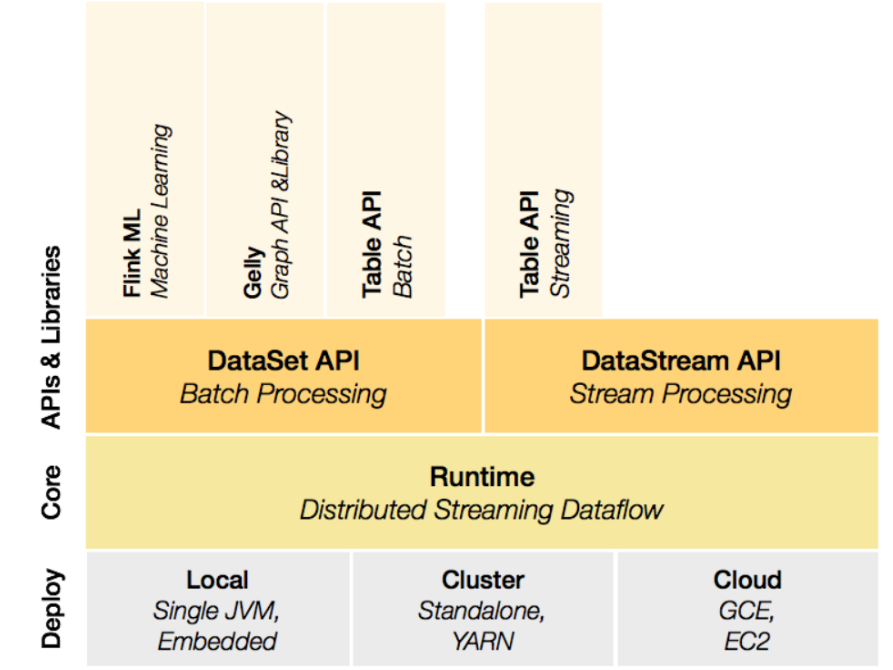
flink详细介绍
-
Flink是一个分布式计算引擎 MapReduce Spark Storm
-
同时支持流计算和批处理
-
和Spark不同, Flink是使用流的思想做批, Spark是采用做批的思想做流
-
-
Flink的优势
-
和Hadoop相比, Flink使用内存进行计算, 速度明显更优
-
和同样使用内存的Spark相比, Flink对于流的计算是实时的, 延迟更低
-
和同样使用实时流的Storm相比, Flink明显具有更优秀的API, 以及更多的支持, 并且支持批量计算
-
-
速度
-
在单机上, Storm大概能达到30万条/秒的吞吐量, 这个数据大概是Storm得3-5倍.在阿里中,Flink集群能达到每秒能处理17亿数据量,一天可处理上万亿条数据
-
一天的数据量有多大?(数据的条数/数据占用的磁盘空间)
-
10亿条数据,一条数据1KB 20亿Kb 20 00GMB 6/亿, 400G
-
在单机上, Flink消息处理的延迟大概在200毫秒左右, 这个数据大概是Spark的3-5倍
-
Flink的发展现状
14年Apache立为顶级项目.阿里15年开始使用
-
Flink在很多公司的生产环境中得到了使用, 例如: ebay, 腾讯, 阿里, 亚马逊, 华为等
-
Blink
Flink的母公司被阿里全资收购, 阿里一直致力于Flink在国内的推广使用
Flink的适用场景
-
零售业和市场营销(运营)
-
物联网(5G,无限流量,延迟低/打游戏,无人驾驶)
-
电信业,
-
银行和金融业,
项目外包,人员外包
对比Flink、Spark、Storm
Flink、Spark Streaming、Storm都可以进行实时计算,但各有特点