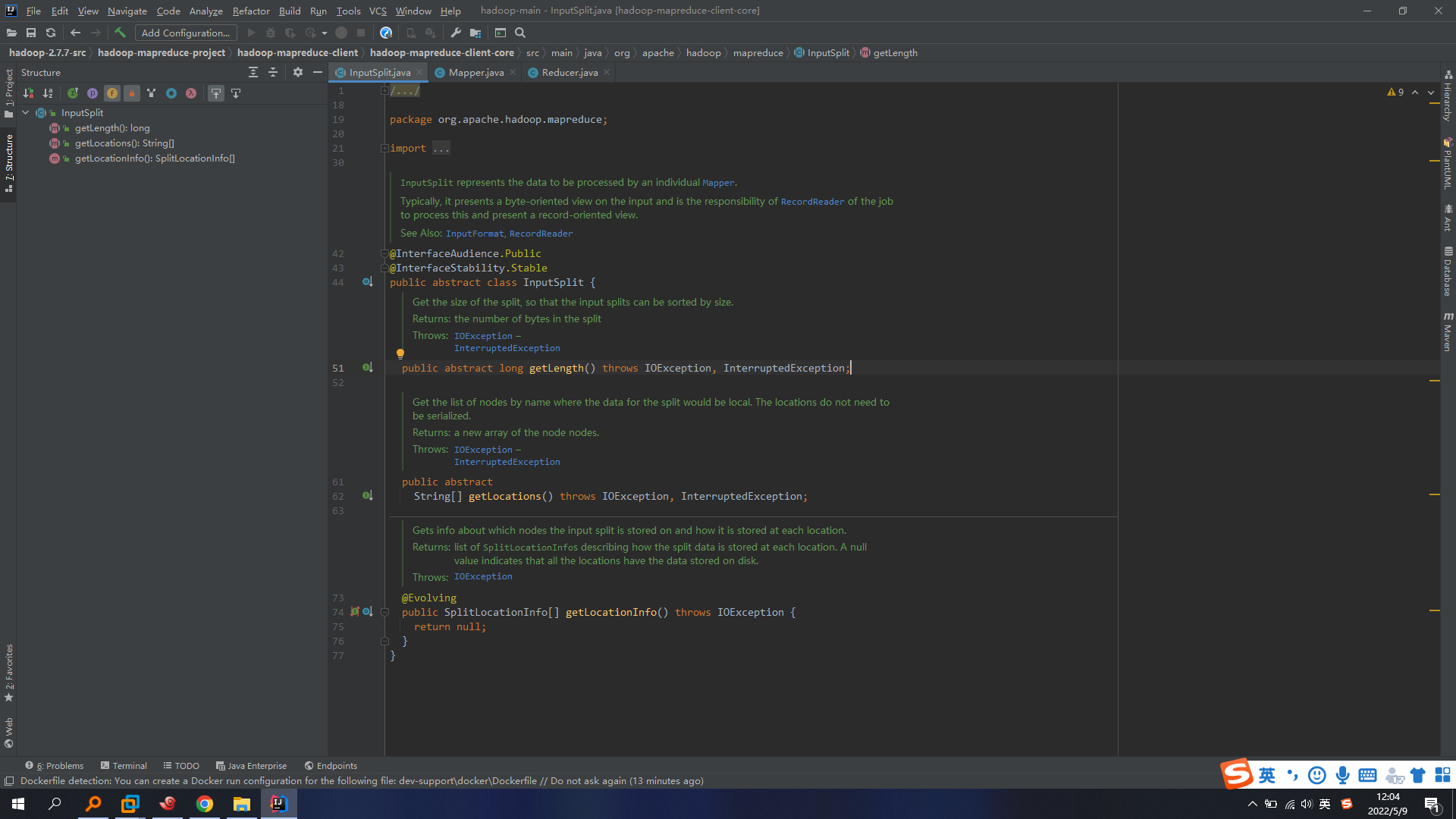
FileInputSplit核心类:
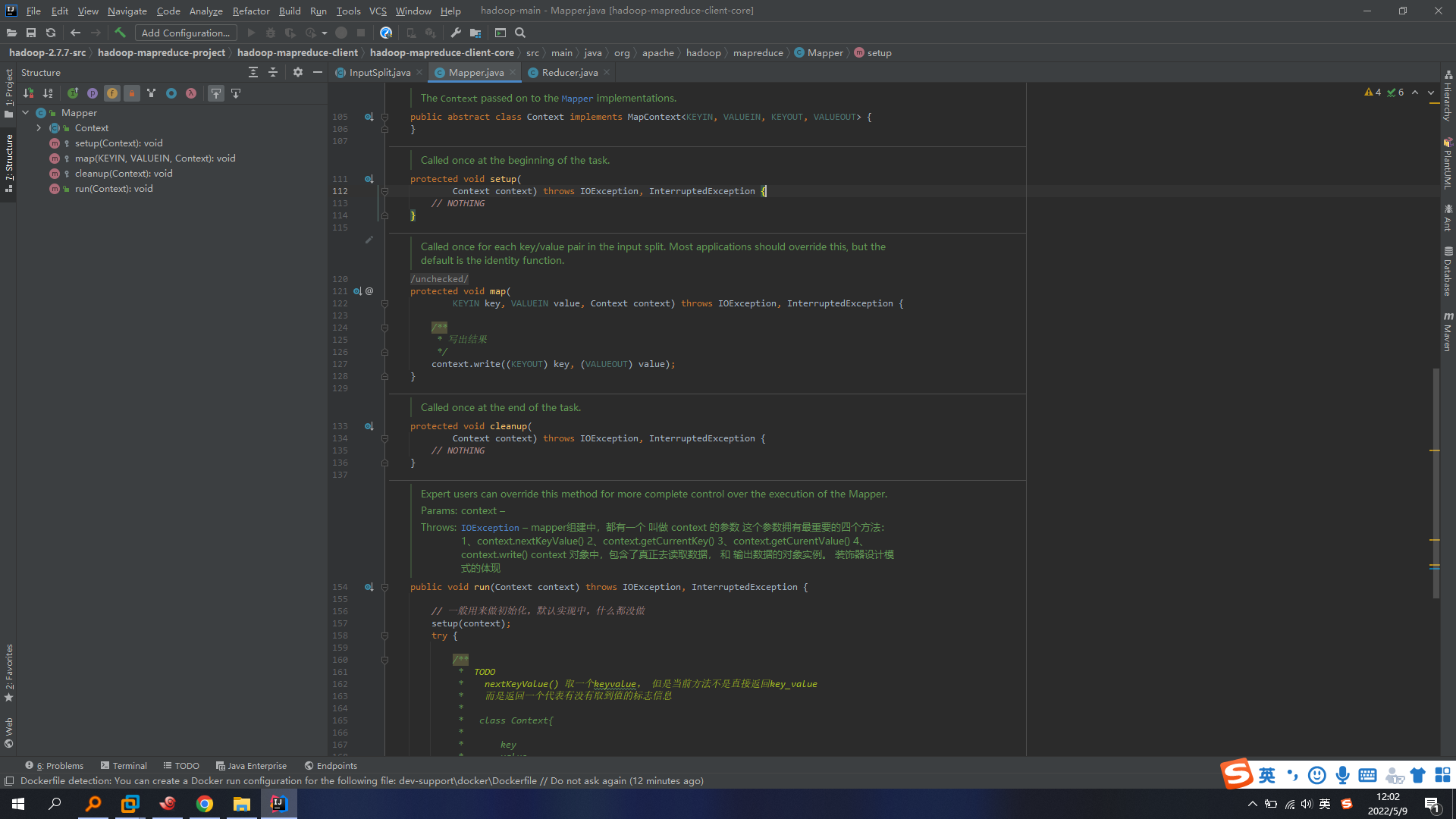
Mapper核心类:
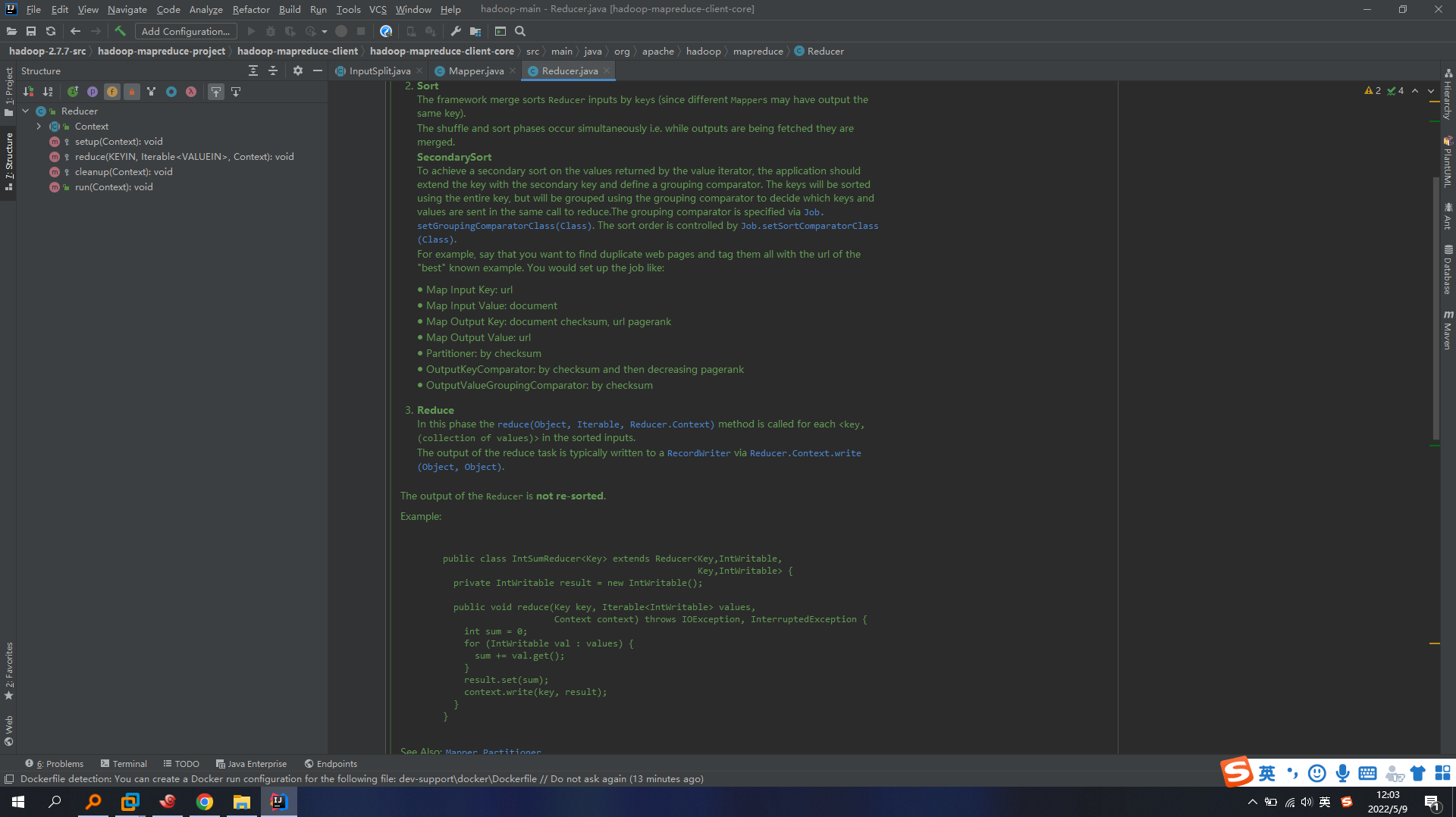
Reducer核心类:
========================================================== =========================================================== =========================================================== ===================================
Mapreduce执行过程:
1、程序的入口
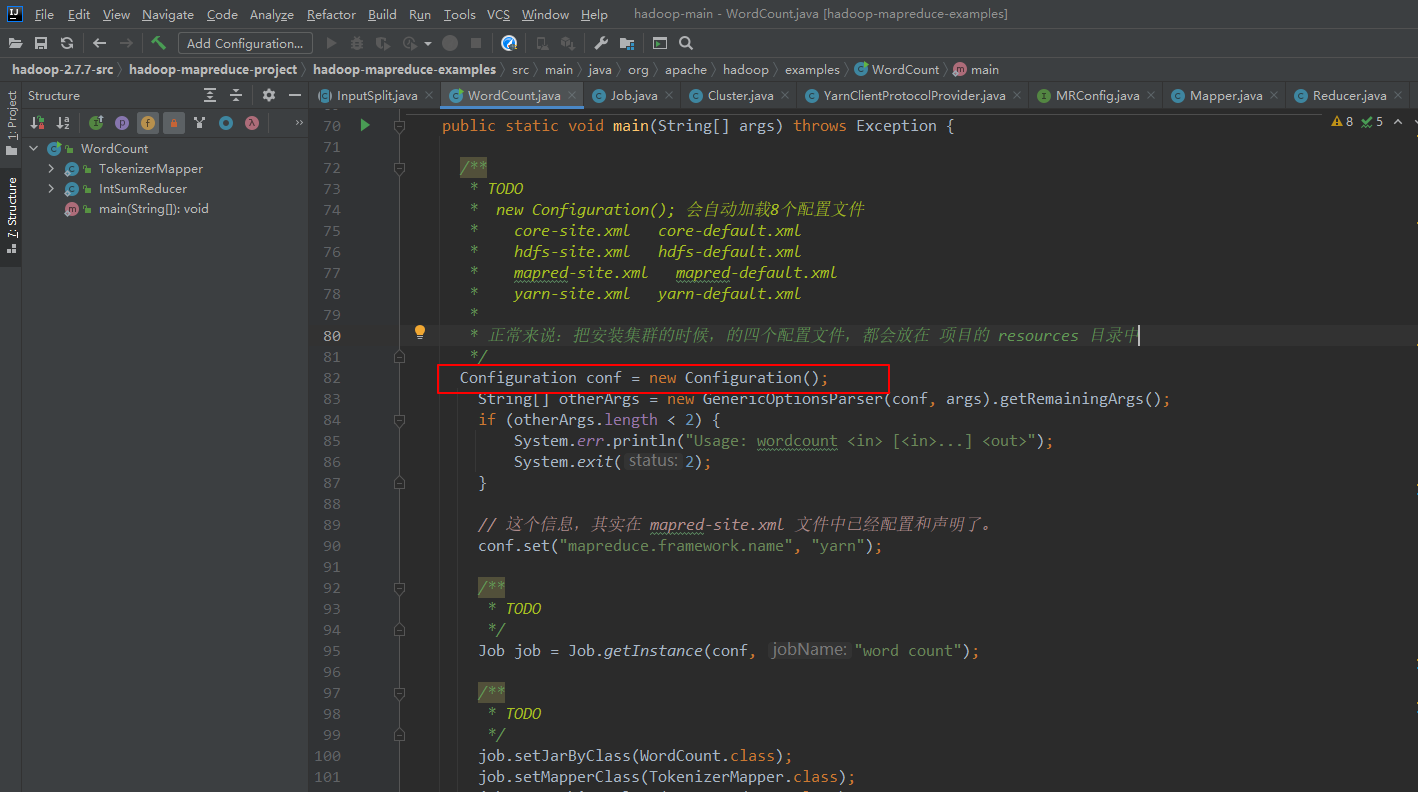
2、程序进行提交
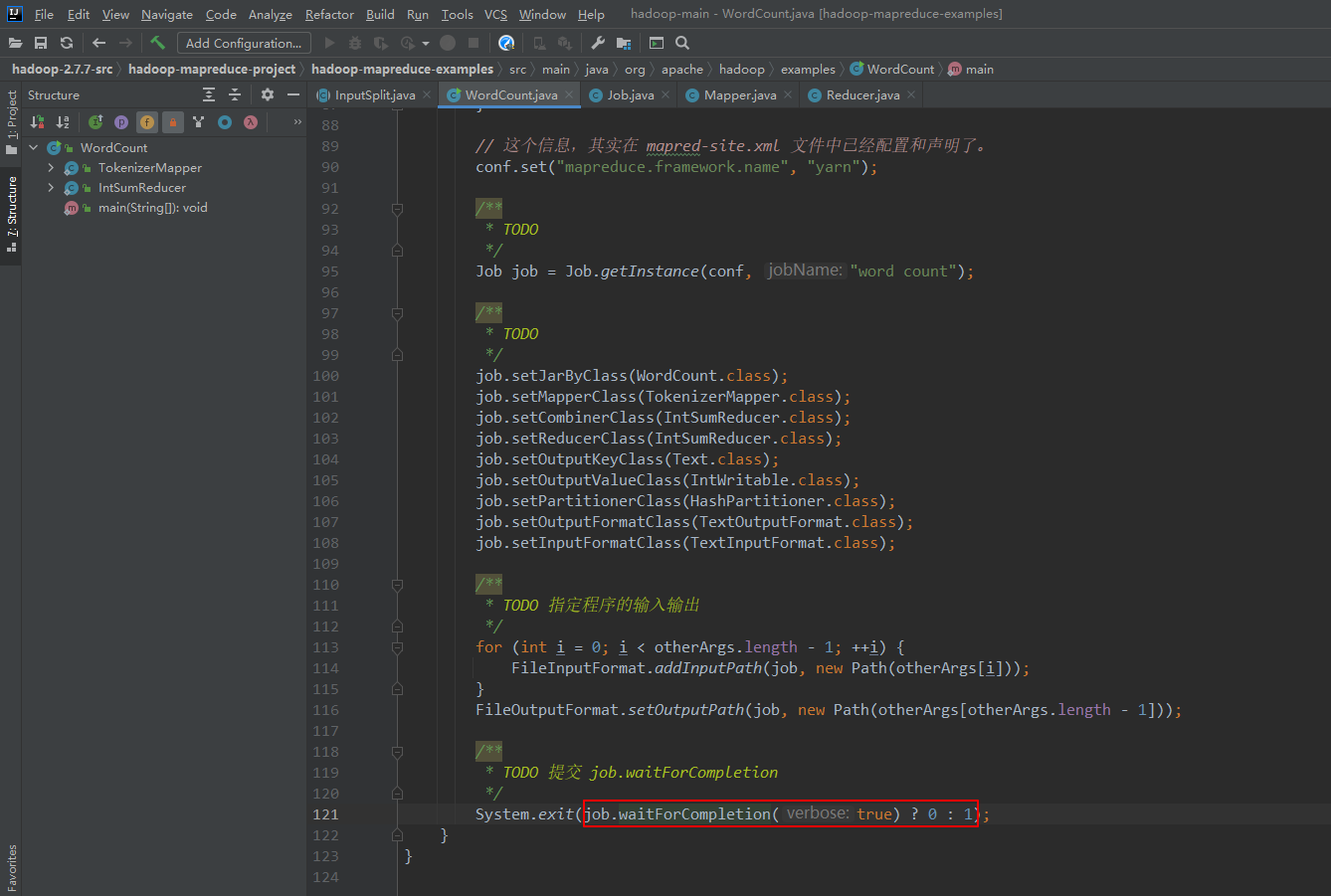
3、
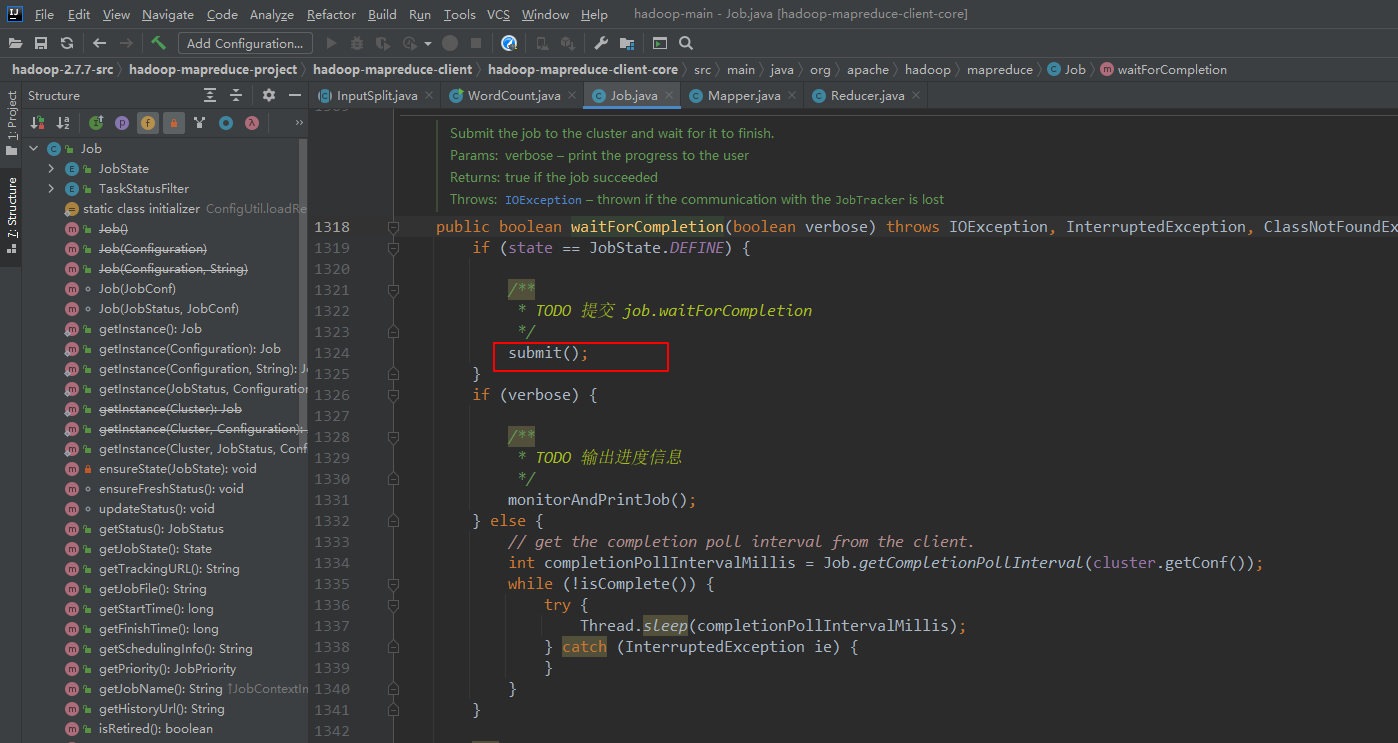
4、
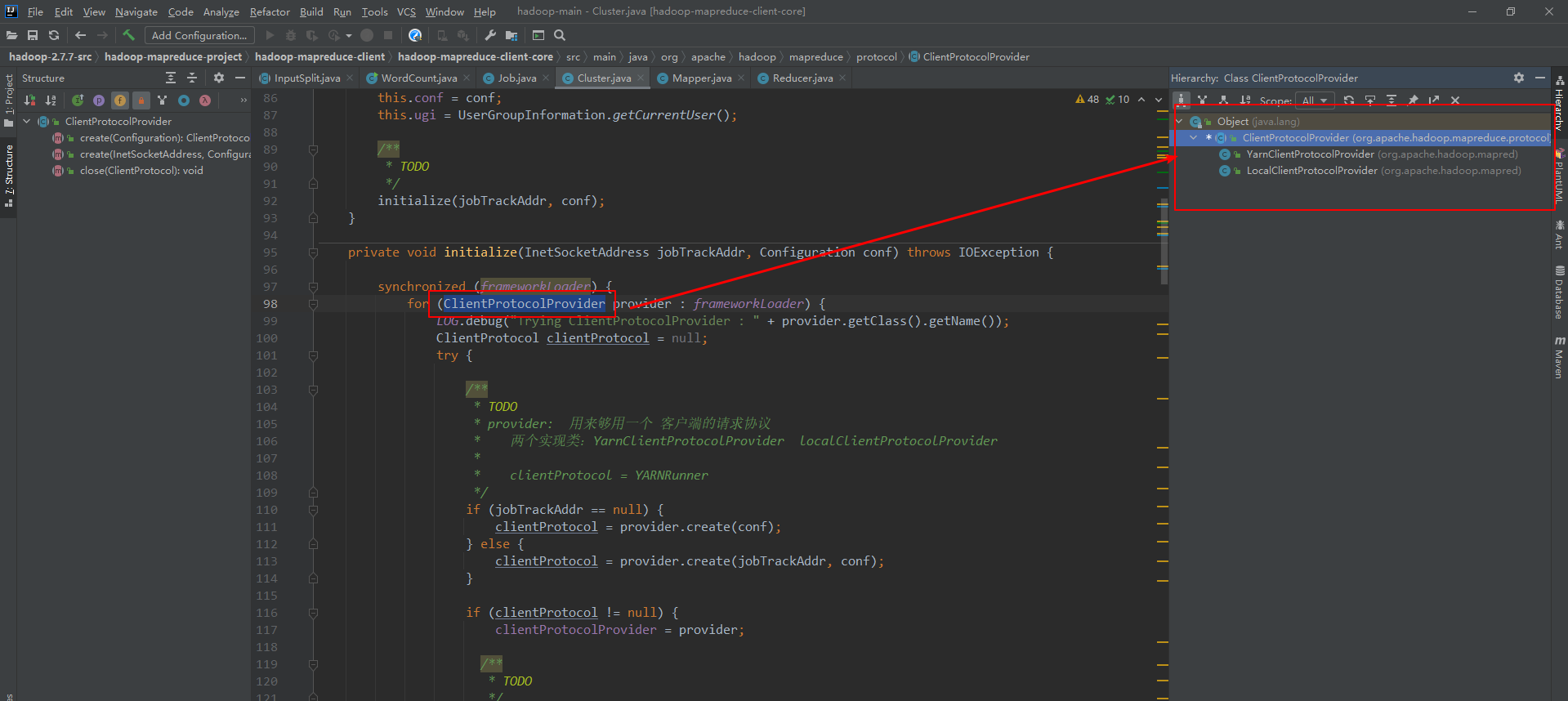
5、 任务真正提交
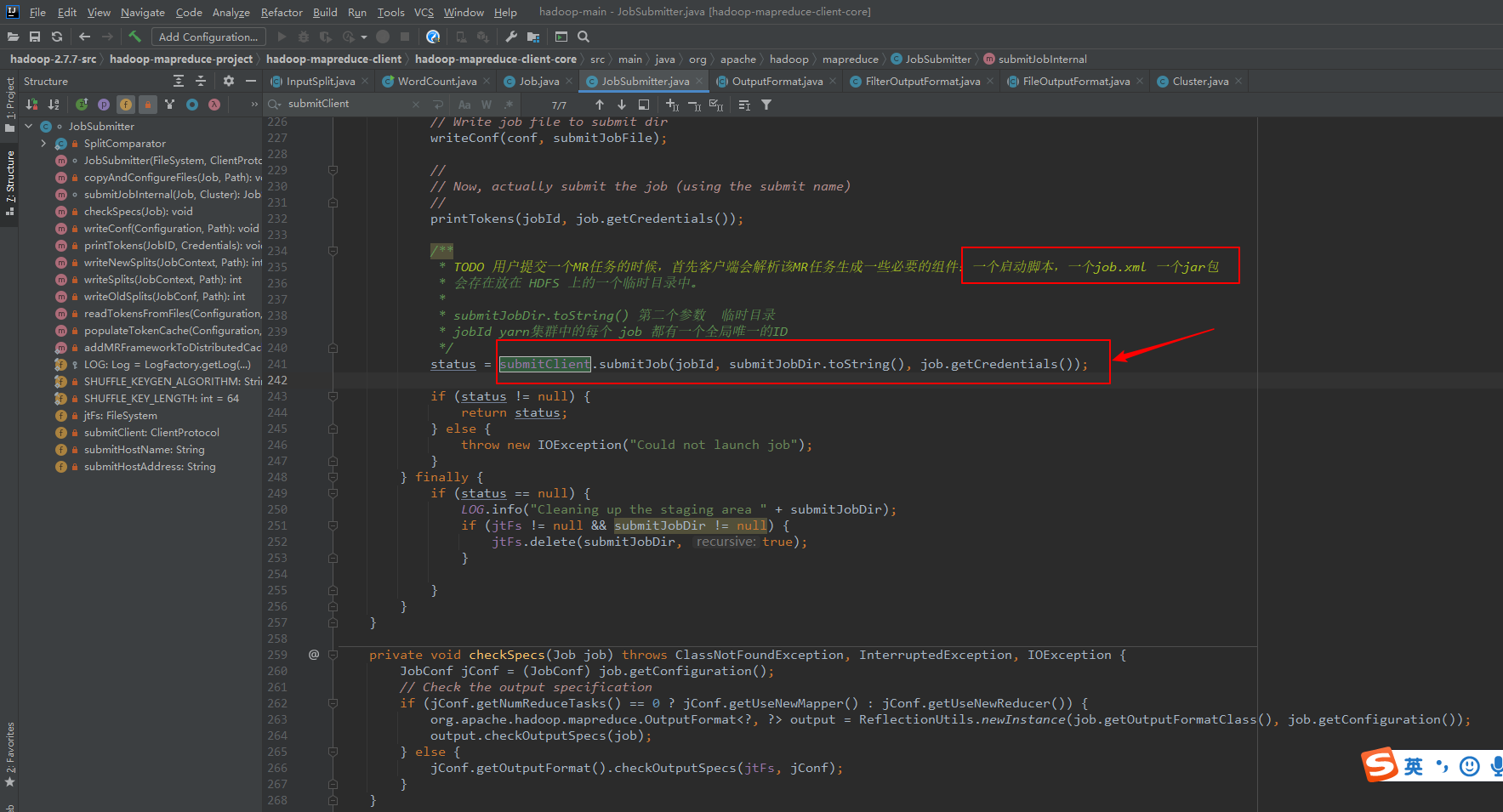
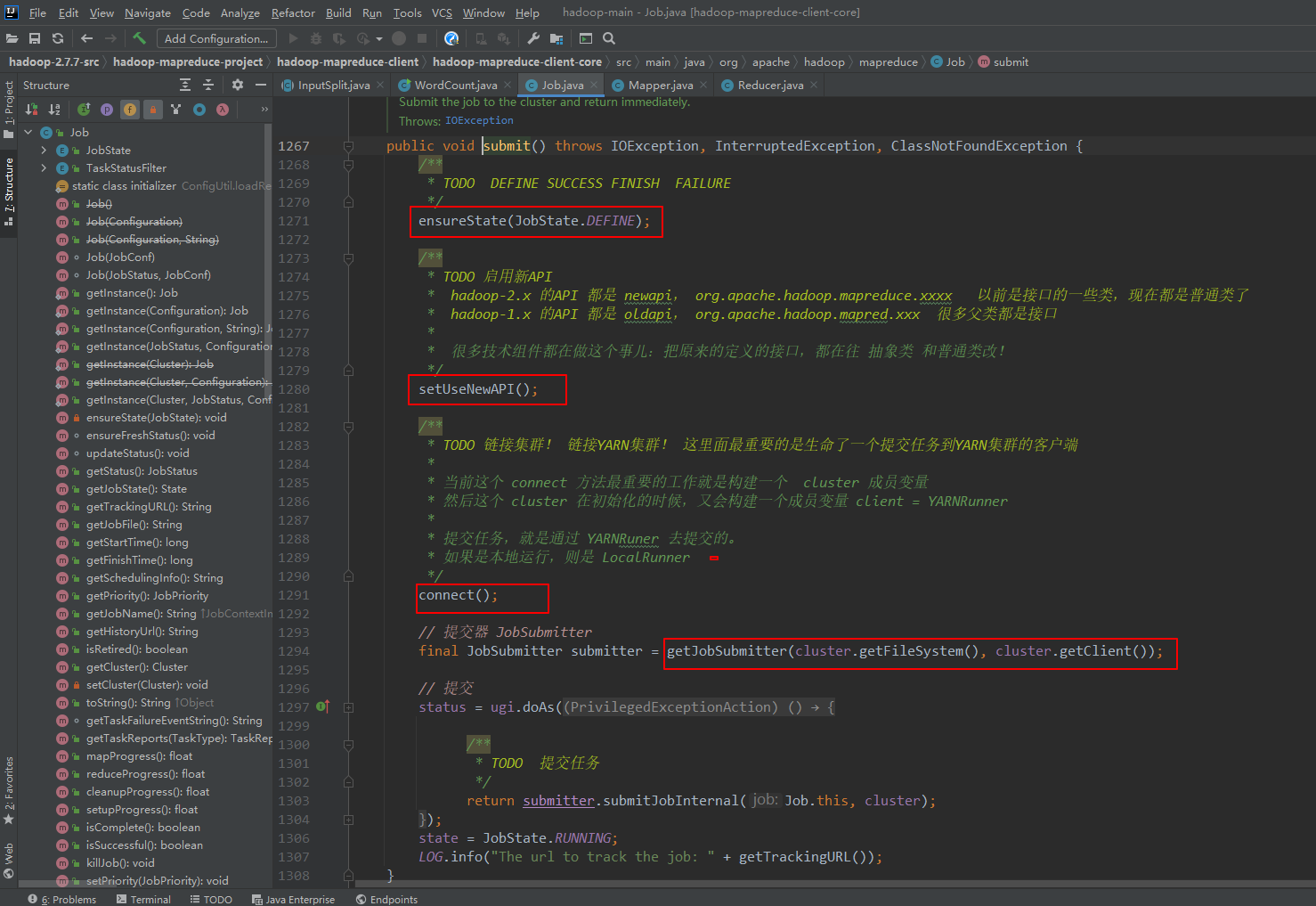
6、提交任务
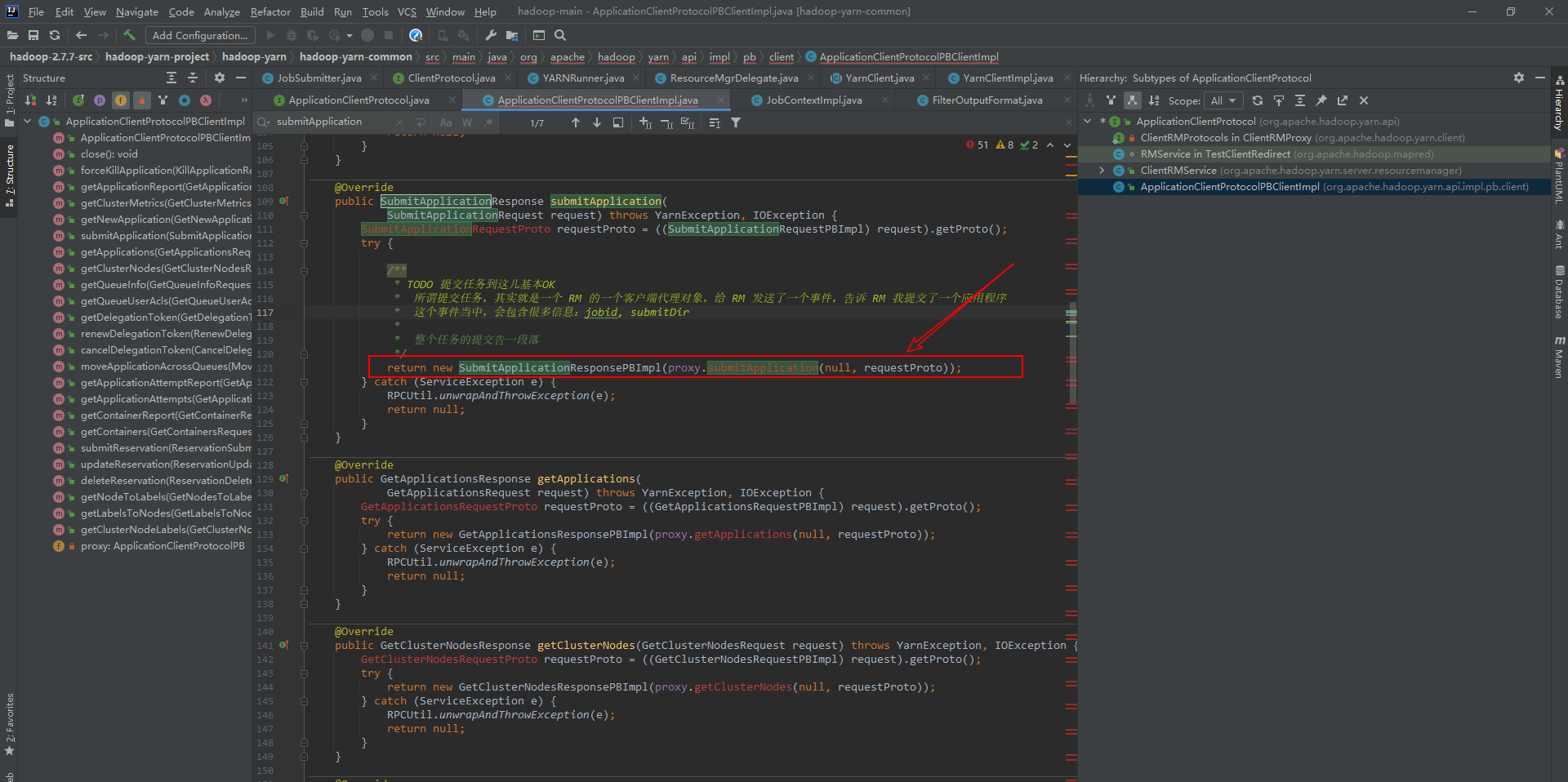
7、ReSourceManager启动
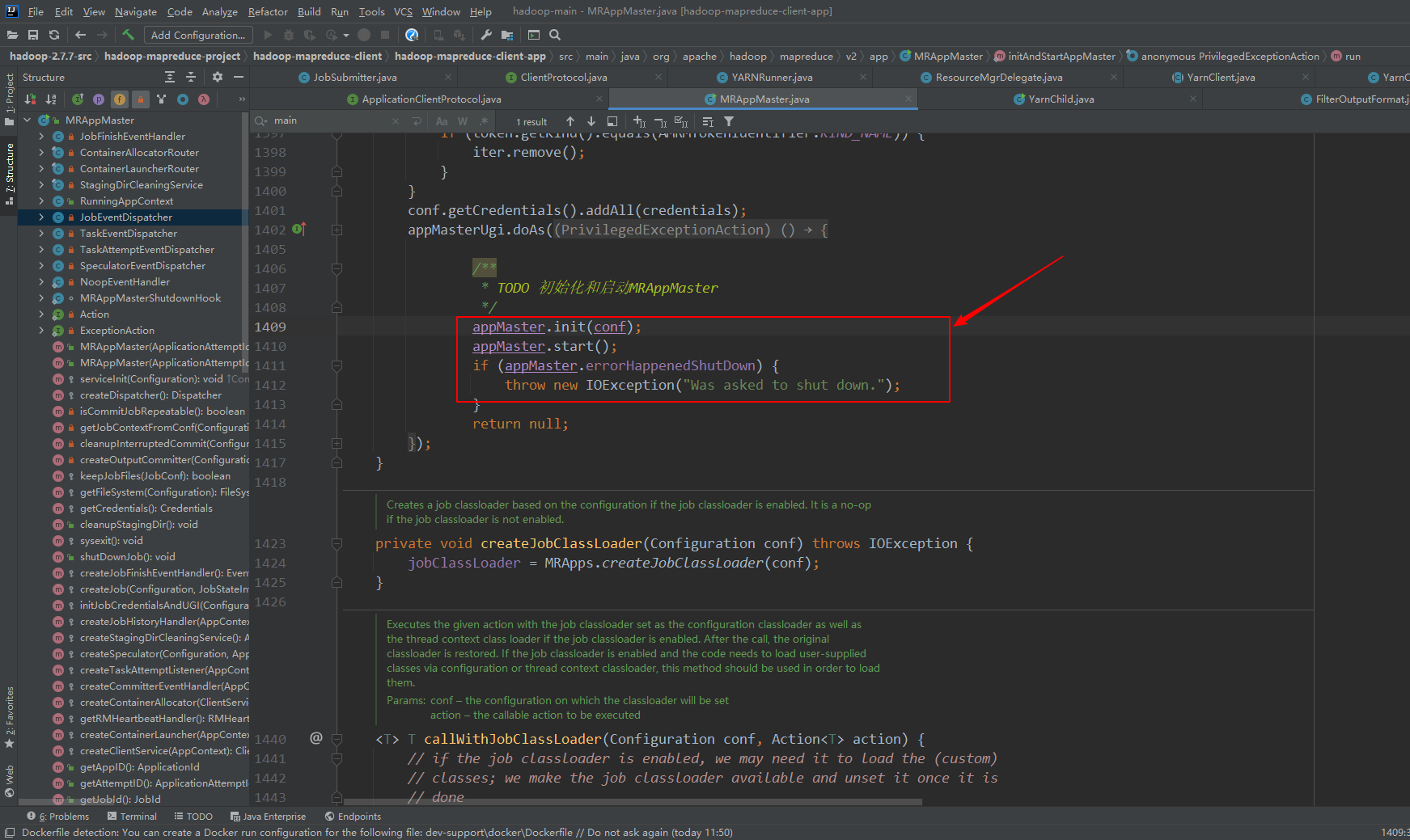
8、yarnchild启动maptask和reducetask
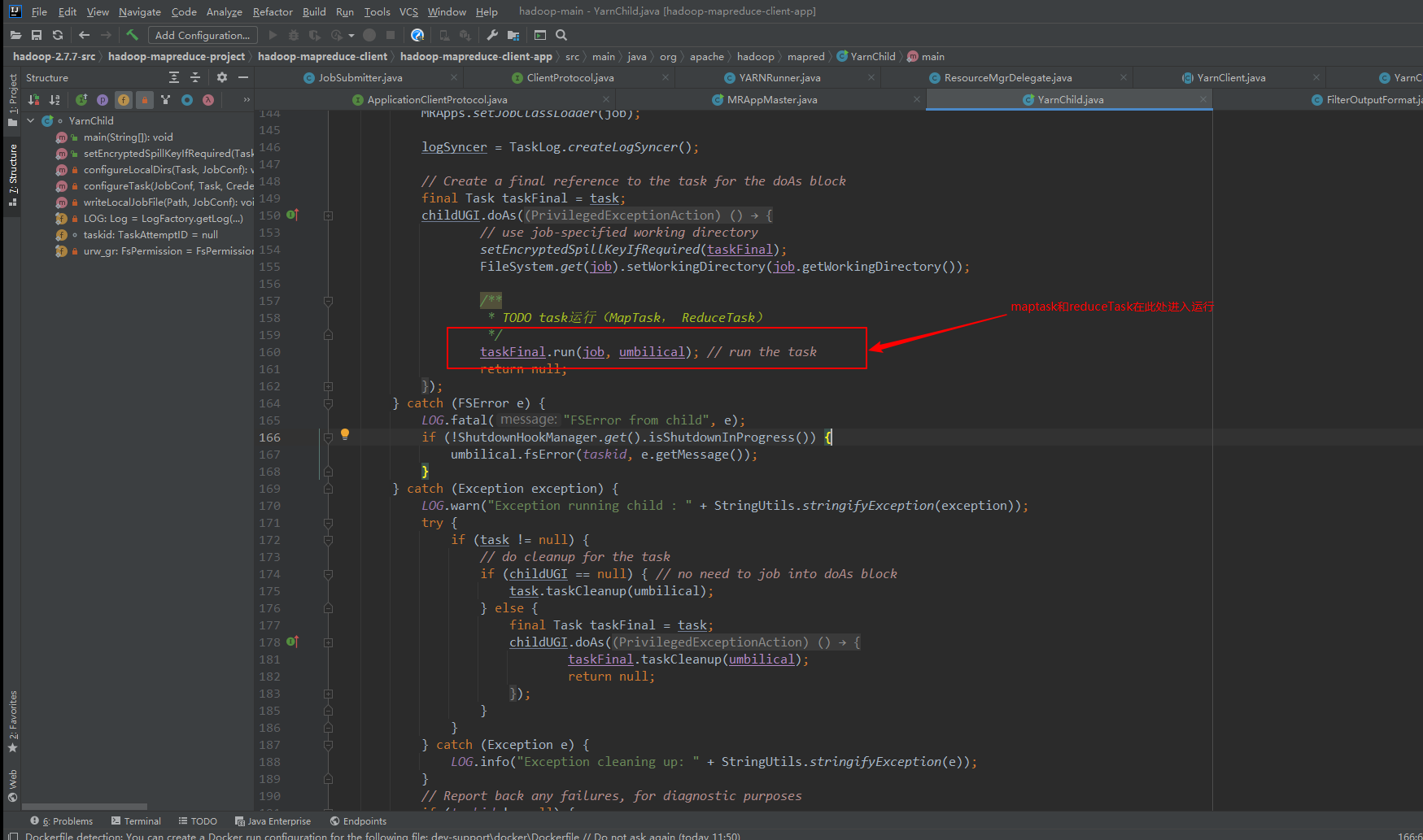
9、MapTask类的run()
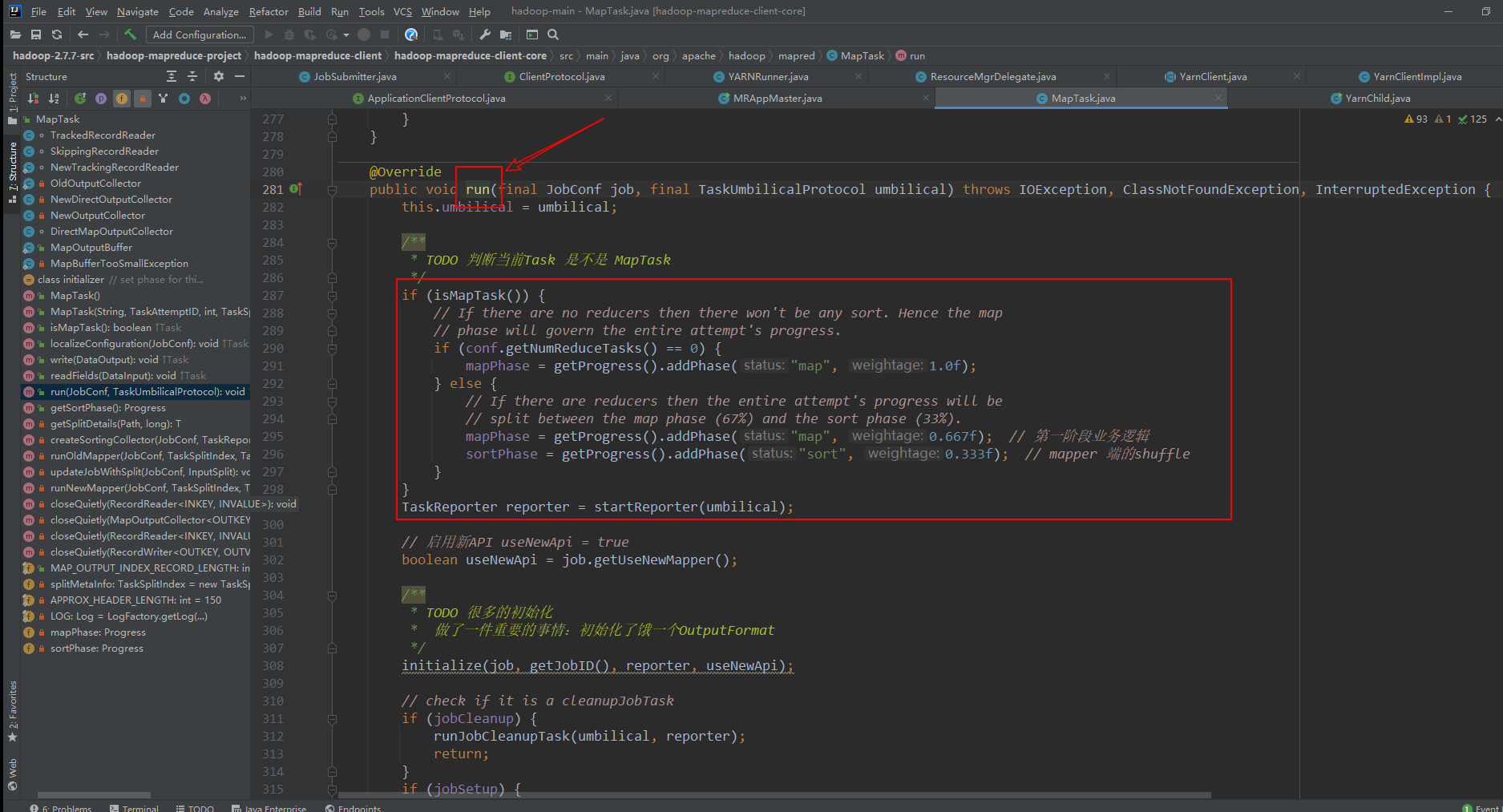
10、ReduceTask类中的run()
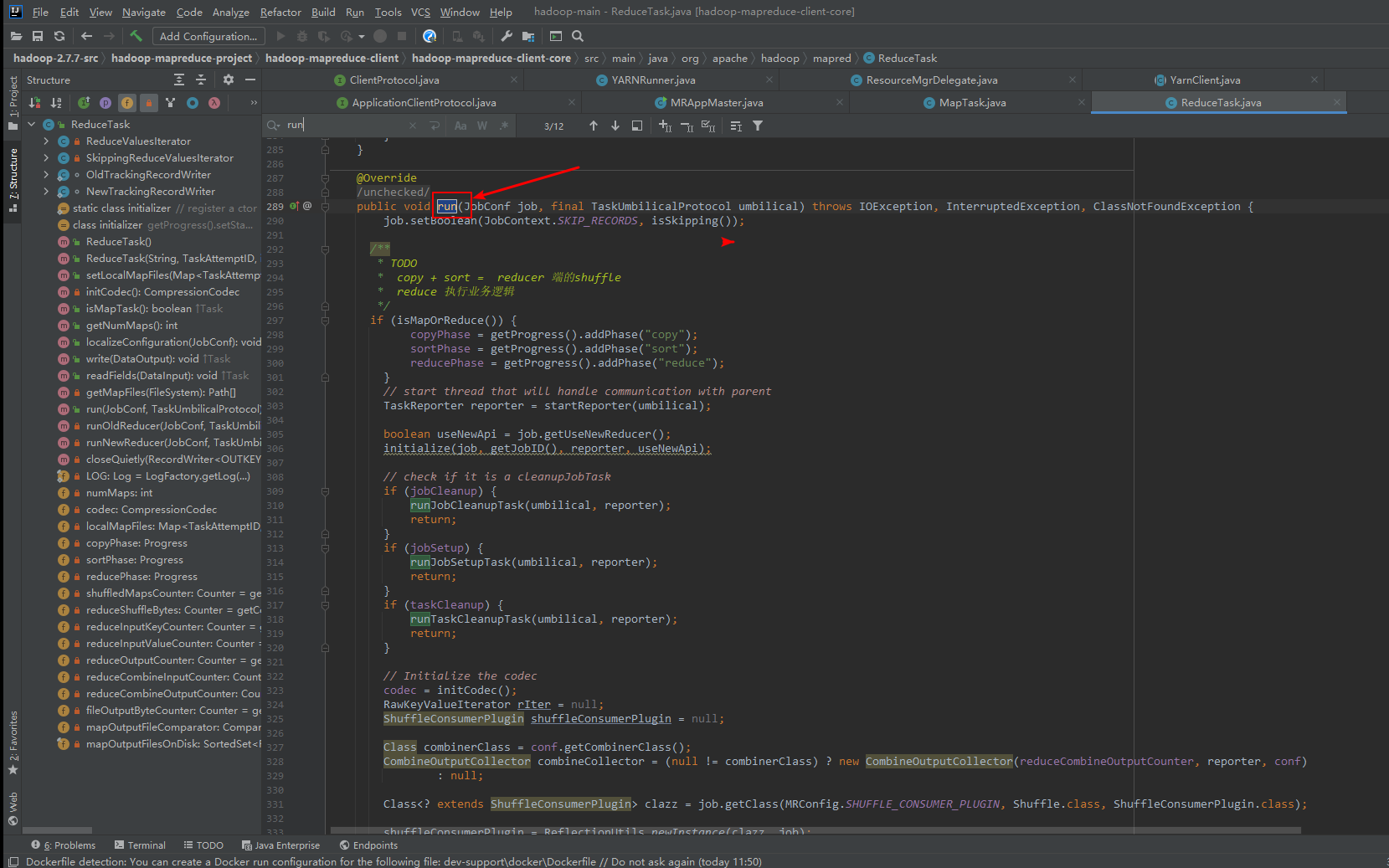
11、环形缓冲区MapOutputBuffer
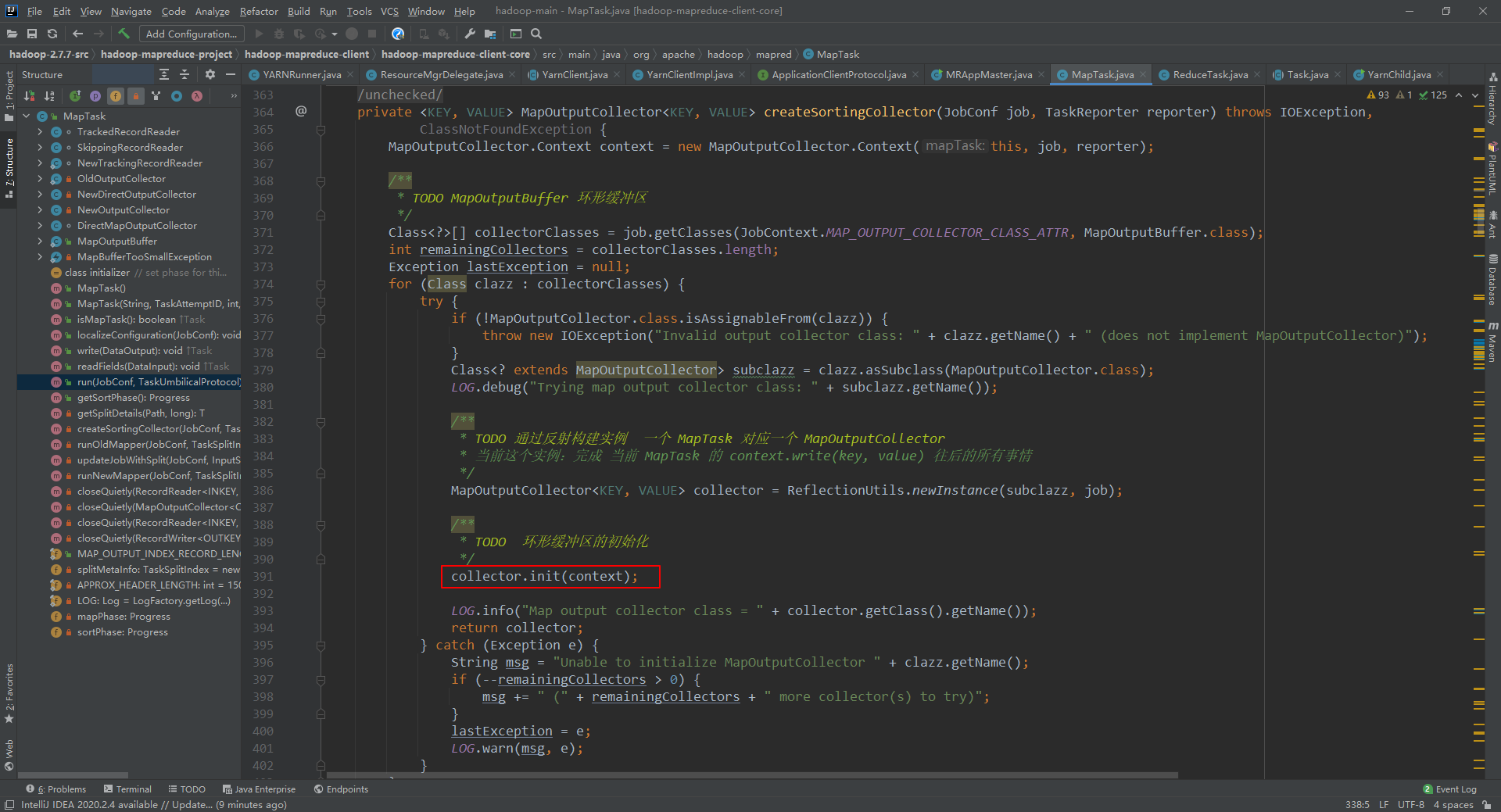
12、环形缓冲区存在maptask内部类


1 @InterfaceAudience.LimitedPrivate({"MapReduce"}) 2 @InterfaceStability.Unstable 3 public static class MapOutputBuffer<K extends Object, V extends Object> implements MapOutputCollector<K, V>, IndexedSortable { 4 private int partitions; 5 private JobConf job; 6 private TaskReporter reporter; 7 private Class<K> keyClass; 8 private Class<V> valClass; 9 private RawComparator<K> comparator; 10 private SerializationFactory serializationFactory; 11 private Serializer<K> keySerializer; 12 private Serializer<V> valSerializer; 13 private CombinerRunner<K, V> combinerRunner; 14 private CombineOutputCollector<K, V> combineCollector; 15 16 // Compression for map-outputs 17 private CompressionCodec codec; 18 19 // k/v accounting 20 private IntBuffer kvmeta; // metadata overlay on backing store 21 int kvstart; // marks origin of spill metadata 22 int kvend; // marks end of spill metadata 23 int kvindex; // marks end of fully serialized records 24 25 int equator; // marks origin of meta/serialization 26 int bufstart; // marks beginning of spill 27 int bufend; // marks beginning of collectable 28 int bufmark; // marks end of record 29 int bufindex; // marks end of collected 30 int bufvoid; // marks the point where we should stop 31 // reading at the end of the buffer 32 33 byte[] kvbuffer; // main output buffer 34 private final byte[] b0 = new byte[0]; 35 36 private static final int VALSTART = 0; // val offset in acct 37 private static final int KEYSTART = 1; // key offset in acct 38 private static final int PARTITION = 2; // partition offset in acct 39 private static final int VALLEN = 3; // length of value 40 private static final int NMETA = 4; // num meta ints 41 private static final int METASIZE = NMETA * 4; // size in bytes 42 43 // spill accounting 44 private int maxRec; 45 private int softLimit; 46 boolean spillInProgress; 47 ; 48 int bufferRemaining; 49 volatile Throwable sortSpillException = null; 50 51 int numSpills = 0; 52 private int minSpillsForCombine; 53 private IndexedSorter sorter; 54 final ReentrantLock spillLock = new ReentrantLock(); 55 final Condition spillDone = spillLock.newCondition(); 56 final Condition spillReady = spillLock.newCondition(); 57 final BlockingBuffer bb = new BlockingBuffer(); 58 volatile boolean spillThreadRunning = false; 59 final SpillThread spillThread = new SpillThread(); 60 61 private FileSystem rfs; 62 63 // Counters 64 private Counters.Counter mapOutputByteCounter; 65 private Counters.Counter mapOutputRecordCounter; 66 private Counters.Counter fileOutputByteCounter; 67 68 final ArrayList<SpillRecord> indexCacheList = new ArrayList<SpillRecord>(); 69 private int totalIndexCacheMemory; 70 private int indexCacheMemoryLimit; 71 private static final int INDEX_CACHE_MEMORY_LIMIT_DEFAULT = 1024 * 1024; 72 73 private MapTask mapTask; 74 private MapOutputFile mapOutputFile; 75 private Progress sortPhase; 76 private Counters.Counter spilledRecordsCounter; 77 78 public MapOutputBuffer() { 79 } 80 81 @SuppressWarnings("unchecked") 82 public void init(MapOutputCollector.Context context) throws IOException, ClassNotFoundException { 83 job = context.getJobConf(); 84 reporter = context.getReporter(); 85 mapTask = context.getMapTask(); 86 mapOutputFile = mapTask.getMapOutputFile(); 87 sortPhase = mapTask.getSortPhase(); 88 spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS); 89 partitions = job.getNumReduceTasks(); 90 rfs = ((LocalFileSystem) FileSystem.getLocal(job)).getRaw(); 91 92 //sanity checks 93 final float spillper = job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float) 0.8); 94 final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100); 95 indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT, INDEX_CACHE_MEMORY_LIMIT_DEFAULT); 96 if (spillper > (float) 1.0 || spillper <= (float) 0.0) { 97 throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT + "\": " + spillper); 98 } 99 if ((sortmb & 0x7FF) != sortmb) { 100 throw new IOException("Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb); 101 } 102 sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job); 103 104 /** 105 * TODO 从 100M 中分出来一部分用来存储真实数据 106 */ 107 // buffers and accounting 108 int maxMemUsage = sortmb << 20; 109 maxMemUsage -= maxMemUsage % METASIZE; 110 kvbuffer = new byte[maxMemUsage]; 111 112 bufvoid = kvbuffer.length; 113 kvmeta = ByteBuffer.wrap(kvbuffer).order(ByteOrder.nativeOrder()).asIntBuffer(); 114 setEquator(0); 115 bufstart = bufend = bufindex = equator; 116 kvstart = kvend = kvindex; 117 118 maxRec = kvmeta.capacity() / NMETA; 119 softLimit = (int) (kvbuffer.length * spillper); 120 bufferRemaining = softLimit; 121 LOG.info(JobContext.IO_SORT_MB + ": " + sortmb); 122 LOG.info("soft limit at " + softLimit); 123 LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid); 124 LOG.info("kvstart = " + kvstart + "; length = " + maxRec); 125 126 // k/v serialization 127 comparator = job.getOutputKeyComparator(); 128 keyClass = (Class<K>) job.getMapOutputKeyClass(); 129 valClass = (Class<V>) job.getMapOutputValueClass(); 130 serializationFactory = new SerializationFactory(job); 131 keySerializer = serializationFactory.getSerializer(keyClass); 132 keySerializer.open(bb); 133 valSerializer = serializationFactory.getSerializer(valClass); 134 valSerializer.open(bb); 135 136 // output counters 137 mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES); 138 mapOutputRecordCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS); 139 fileOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES); 140 141 // compression 142 if (job.getCompressMapOutput()) { 143 Class<? extends CompressionCodec> codecClass = job.getMapOutputCompressorClass(DefaultCodec.class); 144 codec = ReflectionUtils.newInstance(codecClass, job); 145 } else { 146 codec = null; 147 } 148 149 // combiner 150 final Counters.Counter combineInputCounter = reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS); 151 combinerRunner = CombinerRunner.create(job, getTaskID(), combineInputCounter, reporter, null); 152 if (combinerRunner != null) { 153 final Counters.Counter combineOutputCounter = reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS); 154 combineCollector = new CombineOutputCollector<K, V>(combineOutputCounter, reporter, job); 155 } else { 156 combineCollector = null; 157 } 158 spillInProgress = false; 159 minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3); 160 spillThread.setDaemon(true); 161 spillThread.setName("SpillThread"); 162 163 /** 164 * TODO 当前 MpaOutputBuffer 这个环形缓冲区的管理类,事实上管理了两个重要的东西: 165 * 1、100M 大小的字节数组 166 * 2、SpillThread 负责 kvBuffer 中装满了的 80% 空间的数据的溢写 167 */ 168 spillLock.lock(); 169 try { 170 spillThread.start(); 171 while (!spillThreadRunning) { 172 spillDone.await(); 173 } 174 } catch (InterruptedException e) { 175 throw new IOException("Spill thread failed to initialize", e); 176 } finally { 177 spillLock.unlock(); 178 } 179 if (sortSpillException != null) { 180 throw new IOException("Spill thread failed to initialize", sortSpillException); 181 } 182 } 183 184 /** 185 * Serialize the key, value to intermediate storage. 186 * When this method returns, kvindex must refer to sufficient unused 187 * storage to store one METADATA. 188 * 189 * 真正完成数据从mapper写出到 环形缓冲区 190 */ 191 public synchronized void collect(K key, V value, final int partition) throws IOException { 192 reporter.progress(); 193 if (key.getClass() != keyClass) { 194 throw new IOException("Type mismatch in key from map: expected " + keyClass.getName() + ", received " + key.getClass().getName()); 195 } 196 if (value.getClass() != valClass) { 197 throw new IOException("Type mismatch in value from map: expected " + valClass.getName() + ", received " + value.getClass().getName()); 198 } 199 if (partition < 0 || partition >= partitions) { 200 throw new IOException("Illegal partition for " + key + " (" + partition + ")"); 201 } 202 checkSpillException(); 203 bufferRemaining -= METASIZE; 204 if (bufferRemaining <= 0) { 205 // start spill if the thread is not running and the soft limit has been 206 // reached 207 spillLock.lock(); 208 try { 209 do { 210 if (!spillInProgress) { 211 final int kvbidx = 4 * kvindex; 212 final int kvbend = 4 * kvend; 213 // serialized, unspilled bytes always lie between kvindex and 214 // bufindex, crossing the equator. Note that any void space 215 // created by a reset must be included in "used" bytes 216 final int bUsed = distanceTo(kvbidx, bufindex); 217 final boolean bufsoftlimit = bUsed >= softLimit; 218 if ((kvbend + METASIZE) % kvbuffer.length != equator - (equator % METASIZE)) { 219 // spill finished, reclaim space 220 resetSpill(); 221 bufferRemaining = Math.min(distanceTo(bufindex, kvbidx) - 2 * METASIZE, softLimit - bUsed) - METASIZE; 222 continue; 223 } else if (bufsoftlimit && kvindex != kvend) { 224 // spill records, if any collected; check latter, as it may 225 // be possible for metadata alignment to hit spill pcnt 226 startSpill(); 227 final int avgRec = (int) (mapOutputByteCounter.getCounter() / mapOutputRecordCounter.getCounter()); 228 // leave at least half the split buffer for serialization data 229 // ensure that kvindex >= bufindex 230 final int distkvi = distanceTo(bufindex, kvbidx); 231 final int newPos = (bufindex + Math 232 .max(2 * METASIZE - 1, Math.min(distkvi / 2, distkvi / (METASIZE + avgRec) * METASIZE))) % kvbuffer.length; 233 setEquator(newPos); 234 bufmark = bufindex = newPos; 235 final int serBound = 4 * kvend; 236 // bytes remaining before the lock must be held and limits 237 // checked is the minimum of three arcs: the metadata space, the 238 // serialization space, and the soft limit 239 bufferRemaining = Math.min( 240 // metadata max 241 distanceTo(bufend, newPos), Math.min( 242 // serialization max 243 distanceTo(newPos, serBound), 244 // soft limit 245 softLimit)) - 2 * METASIZE; 246 } 247 } 248 } while (false); 249 } finally { 250 spillLock.unlock(); 251 } 252 } 253 254 try { 255 // serialize key bytes into buffer 256 int keystart = bufindex; 257 keySerializer.serialize(key); 258 if (bufindex < keystart) { 259 // wrapped the key; must make contiguous 260 bb.shiftBufferedKey(); 261 keystart = 0; 262 } 263 // serialize value bytes into buffer 264 final int valstart = bufindex; 265 valSerializer.serialize(value); 266 // It's possible for records to have zero length, i.e. the serializer 267 // will perform no writes. To ensure that the boundary conditions are 268 // checked and that the kvindex invariant is maintained, perform a 269 // zero-length write into the buffer. The logic monitoring this could be 270 // moved into collect, but this is cleaner and inexpensive. For now, it 271 // is acceptable. 272 bb.write(b0, 0, 0); 273 274 // the record must be marked after the preceding write, as the metadata 275 // for this record are not yet written 276 int valend = bb.markRecord(); 277 278 mapOutputRecordCounter.increment(1); 279 mapOutputByteCounter.increment(distanceTo(keystart, valend, bufvoid)); 280 281 // write accounting info 282 kvmeta.put(kvindex + PARTITION, partition); 283 kvmeta.put(kvindex + KEYSTART, keystart); 284 kvmeta.put(kvindex + VALSTART, valstart); 285 kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend)); 286 // advance kvindex 287 kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity(); 288 } catch (MapBufferTooSmallException e) { 289 LOG.info("Record too large for in-memory buffer: " + e.getMessage()); 290 spillSingleRecord(key, value, partition); 291 mapOutputRecordCounter.increment(1); 292 return; 293 } 294 } 295 296 private TaskAttemptID getTaskID() { 297 return mapTask.getTaskID(); 298 } 299 300 /** 301 * Set the point from which meta and serialization data expand. The meta 302 * indices are aligned with the buffer, so metadata never spans the ends of 303 * the circular buffer. 304 */ 305 private void setEquator(int pos) { 306 equator = pos; 307 // set index prior to first entry, aligned at meta boundary 308 final int aligned = pos - (pos % METASIZE); 309 // Cast one of the operands to long to avoid integer overflow 310 kvindex = (int) (((long) aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4; 311 LOG.info("(EQUATOR) " + pos + " kvi " + kvindex + "(" + (kvindex * 4) + ")"); 312 } 313 314 /** 315 * The spill is complete, so set the buffer and meta indices to be equal to 316 * the new equator to free space for continuing collection. Note that when 317 * kvindex == kvend == kvstart, the buffer is empty. 318 */ 319 private void resetSpill() { 320 final int e = equator; 321 bufstart = bufend = e; 322 final int aligned = e - (e % METASIZE); 323 // set start/end to point to first meta record 324 // Cast one of the operands to long to avoid integer overflow 325 kvstart = kvend = (int) (((long) aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4; 326 LOG.info("(RESET) equator " + e + " kv " + kvstart + "(" + (kvstart * 4) + ")" + " kvi " + kvindex + "(" + (kvindex * 4) + ")"); 327 } 328 329 /** 330 * Compute the distance in bytes between two indices in the serialization 331 * buffer. 332 * 333 * @see #distanceTo(int, int, int) 334 */ 335 final int distanceTo(final int i, final int j) { 336 return distanceTo(i, j, kvbuffer.length); 337 } 338 339 /** 340 * Compute the distance between two indices in the circular buffer given the 341 * max distance. 342 */ 343 int distanceTo(final int i, final int j, final int mod) { 344 return i <= j ? j - i : mod - i + j; 345 } 346 347 /** 348 * For the given meta position, return the offset into the int-sized 349 * kvmeta buffer. 350 */ 351 int offsetFor(int metapos) { 352 return metapos * NMETA; 353 } 354 355 /** 356 * Compare logical range, st i, j MOD offset capacity. 357 * Compare by partition, then by key. 358 * 359 * @see IndexedSortable#compare 360 */ 361 public int compare(final int mi, final int mj) { 362 final int kvi = offsetFor(mi % maxRec); 363 final int kvj = offsetFor(mj % maxRec); 364 final int kvip = kvmeta.get(kvi + PARTITION); 365 final int kvjp = kvmeta.get(kvj + PARTITION); 366 // sort by partition 367 if (kvip != kvjp) { 368 return kvip - kvjp; 369 } 370 // sort by key 371 return comparator.compare(kvbuffer, kvmeta.get(kvi + KEYSTART), kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART), kvbuffer, kvmeta 372 .get(kvj + KEYSTART), kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART)); 373 } 374 375 final byte META_BUFFER_TMP[] = new byte[METASIZE]; 376 377 /** 378 * Swap metadata for items i, j 379 * 380 * @see IndexedSortable#swap 381 */ 382 public void swap(final int mi, final int mj) { 383 int iOff = (mi % maxRec) * METASIZE; 384 int jOff = (mj % maxRec) * METASIZE; 385 System.arraycopy(kvbuffer, iOff, META_BUFFER_TMP, 0, METASIZE); 386 System.arraycopy(kvbuffer, jOff, kvbuffer, iOff, METASIZE); 387 System.arraycopy(META_BUFFER_TMP, 0, kvbuffer, jOff, METASIZE); 388 } 389 390 /** 391 * Inner class managing the spill of serialized records to disk. 392 */ 393 protected class BlockingBuffer extends DataOutputStream { 394 395 public BlockingBuffer() { 396 super(new Buffer()); 397 } 398 399 /** 400 * Mark end of record. Note that this is required if the buffer is to 401 * cut the spill in the proper place. 402 */ 403 public int markRecord() { 404 bufmark = bufindex; 405 return bufindex; 406 } 407 408 /** 409 * Set position from last mark to end of writable buffer, then rewrite 410 * the data between last mark and kvindex. 411 * This handles a special case where the key wraps around the buffer. 412 * If the key is to be passed to a RawComparator, then it must be 413 * contiguous in the buffer. This recopies the data in the buffer back 414 * into itself, but starting at the beginning of the buffer. Note that 415 * this method should <b>only</b> be called immediately after detecting 416 * this condition. To call it at any other time is undefined and would 417 * likely result in data loss or corruption. 418 * 419 * @see #markRecord() 420 */ 421 protected void shiftBufferedKey() throws IOException { 422 // spillLock unnecessary; both kvend and kvindex are current 423 int headbytelen = bufvoid - bufmark; 424 bufvoid = bufmark; 425 final int kvbidx = 4 * kvindex; 426 final int kvbend = 4 * kvend; 427 final int avail = Math.min(distanceTo(0, kvbidx), distanceTo(0, kvbend)); 428 if (bufindex + headbytelen < avail) { 429 System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex); 430 System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen); 431 bufindex += headbytelen; 432 bufferRemaining -= kvbuffer.length - bufvoid; 433 } else { 434 byte[] keytmp = new byte[bufindex]; 435 System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex); 436 bufindex = 0; 437 out.write(kvbuffer, bufmark, headbytelen); 438 out.write(keytmp); 439 } 440 } 441 } 442 443 public class Buffer extends OutputStream { 444 private final byte[] scratch = new byte[1]; 445 446 @Override 447 public void write(int v) throws IOException { 448 scratch[0] = (byte) v; 449 write(scratch, 0, 1); 450 } 451 452 /** 453 * Attempt to write a sequence of bytes to the collection buffer. 454 * This method will block if the spill thread is running and it 455 * cannot write. 456 * 457 * @throws MapBufferTooSmallException if record is too large to 458 * deserialize into the collection buffer. 459 */ 460 @Override 461 public void write(byte b[], int off, int len) throws IOException { 462 // must always verify the invariant that at least METASIZE bytes are 463 // available beyond kvindex, even when len == 0 464 bufferRemaining -= len; 465 if (bufferRemaining <= 0) { 466 // writing these bytes could exhaust available buffer space or fill 467 // the buffer to soft limit. check if spill or blocking are necessary 468 boolean blockwrite = false; 469 spillLock.lock(); 470 try { 471 do { 472 checkSpillException(); 473 474 final int kvbidx = 4 * kvindex; 475 final int kvbend = 4 * kvend; 476 // ser distance to key index 477 final int distkvi = distanceTo(bufindex, kvbidx); 478 // ser distance to spill end index 479 final int distkve = distanceTo(bufindex, kvbend); 480 481 // if kvindex is closer than kvend, then a spill is neither in 482 // progress nor complete and reset since the lock was held. The 483 // write should block only if there is insufficient space to 484 // complete the current write, write the metadata for this record, 485 // and write the metadata for the next record. If kvend is closer, 486 // then the write should block if there is too little space for 487 // either the metadata or the current write. Note that collect 488 // ensures its metadata requirement with a zero-length write 489 blockwrite = distkvi <= distkve ? distkvi <= len + 2 * METASIZE : 490 distkve <= len || distanceTo(bufend, kvbidx) < 2 * METASIZE; 491 492 if (!spillInProgress) { 493 if (blockwrite) { 494 if ((kvbend + METASIZE) % kvbuffer.length != equator - (equator % METASIZE)) { 495 // spill finished, reclaim space 496 // need to use meta exclusively; zero-len rec & 100% spill 497 // pcnt would fail 498 resetSpill(); // resetSpill doesn't move bufindex, kvindex 499 bufferRemaining = Math.min(distkvi - 2 * METASIZE, softLimit - distanceTo(kvbidx, bufindex)) - len; 500 continue; 501 } 502 // we have records we can spill; only spill if blocked 503 if (kvindex != kvend) { 504 startSpill(); 505 // Blocked on this write, waiting for the spill just 506 // initiated to finish. Instead of repositioning the marker 507 // and copying the partial record, we set the record start 508 // to be the new equator 509 setEquator(bufmark); 510 } else { 511 // We have no buffered records, and this record is too large 512 // to write into kvbuffer. We must spill it directly from 513 // collect 514 final int size = distanceTo(bufstart, bufindex) + len; 515 setEquator(0); 516 bufstart = bufend = bufindex = equator; 517 kvstart = kvend = kvindex; 518 bufvoid = kvbuffer.length; 519 throw new MapBufferTooSmallException(size + " bytes"); 520 } 521 } 522 } 523 524 if (blockwrite) { 525 // wait for spill 526 try { 527 while (spillInProgress) { 528 reporter.progress(); 529 spillDone.await(); 530 } 531 } catch (InterruptedException e) { 532 throw new IOException("Buffer interrupted while waiting for the writer", e); 533 } 534 } 535 } while (blockwrite); 536 } finally { 537 spillLock.unlock(); 538 } 539 } 540 // here, we know that we have sufficient space to write 541 if (bufindex + len > bufvoid) { 542 final int gaplen = bufvoid - bufindex; 543 System.arraycopy(b, off, kvbuffer, bufindex, gaplen); 544 len -= gaplen; 545 off += gaplen; 546 bufindex = 0; 547 } 548 System.arraycopy(b, off, kvbuffer, bufindex, len); 549 bufindex += len; 550 } 551 } 552 553 public void flush() throws IOException, ClassNotFoundException, InterruptedException { 554 LOG.info("Starting flush of map output"); 555 if (kvbuffer == null) { 556 LOG.info("kvbuffer is null. Skipping flush."); 557 return; 558 } 559 spillLock.lock(); 560 try { 561 while (spillInProgress) { 562 reporter.progress(); 563 spillDone.await(); 564 } 565 checkSpillException(); 566 567 final int kvbend = 4 * kvend; 568 if ((kvbend + METASIZE) % kvbuffer.length != equator - (equator % METASIZE)) { 569 // spill finished 570 resetSpill(); 571 } 572 if (kvindex != kvend) { 573 kvend = (kvindex + NMETA) % kvmeta.capacity(); 574 bufend = bufmark; 575 LOG.info("Spilling map output"); 576 LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark + "; bufvoid = " + bufvoid); 577 LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) + "); kvend = " + kvend + "(" + (kvend * 4) + "); length = " + (distanceTo(kvend, kvstart, kvmeta 578 .capacity()) + 1) + "/" + maxRec); 579 sortAndSpill(); 580 } 581 } catch (InterruptedException e) { 582 throw new IOException("Interrupted while waiting for the writer", e); 583 } finally { 584 spillLock.unlock(); 585 } 586 assert !spillLock.isHeldByCurrentThread(); 587 // shut down spill thread and wait for it to exit. Since the preceding 588 // ensures that it is finished with its work (and sortAndSpill did not 589 // throw), we elect to use an interrupt instead of setting a flag. 590 // Spilling simultaneously from this thread while the spill thread 591 // finishes its work might be both a useful way to extend this and also 592 // sufficient motivation for the latter approach. 593 try { 594 spillThread.interrupt(); 595 spillThread.join(); 596 } catch (InterruptedException e) { 597 throw new IOException("Spill failed", e); 598 } 599 // release sort buffer before the merge 600 kvbuffer = null; 601 mergeParts(); 602 Path outputPath = mapOutputFile.getOutputFile(); 603 fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen()); 604 } 605 606 public void close() { 607 } 608 609 protected class SpillThread extends Thread { 610 611 @Override 612 public void run() { 613 spillLock.lock(); 614 spillThreadRunning = true; 615 try { 616 while (true) { 617 618 /** 619 * TODO 等信号 620 */ 621 spillDone.signal(); 622 while (!spillInProgress) { 623 spillReady.await(); 624 } 625 try { 626 spillLock.unlock(); 627 628 /** 629 * TODO 这个方法就是溢写操作的实现 630 */ 631 sortAndSpill(); 632 633 } catch (Throwable t) { 634 sortSpillException = t; 635 } finally { 636 spillLock.lock(); 637 if (bufend < bufstart) { 638 bufvoid = kvbuffer.length; 639 } 640 kvstart = kvend; 641 bufstart = bufend; 642 spillInProgress = false; 643 } 644 } 645 } catch (InterruptedException e) { 646 Thread.currentThread().interrupt(); 647 } finally { 648 spillLock.unlock(); 649 spillThreadRunning = false; 650 } 651 } 652 } 653 654 private void checkSpillException() throws IOException { 655 final Throwable lspillException = sortSpillException; 656 if (lspillException != null) { 657 if (lspillException instanceof Error) { 658 final String logMsg = "Task " + getTaskID() + " failed : " + StringUtils.stringifyException(lspillException); 659 mapTask.reportFatalError(getTaskID(), lspillException, logMsg); 660 } 661 throw new IOException("Spill failed", lspillException); 662 } 663 } 664 665 private void startSpill() { 666 assert !spillInProgress; 667 kvend = (kvindex + NMETA) % kvmeta.capacity(); 668 bufend = bufmark; 669 spillInProgress = true; 670 LOG.info("Spilling map output"); 671 LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark + "; bufvoid = " + bufvoid); 672 LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) + "); kvend = " + kvend + "(" + (kvend * 4) + "); length = " + (distanceTo(kvend, 673 kvstart, kvmeta 674 .capacity()) + 1) + "/" + maxRec); 675 spillReady.signal(); 676 } 677 678 private void sortAndSpill() throws IOException, ClassNotFoundException, InterruptedException { 679 //approximate the length of the output file to be the length of the 680 //buffer + header lengths for the partitions 681 final long size = distanceTo(bufstart, bufend, bufvoid) + partitions * APPROX_HEADER_LENGTH; 682 FSDataOutputStream out = null; 683 try { 684 // create spill file 685 final SpillRecord spillRec = new SpillRecord(partitions); 686 final Path filename = mapOutputFile.getSpillFileForWrite(numSpills, size); 687 out = rfs.create(filename); 688 689 final int mstart = kvend / NMETA; 690 final int mend = 1 + // kvend is a valid record 691 (kvstart >= kvend ? kvstart : kvmeta.capacity() + kvstart) / NMETA; 692 sorter.sort(MapOutputBuffer.this, mstart, mend, reporter); 693 int spindex = mstart; 694 final IndexRecord rec = new IndexRecord(); 695 final InMemValBytes value = new InMemValBytes(); 696 for (int i = 0; i < partitions; ++i) { 697 IFile.Writer<K, V> writer = null; 698 try { 699 long segmentStart = out.getPos(); 700 FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out); 701 writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec, spilledRecordsCounter); 702 if (combinerRunner == null) { 703 // spill directly 704 DataInputBuffer key = new DataInputBuffer(); 705 while (spindex < mend && kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) { 706 final int kvoff = offsetFor(spindex % maxRec); 707 int keystart = kvmeta.get(kvoff + KEYSTART); 708 int valstart = kvmeta.get(kvoff + VALSTART); 709 key.reset(kvbuffer, keystart, valstart - keystart); 710 getVBytesForOffset(kvoff, value); 711 writer.append(key, value); 712 ++spindex; 713 } 714 } else { 715 int spstart = spindex; 716 while (spindex < mend && kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) { 717 ++spindex; 718 } 719 // Note: we would like to avoid the combiner if we've fewer 720 // than some threshold of records for a partition 721 if (spstart != spindex) { 722 combineCollector.setWriter(writer); 723 RawKeyValueIterator kvIter = new MRResultIterator(spstart, spindex); 724 combinerRunner.combine(kvIter, combineCollector); 725 } 726 } 727 728 // close the writer 729 writer.close(); 730 731 // record offsets 732 rec.startOffset = segmentStart; 733 rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job); 734 rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job); 735 spillRec.putIndex(rec, i); 736 737 writer = null; 738 } finally { 739 if (null != writer) { 740 writer.close(); 741 } 742 } 743 } 744 745 if (totalIndexCacheMemory >= indexCacheMemoryLimit) { 746 // create spill index file 747 Path indexFilename = mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH); 748 spillRec.writeToFile(indexFilename, job); 749 } else { 750 indexCacheList.add(spillRec); 751 totalIndexCacheMemory += spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH; 752 } 753 LOG.info("Finished spill " + numSpills); 754 ++numSpills; 755 } finally { 756 if (out != null) { 757 out.close(); 758 } 759 } 760 } 761 762 /** 763 * Handles the degenerate case where serialization fails to fit in 764 * the in-memory buffer, so we must spill the record from collect 765 * directly to a spill file. Consider this "losing". 766 */ 767 private void spillSingleRecord( 768 final K key, final V value, int partition) throws IOException { 769 long size = kvbuffer.length + partitions * APPROX_HEADER_LENGTH; 770 FSDataOutputStream out = null; 771 try { 772 // create spill file 773 final SpillRecord spillRec = new SpillRecord(partitions); 774 final Path filename = mapOutputFile.getSpillFileForWrite(numSpills, size); 775 out = rfs.create(filename); 776 777 // we don't run the combiner for a single record 778 IndexRecord rec = new IndexRecord(); 779 for (int i = 0; i < partitions; ++i) { 780 IFile.Writer<K, V> writer = null; 781 try { 782 long segmentStart = out.getPos(); 783 // Create a new codec, don't care! 784 FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out); 785 writer = new IFile.Writer<K, V>(job, partitionOut, keyClass, valClass, codec, spilledRecordsCounter); 786 787 if (i == partition) { 788 final long recordStart = out.getPos(); 789 writer.append(key, value); 790 // Note that our map byte count will not be accurate with 791 // compression 792 mapOutputByteCounter.increment(out.getPos() - recordStart); 793 } 794 writer.close(); 795 796 // record offsets 797 rec.startOffset = segmentStart; 798 rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job); 799 rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job); 800 spillRec.putIndex(rec, i); 801 802 writer = null; 803 } catch (IOException e) { 804 if (null != writer) { 805 writer.close(); 806 } 807 throw e; 808 } 809 } 810 if (totalIndexCacheMemory >= indexCacheMemoryLimit) { 811 // create spill index file 812 Path indexFilename = mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH); 813 spillRec.writeToFile(indexFilename, job); 814 } else { 815 indexCacheList.add(spillRec); 816 totalIndexCacheMemory += spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH; 817 } 818 ++numSpills; 819 } finally { 820 if (out != null) { 821 out.close(); 822 } 823 } 824 } 825 826 /** 827 * Given an offset, populate vbytes with the associated set of 828 * deserialized value bytes. Should only be called during a spill. 829 */ 830 private void getVBytesForOffset(int kvoff, InMemValBytes vbytes) { 831 // get the keystart for the next serialized value to be the end 832 // of this value. If this is the last value in the buffer, use bufend 833 final int vallen = kvmeta.get(kvoff + VALLEN); 834 assert vallen >= 0; 835 vbytes.reset(kvbuffer, kvmeta.get(kvoff + VALSTART), vallen); 836 } 837 838 /** 839 * Inner class wrapping valuebytes, used for appendRaw. 840 */ 841 protected class InMemValBytes extends DataInputBuffer { 842 private byte[] buffer; 843 private int start; 844 private int length; 845 846 public void reset(byte[] buffer, int start, int length) { 847 this.buffer = buffer; 848 this.start = start; 849 this.length = length; 850 851 if (start + length > bufvoid) { 852 this.buffer = new byte[this.length]; 853 final int taillen = bufvoid - start; 854 System.arraycopy(buffer, start, this.buffer, 0, taillen); 855 System.arraycopy(buffer, 0, this.buffer, taillen, length - taillen); 856 this.start = 0; 857 } 858 859 super.reset(this.buffer, this.start, this.length); 860 } 861 } 862 863 protected class MRResultIterator implements RawKeyValueIterator { 864 private final DataInputBuffer keybuf = new DataInputBuffer(); 865 private final InMemValBytes vbytes = new InMemValBytes(); 866 private final int end; 867 private int current; 868 869 public MRResultIterator(int start, int end) { 870 this.end = end; 871 current = start - 1; 872 } 873 874 public boolean next() throws IOException { 875 return ++current < end; 876 } 877 878 public DataInputBuffer getKey() throws IOException { 879 final int kvoff = offsetFor(current % maxRec); 880 keybuf.reset(kvbuffer, kvmeta.get(kvoff + KEYSTART), kvmeta.get(kvoff + VALSTART) - kvmeta.get(kvoff + KEYSTART)); 881 return keybuf; 882 } 883 884 public DataInputBuffer getValue() throws IOException { 885 getVBytesForOffset(offsetFor(current % maxRec), vbytes); 886 return vbytes; 887 } 888 889 public Progress getProgress() { 890 return null; 891 } 892 893 public void close() { 894 } 895 } 896 897 private void mergeParts() throws IOException, InterruptedException, ClassNotFoundException { 898 // get the approximate size of the final output/index files 899 long finalOutFileSize = 0; 900 long finalIndexFileSize = 0; 901 final Path[] filename = new Path[numSpills]; 902 final TaskAttemptID mapId = getTaskID(); 903 904 for (int i = 0; i < numSpills; i++) { 905 filename[i] = mapOutputFile.getSpillFile(i); 906 finalOutFileSize += rfs.getFileStatus(filename[i]).getLen(); 907 } 908 if (numSpills == 1) { //the spill is the final output 909 sameVolRename(filename[0], mapOutputFile.getOutputFileForWriteInVolume(filename[0])); 910 if (indexCacheList.size() == 0) { 911 sameVolRename(mapOutputFile.getSpillIndexFile(0), mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0])); 912 } else { 913 indexCacheList.get(0).writeToFile(mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job); 914 } 915 sortPhase.complete(); 916 return; 917 } 918 919 // read in paged indices 920 for (int i = indexCacheList.size(); i < numSpills; ++i) { 921 Path indexFileName = mapOutputFile.getSpillIndexFile(i); 922 indexCacheList.add(new SpillRecord(indexFileName, job)); 923 } 924 925 //make correction in the length to include the sequence file header 926 //lengths for each partition 927 finalOutFileSize += partitions * APPROX_HEADER_LENGTH; 928 finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH; 929 Path finalOutputFile = mapOutputFile.getOutputFileForWrite(finalOutFileSize); 930 Path finalIndexFile = mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize); 931 932 //The output stream for the final single output file 933 FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096); 934 935 if (numSpills == 0) { 936 //create dummy files 937 IndexRecord rec = new IndexRecord(); 938 SpillRecord sr = new SpillRecord(partitions); 939 try { 940 for (int i = 0; i < partitions; i++) { 941 long segmentStart = finalOut.getPos(); 942 FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut); 943 Writer<K, V> writer = new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec, null); 944 writer.close(); 945 rec.startOffset = segmentStart; 946 rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job); 947 rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job); 948 sr.putIndex(rec, i); 949 } 950 sr.writeToFile(finalIndexFile, job); 951 } finally { 952 finalOut.close(); 953 } 954 sortPhase.complete(); 955 return; 956 } 957 { 958 sortPhase.addPhases(partitions); // Divide sort phase into sub-phases 959 960 IndexRecord rec = new IndexRecord(); 961 final SpillRecord spillRec = new SpillRecord(partitions); 962 for (int parts = 0; parts < partitions; parts++) { 963 //create the segments to be merged 964 List<Segment<K, V>> segmentList = new ArrayList<Segment<K, V>>(numSpills); 965 for (int i = 0; i < numSpills; i++) { 966 IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts); 967 968 Segment<K, V> s = new Segment<K, V>(job, rfs, filename[i], indexRecord.startOffset, indexRecord.partLength, codec, true); 969 segmentList.add(i, s); 970 971 if (LOG.isDebugEnabled()) { 972 LOG.debug("MapId=" + mapId + " Reducer=" + parts + "Spill =" + i + "(" + indexRecord.startOffset + "," + indexRecord.rawLength + ", " + indexRecord.partLength + ")"); 973 } 974 } 975 976 int mergeFactor = job.getInt(JobContext.IO_SORT_FACTOR, 100); 977 // sort the segments only if there are intermediate merges 978 boolean sortSegments = segmentList.size() > mergeFactor; 979 //merge 980 @SuppressWarnings("unchecked") RawKeyValueIterator kvIter = Merger 981 .merge(job, rfs, keyClass, valClass, codec, segmentList, mergeFactor, new Path(mapId.toString()), job 982 .getOutputKeyComparator(), reporter, sortSegments, null, spilledRecordsCounter, sortPhase.phase(), TaskType.MAP); 983 984 //write merged output to disk 985 long segmentStart = finalOut.getPos(); 986 FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut); 987 Writer<K, V> writer = new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec, spilledRecordsCounter); 988 if (combinerRunner == null || numSpills < minSpillsForCombine) { 989 Merger.writeFile(kvIter, writer, reporter, job); 990 } else { 991 combineCollector.setWriter(writer); 992 combinerRunner.combine(kvIter, combineCollector); 993 } 994 995 //close 996 writer.close(); 997 998 sortPhase.startNextPhase(); 999 1000 // record offsets 1001 rec.startOffset = segmentStart; 1002 rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job); 1003 rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job); 1004 spillRec.putIndex(rec, parts); 1005 } 1006 spillRec.writeToFile(finalIndexFile, job); 1007 finalOut.close(); 1008 for (int i = 0; i < numSpills; i++) { 1009 rfs.delete(filename[i], true); 1010 } 1011 } 1012 } 1013 1014 /** 1015 * Rename srcPath to dstPath on the same volume. This is the same 1016 * as RawLocalFileSystem's rename method, except that it will not 1017 * fall back to a copy, and it will create the target directory 1018 * if it doesn't exist. 1019 */ 1020 private void sameVolRename( 1021 Path srcPath, Path dstPath) throws IOException { 1022 RawLocalFileSystem rfs = (RawLocalFileSystem) this.rfs; 1023 File src = rfs.pathToFile(srcPath); 1024 File dst = rfs.pathToFile(dstPath); 1025 if (!dst.getParentFile().exists()) { 1026 if (!dst.getParentFile().mkdirs()) { 1027 throw new IOException("Unable to rename " + src + " to " + dst + ": couldn't create parent directory"); 1028 } 1029 } 1030 1031 if (!src.renameTo(dst)) { 1032 throw new IOException("Unable to rename " + src + " to " + dst); 1033 } 1034 } 1035 } // MapOutputBuffer 1036


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-05-09 zookeeper客户端命令行操作