


网站数据采集|埋点设计|nginx日志文件
数据获取的方式主要可以分为两种:
-
1.网站日志文件(log files)
-
页面埋点js自定义的采集.
优缺点:
- web服务器自带的日志记录功能:优点方便,缺点信息收集不全
- 自定义的js埋点收集:优点想收集啥就收集啥,缺点需要系统的开发部署
1. 网站日志文件
记录网站日志文件的方式是最原始的数据获取方式,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能就能够实现,很多web应用服务器自带日志的记录功能。如Nginx的access.log日志等。
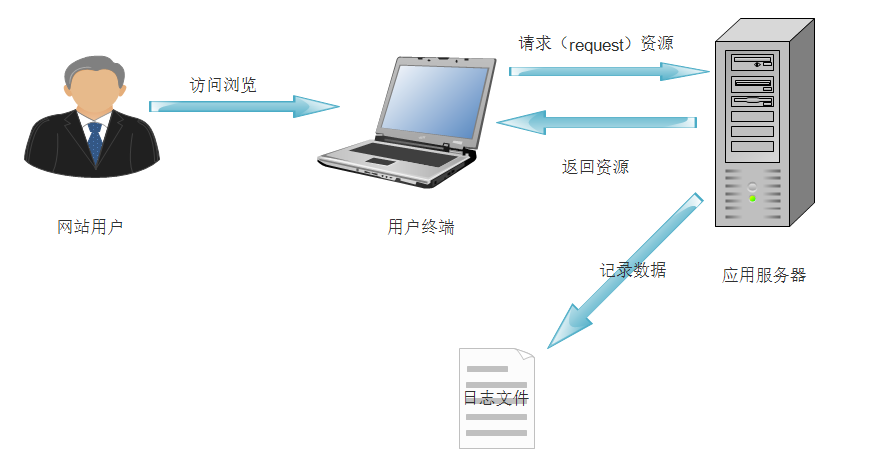
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关请求信息,缺点在于有些信息无法采集,比如用户在页面端的操作(如点击、ajax的使用等)无法记录。限制了一些指标的统计和计算。
2.页面埋点js自定义采集
自定义采集用户行为数据,通过在页面嵌入自定义的javascript代码来获取用户的访问行为(比如鼠标悬停的位置,点击的页面组件等),然后通过ajax请求到后台记录日志,这种方式所能采集的信息会更加全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:
系统特征:比如所采用的操作系统、浏览器、域名和访问速度等。
访问特征:包括停留时间、点击的URL、所点击的“页面标签<a>”及标签的
属性等。
来源特征:包括来访URL,来访IP等。
产品特征:包括所访问的产品编号、产品类别、产品颜色、产品价格、产品利润、产品数量和特价等级等。
以某电商网站为例,当用户点击相关产品页面时,其自定义采集系统就会收集相关的行为数据,发到后端的服务器,收集的数据日志格式如下:
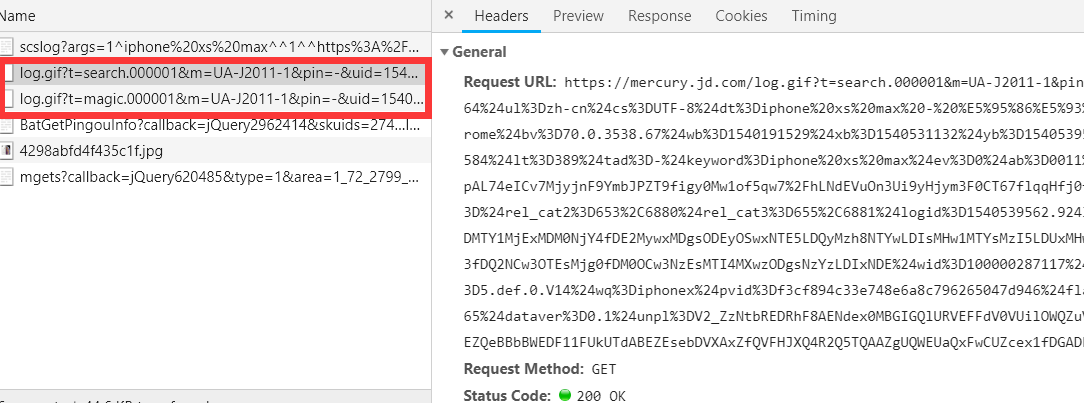
https://mercury.jd.com/log.gif?t=search.000001&m=UA-J2011-1&pin=-&uid=15401915286171416477093&sid=15401915286171416477093|5&v=je=0$sc=24-bit$sr=1536x864$ul=zh-cn$cs=UTF-8$dt=iphone xs max -
商品搜索 - 京东$hn=search.jd.com$fl=-$os=win$br=chrome$bv=70.0.3538.67$wb=1540191529$xb=1540531132$yb=1540539558$zb=5$cb=2$usc=baidu$ucp=-$umd=organic$uct=not set$ct=1540539573584$lt=389$tad=-
$keyword=iphone xs max$ev=0$ab=0011$mtest=group_base,ext_attr_fliter,qpv3,qpt9,qpz7$rel_ver=V0700$sig=80It1J9QZbpAL74eICv7MjyjnF9YmbJPZT9figy0Mw1of5qw7/hLNdEVuOn3Ui9yHjym3F0CT67flqqHfj0fyI08i8pf8Asn+
7thpEDDaJZjrwK/gHpYwQNN2MK6q/GuOZfL8VOsvbLDGo3rpj+R1jMIO4n5hg0Kv6yrwrFLlSA=$rel_cat2=653,6880$rel_cat3=655,6881$logid=1540539562.92430$loc=1-72-2799-

